 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Reinforced Agent for Flexible Exposure Bracketing Selection
May 26, 2020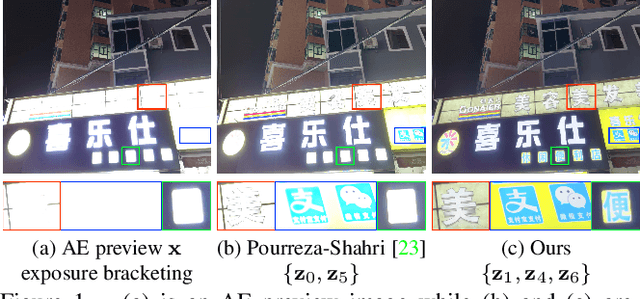



Automatically selecting exposure bracketing (images exposed differently) is important to obtain a high dynamic range image by using multi-exposure fusion. Unlike previous methods that have many restrictions such as requiring camera response function, sensor noise model, and a stream of preview images with different exposures (not accessible in some scenarios e.g. some mobile applications), we propose a novel deep neural network to automatically select exposure bracketing, named EBSNet, which is sufficiently flexible without having the above restrictions. EBSNet is formulated as a reinforced agent that is trained by maximizing rewards provided by a multi-exposure fusion network (MEFNet). By utilizing the illumination and semantic information extracted from just a single auto-exposure preview image, EBSNet can select an optimal exposure bracketing for multi-exposure fusion. EBSNet and MEFNet can be jointly trained to produce favorable results against recent state-of-the-art approaches. To facilitate future research, we provide a new benchmark dataset for multi-exposure selection and fusion.
Generalizing Monocular 3D Human Pose Estimation in the Wild
Apr 11, 2019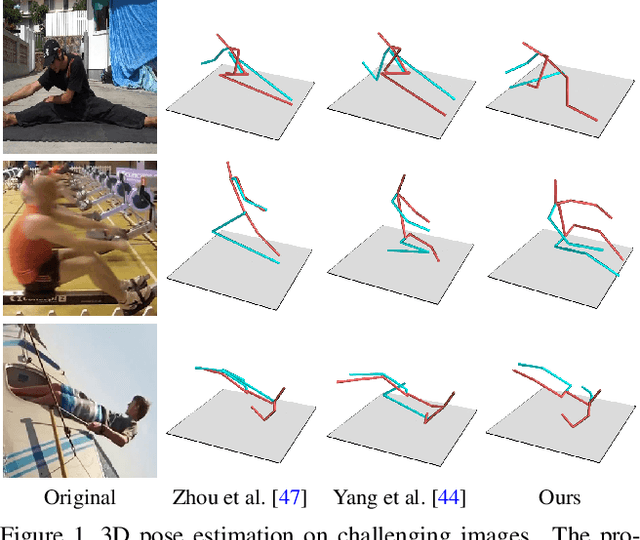
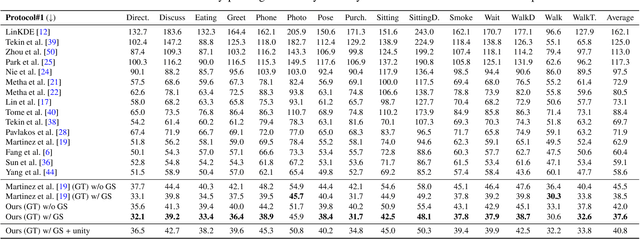
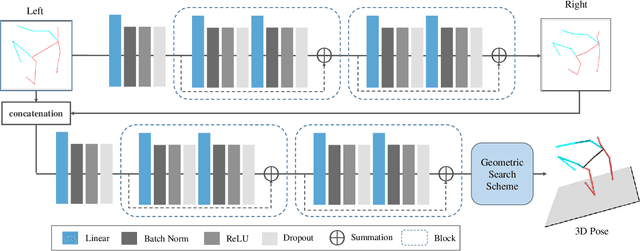

