 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Intensity-Event Stereo Matching
Nov 01, 2022
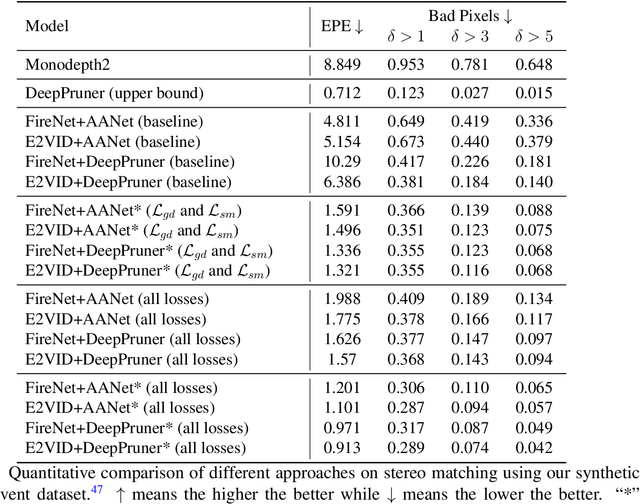
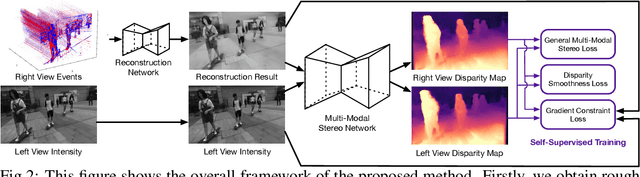
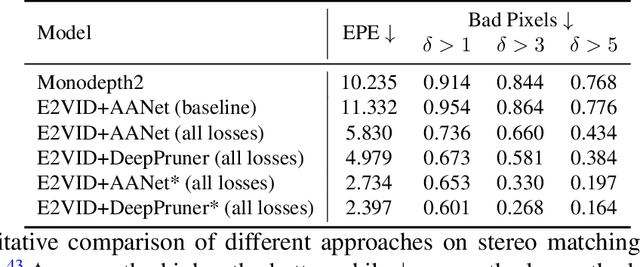
Event cameras are novel bio-inspired vision sensors that output pixel-level intensity changes in microsecond accuracy with a high dynamic range and low power consumption. Despite these advantages, event cameras cannot be directly applied to computational imaging tasks due to the inability to obtain high-quality intensity and events simultaneously. This paper aims to connect a standalone event camera and a modern intensity camera so that the applications can take advantage of both two sensors. We establish this connection through a multi-modal stereo matching task. We first convert events to a reconstructed image and extend the existing stereo networks to this multi-modality condition. We propose a self-supervised method to train the multi-modal stereo network without using ground truth disparity data. The structure loss calculated on image gradients is used to enable self-supervised learning on such multi-modal data. Exploiting the internal stereo constraint between views with different modalities, we introduce general stereo loss functions, including disparity cross-consistency loss and internal disparity loss, leading to improved performance and robustness compared to existing approaches. The experiments demonstrate the effectiveness of the proposed method, especially the proposed general stereo loss functions, on both synthetic and real datasets. At last, we shed light on employing the aligned events and intensity images in downstream tasks, e.g., video interpolation application.
