 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHi-Reco: High-Fidelity Real-Time Conversational Digital Humans
Nov 16, 2025High-fidelity digital humans are increasingly used in interactive applications, yet achieving both visual realism and real-time responsiveness remains a major challenge. We present a high-fidelity, real-time conversational digital human system that seamlessly combines a visually realistic 3D avatar, persona-driven expressive speech synthesis, and knowledge-grounded dialogue generation. To support natural and timely interaction, we introduce an asynchronous execution pipeline that coordinates multi-modal components with minimal latency. The system supports advanced features such as wake word detection, emotionally expressive prosody, and highly accurate, context-aware response generation. It leverages novel retrieval-augmented methods, including history augmentation to maintain conversational flow and intent-based routing for efficient knowledge access. Together, these components form an integrated system that enables responsive and believable digital humans, suitable for immersive applications in communication, education, and entertainment.
Assessing Alcohol Use Disorder: Insights from Lifestyle, Background, and Family History with Machine Learning Techniques
Oct 24, 2024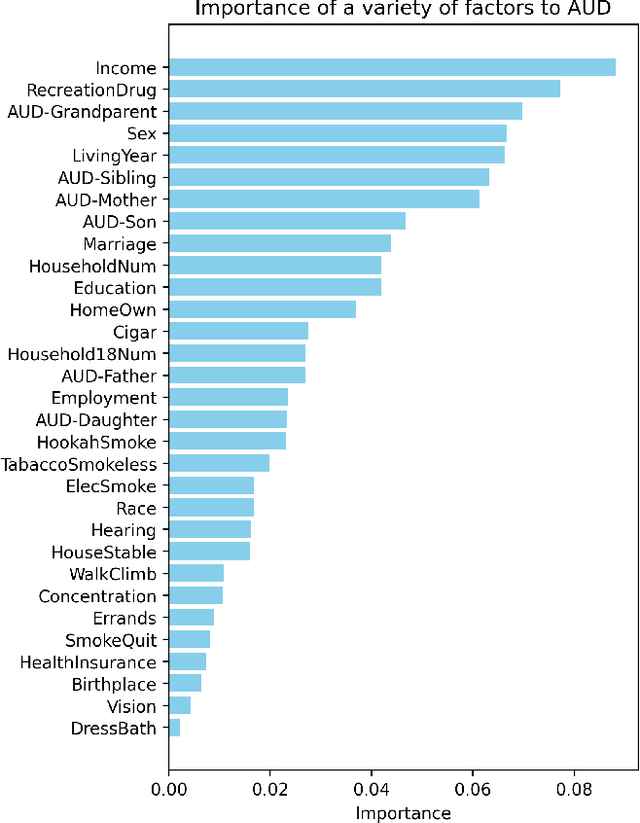
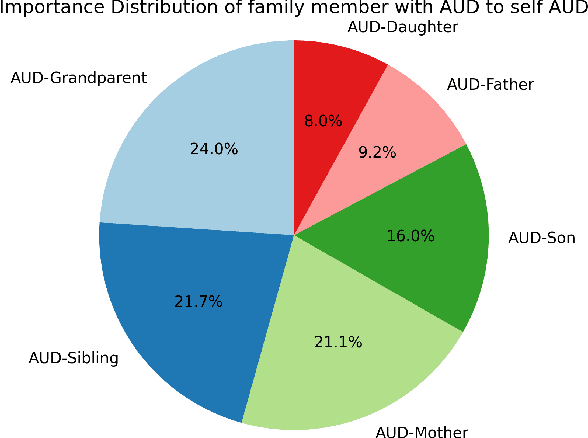