The availability of the large-scale labeled 3D poses in the Human3.6M dataset plays an important role in advancing the algorithms for 3D human pose estimation from a still image. We observe that recent innovation in this area mainly focuses on new techniques that explicitly address the generalization issue when using this dataset, because this database is constructed in a highly controlled environment with limited human subjects and background variations. Despite such efforts, we can show that the results of the current methods are still error-prone especially when tested against the images taken in-the-wild. In this paper, we aim to tackle this problem from a different perspective. We propose a principled approach to generate high quality 3D pose ground truth given any in-the-wild image with a person inside. We achieve this by first devising a novel stereo inspired neural network to directly map any 2D pose to high quality 3D counterpart. We then perform a carefully designed geometric searching scheme to further refine the joints. Based on this scheme, we build a large-scale dataset with 400,000 in-the-wild images and their corresponding 3D pose ground truth. This enables the training of a high quality neural network model, without specialized training scheme and auxiliary loss function, which performs favorably against the state-of-the-art 3D pose estimation methods. We also evaluate the generalization ability of our model both quantitatively and qualitatively. Results show that our approach convincingly outperforms the previous methods. We make our dataset and code publicly available.
Single View Stereo Matching
Mar 09, 2018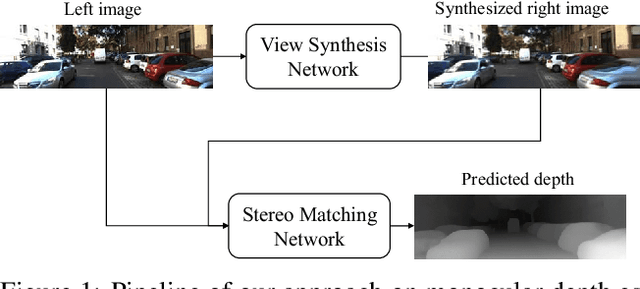
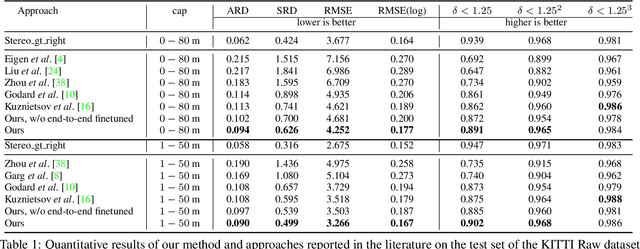

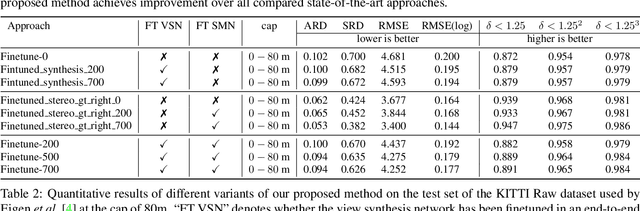
Previous monocular depth estimation methods take a single view and directly regress the expected results. Though recent advances are made by applying geometrically inspired loss functions during training, the inference procedure does not explicitly impose any geometrical constraint. Therefore these models purely rely on the quality of data and the effectiveness of learning to generalize. This either leads to suboptimal results or the demand of huge amount of expensive ground truth labelled data to generate reasonable results. In this paper, we show for the first time that the monocular depth estimation problem can be reformulated as two sub-problems, a view synthesis procedure followed by stereo matching, with two intriguing properties, namely i) geometrical constraints can be explicitly imposed during inference; ii) demand on labelled depth data can be greatly alleviated. We show that the whole pipeline can still be trained in an end-to-end fashion and this new formulation plays a critical role in advancing the performance. The resulting model outperforms all the previous monocular depth estimation methods as well as the stereo block matching method in the challenging KITTI dataset by only using a small number of real training data. The model also generalizes well to other monocular depth estimation benchmarks. We also discuss the implications and the advantages of solving monocular depth estimation using stereo methods.
Recurrent 3D Pose Sequence Machines
Jul 31, 2017