Efficient Deep Image Denoising via Class Specific Convolution
Mar 02, 2021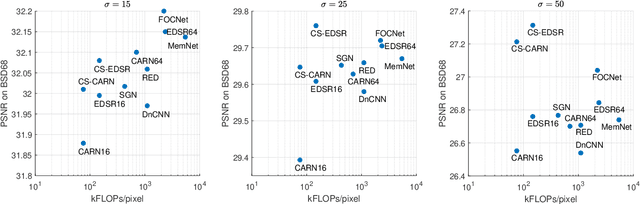
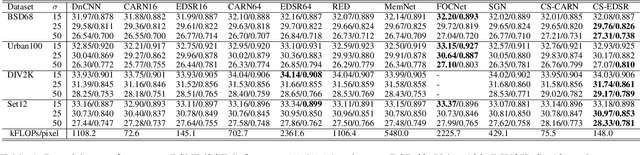
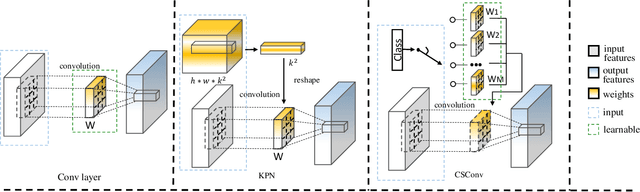

Deep neural networks have been widely used in image denoising during the past few years. Even though they achieve great success on this problem, they are computationally inefficient which makes them inappropriate to be implemented in mobile devices. In this paper, we propose an efficient deep neural network for image denoising based on pixel-wise classification. Despite using a computationally efficient network cannot effectively remove the noises from any content, it is still capable to denoise from a specific type of pattern or texture. The proposed method follows such a divide and conquer scheme. We first use an efficient U-net to pixel-wisely classify pixels in the noisy image based on the local gradient statistics. Then we replace part of the convolution layers in existing denoising networks by the proposed Class Specific Convolution layers (CSConv) which use different weights for different classes of pixels. Quantitative and qualitative evaluations on public datasets demonstrate that the proposed method can reduce the computational costs without sacrificing the performance compared to state-of-the-art algorithms.
Very Power Efficient Neural Time-of-Flight
Dec 19, 2018
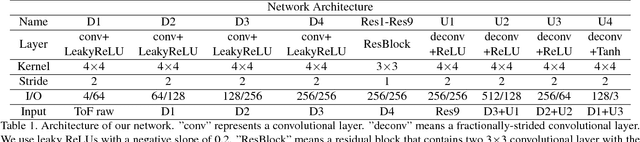
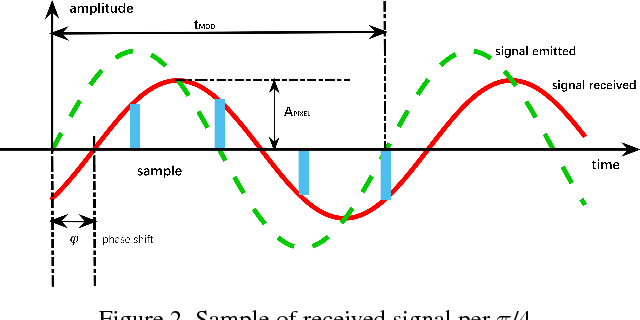
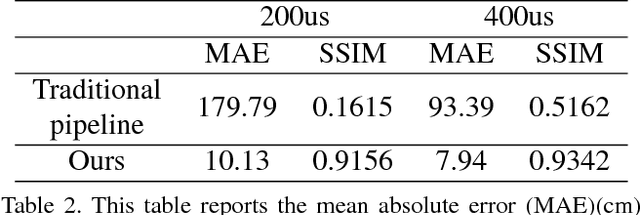
Time-of-Flight (ToF) cameras require active illumination to obtain depth information thus the power of illumination directly affects the performance of ToF cameras. Traditional ToF imaging algorithms is very sensitive to illumination and the depth accuracy degenerates rapidly with the power of it. Therefore, the design of a power efficient ToF camera always creates a painful dilemma for the illumination and the performance trade-off. In this paper, we show that despite the weak signals in many areas under extreme short exposure setting, these signals as a whole can be well utilized through a learning process which directly translates the weak and noisy ToF camera raw to depth map. This creates an opportunity to tackle the aforementioned dilemma and make a very power efficient ToF camera possible. To enable the learning, we collect a comprehensive dataset under a variety of scenes and photographic conditions by a specialized ToF camera. Experiments show that our method is able to robustly process ToF camera raw with the exposure time of one order of magnitude shorter than that used in conventional ToF cameras. In addition to evaluating our approach both quantitatively and qualitatively, we also discuss its implication to designing the next generation power efficient ToF cameras. We will make our dataset and code publicly available.