 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Monocular 3D Human Pose Estimation in the Wild
Apr 11, 2019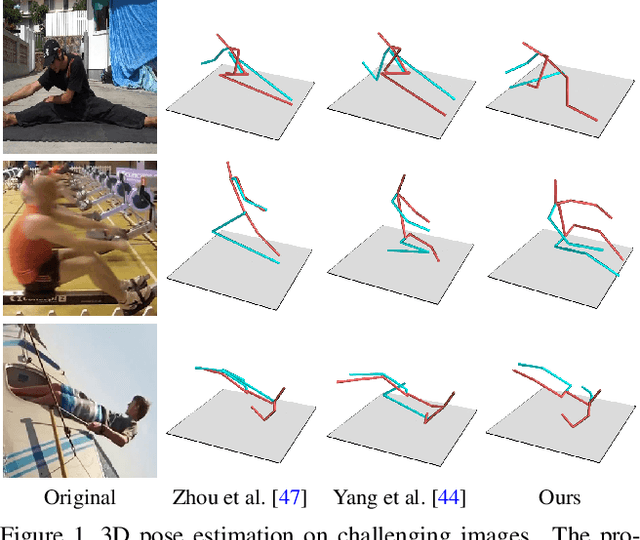
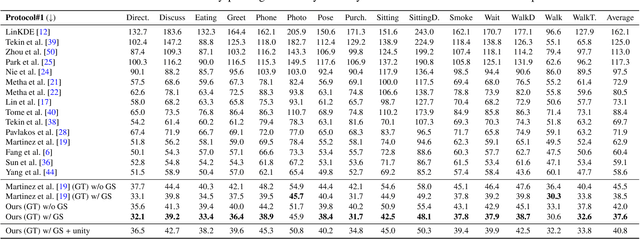
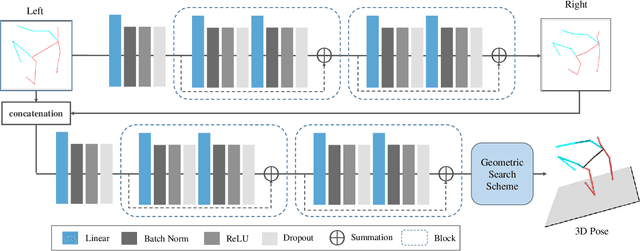

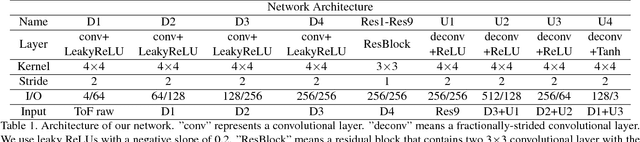
The availability of the large-scale labeled 3D poses in the Human3.6M dataset plays an important role in advancing the algorithms for 3D human pose estimation from a still image. We observe that recent innovation in this area mainly focuses on new techniques that explicitly address the generalization issue when using this dataset, because this database is constructed in a highly controlled environment with limited human subjects and background variations. Despite such efforts, we can show that the results of the current methods are still error-prone especially when tested against the images taken in-the-wild. In this paper, we aim to tackle this problem from a different perspective. We propose a principled approach to generate high quality 3D pose ground truth given any in-the-wild image with a person inside. We achieve this by first devising a novel stereo inspired neural network to directly map any 2D pose to high quality 3D counterpart. We then perform a carefully designed geometric searching scheme to further refine the joints. Based on this scheme, we build a large-scale dataset with 400,000 in-the-wild images and their corresponding 3D pose ground truth. This enables the training of a high quality neural network model, without specialized training scheme and auxiliary loss function, which performs favorably against the state-of-the-art 3D pose estimation methods. We also evaluate the generalization ability of our model both quantitatively and qualitatively. Results show that our approach convincingly outperforms the previous methods. We make our dataset and code publicly available.
Very Power Efficient Neural Time-of-Flight
Dec 19, 2018
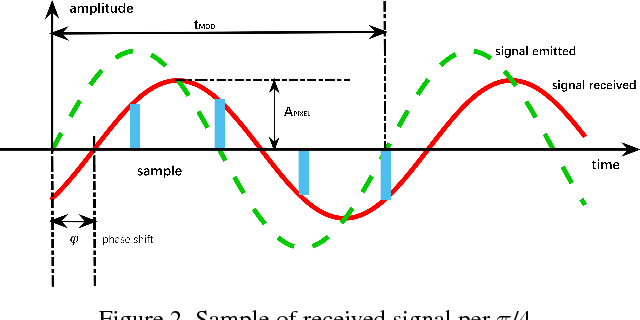
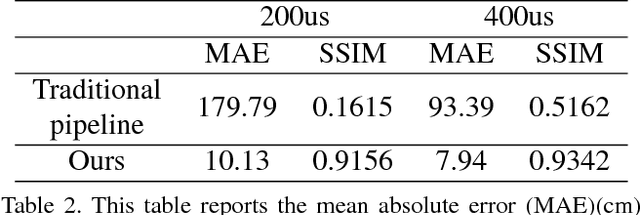
Time-of-Flight (ToF) cameras require active illumination to obtain depth information thus the power of illumination directly affects the performance of ToF cameras. Traditional ToF imaging algorithms is very sensitive to illumination and the depth accuracy degenerates rapidly with the power of it. Therefore, the design of a power efficient ToF camera always creates a painful dilemma for the illumination and the performance trade-off. In this paper, we show that despite the weak signals in many areas under extreme short exposure setting, these signals as a whole can be well utilized through a learning process which directly translates the weak and noisy ToF camera raw to depth map. This creates an opportunity to tackle the aforementioned dilemma and make a very power efficient ToF camera possible. To enable the learning, we collect a comprehensive dataset under a variety of scenes and photographic conditions by a specialized ToF camera. Experiments show that our method is able to robustly process ToF camera raw with the exposure time of one order of magnitude shorter than that used in conventional ToF cameras. In addition to evaluating our approach both quantitatively and qualitatively, we also discuss its implication to designing the next generation power efficient ToF cameras. We will make our dataset and code publicly available.