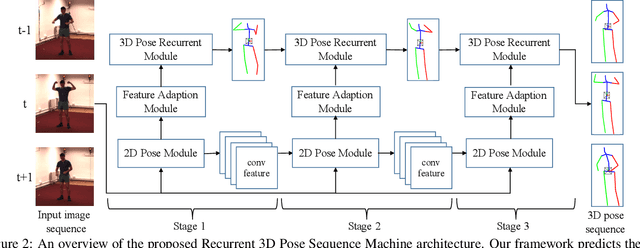

3D human articulated pose recovery from monocular image sequences is very challenging due to the diverse appearances, viewpoints, occlusions, and also the human 3D pose is inherently ambiguous from the monocular imagery. It is thus critical to exploit rich spatial and temporal long-range dependencies among body joints for accurate 3D pose sequence prediction. Existing approaches usually manually design some elaborate prior terms and human body kinematic constraints for capturing structures, which are often insufficient to exploit all intrinsic structures and not scalable for all scenarios. In contrast, this paper presents a Recurrent 3D Pose Sequence Machine(RPSM) to automatically learn the image-dependent structural constraint and sequence-dependent temporal context by using a multi-stage sequential refinement. At each stage, our RPSM is composed of three modules to predict the 3D pose sequences based on the previously learned 2D pose representations and 3D poses: (i) a 2D pose module extracting the image-dependent pose representations, (ii) a 3D pose recurrent module regressing 3D poses and (iii) a feature adaption module serving as a bridge between module (i) and (ii) to enable the representation transformation from 2D to 3D domain. These three modules are then assembled into a sequential prediction framework to refine the predicted poses with multiple recurrent stages. Extensive evaluations on the Human3.6M dataset and HumanEva-I dataset show that our RPSM outperforms all state-of-the-art approaches for 3D pose estimation.
Character Proposal Network for Robust Text Extraction
Feb 13, 2016
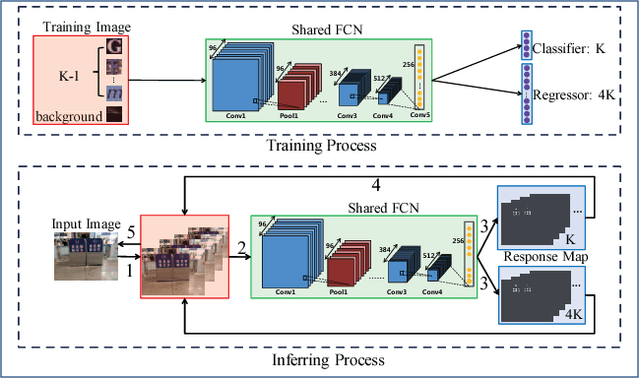

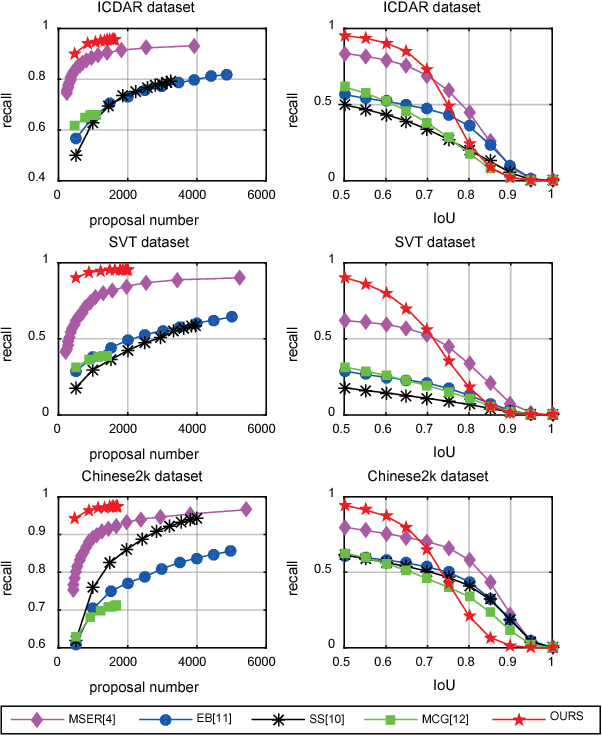
Maximally stable extremal regions (MSER), which is a popular method to generate character proposals/candidates, has shown superior performance in scene text detection. However, the pixel-level operation limits its capability for handling some challenging cases (e.g., multiple connected characters, separated parts of one character and non-uniform illumination). To better tackle these cases, we design a character proposal network (CPN) by taking advantage of the high capacity and fast computing of fully convolutional network (FCN). Specifically, the network simultaneously predicts characterness scores and refines the corresponding locations. The characterness scores can be used for proposal ranking to reject non-character proposals and the refining process aims to obtain the more accurate locations. Furthermore, considering the situation that different characters have different aspect ratios, we propose a multi-template strategy, designing a refiner for each aspect ratio. The extensive experiments indicate our method achieves recall rates of 93.88%, 93.60% and 96.46% on ICDAR 2013, SVT and Chinese2k datasets respectively using less than 1000 proposals, demonstrating promising performance of our character proposal network.