This study explored how lifestyle, personal background, and family history contribute to the risk of developing Alcohol Use Disorder (AUD). Survey data from the All of Us Program was utilized to extract information on AUD status, lifestyle, personal background, and family history for 6,016 participants. Key determinants of AUD were identified using decision trees including annual income, recreational drug use, length of residence, sex/gender, marital status, education level, and family history of AUD. Data visualization and Chi-Square Tests of Independence were then used to assess associations between identified factors and AUD. Afterwards, machine learning techniques including decision trees, random forests, and Naive Bayes were applied to predict an individual's likelihood of developing AUD. Random forests were found to achieve the highest accuracy (82%), compared to Decision Trees and Naive Bayes. Findings from this study can offer insights that help parents, healthcare professionals, and educators develop strategies to reduce AUD risk, enabling early intervention and targeted prevention efforts.
Single View Stereo Matching
Mar 09, 2018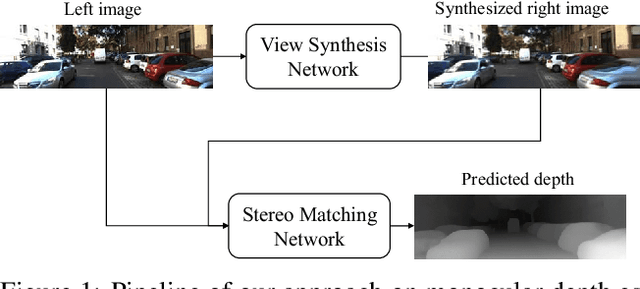
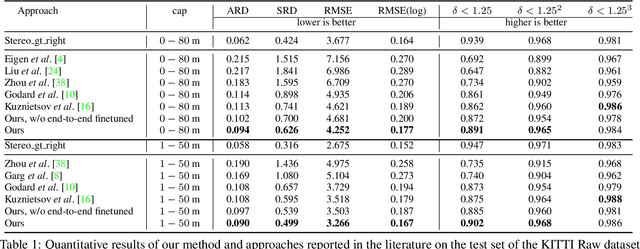

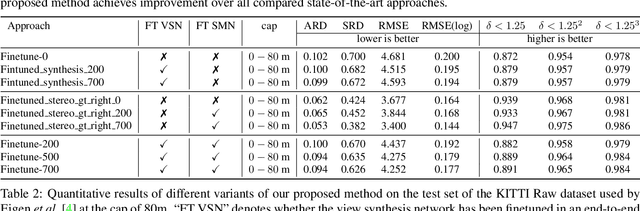
Previous monocular depth estimation methods take a single view and directly regress the expected results. Though recent advances are made by applying geometrically inspired loss functions during training, the inference procedure does not explicitly impose any geometrical constraint. Therefore these models purely rely on the quality of data and the effectiveness of learning to generalize. This either leads to suboptimal results or the demand of huge amount of expensive ground truth labelled data to generate reasonable results. In this paper, we show for the first time that the monocular depth estimation problem can be reformulated as two sub-problems, a view synthesis procedure followed by stereo matching, with two intriguing properties, namely i) geometrical constraints can be explicitly imposed during inference; ii) demand on labelled depth data can be greatly alleviated. We show that the whole pipeline can still be trained in an end-to-end fashion and this new formulation plays a critical role in advancing the performance. The resulting model outperforms all the previous monocular depth estimation methods as well as the stereo block matching method in the challenging KITTI dataset by only using a small number of real training data. The model also generalizes well to other monocular depth estimation benchmarks. We also discuss the implications and the advantages of solving monocular depth estimation using stereo methods.
LSTM Pose Machines
Mar 09, 2018

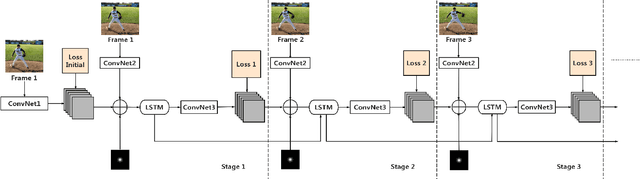

We observed that recent state-of-the-art results on single image human pose estimation were achieved by multi-stage Convolution Neural Networks (CNN). Notwithstanding the superior performance on static images, the application of these models on videos is not only computationally intensive, it also suffers from performance degeneration and flicking. Such suboptimal results are mainly attributed to the inability of imposing sequential geometric consistency, handling severe image quality degradation (e.g. motion blur and occlusion) as well as the inability of capturing the temporal correlation among video frames. In this paper, we proposed a novel recurrent network to tackle these problems. We showed that if we were to impose the weight sharing scheme to the multi-stage CNN, it could be re-written as a Recurrent Neural Network (RNN). This property decouples the relationship among multiple network stages and results in significantly faster speed in invoking the network for videos. It also enables the adoption of Long Short-Term Memory (LSTM) units between video frames. We found such memory augmented RNN is very effective in imposing geometric consistency among frames. It also well handles input quality degradation in videos while successfully stabilizes the sequential outputs. The experiments showed that our approach significantly outperformed current state-of-the-art methods on two large-scale video pose estimation benchmarks. We also explored the memory cells inside the LSTM and provided insights on why such mechanism would benefit the prediction for video-based pose estimations.