 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbon Footprint Accounting Driven by Large Language Models and Retrieval-augmented Generation
Aug 20, 2024Carbon footprint accounting is crucial for quantifying greenhouse gas emissions and achieving carbon neutrality.The dynamic nature of processes, accounting rules, carbon-related policies, and energy supply structures necessitates real-time updates of CFA. Traditional life cycle assessment methods rely heavily on human expertise, making near-real-time updates challenging. This paper introduces a novel approach integrating large language models (LLMs) with retrieval-augmented generation technology to enhance the real-time, professional, and economical aspects of carbon footprint information retrieval and analysis. By leveraging LLMs' logical and language understanding abilities and RAG's efficient retrieval capabilities, the proposed method LLMs-RAG-CFA can retrieve more relevant professional information to assist LLMs, enhancing the model's generative abilities. This method offers broad professional coverage, efficient real-time carbon footprint information acquisition and accounting, and cost-effective automation without frequent LLMs' parameter updates. Experimental results across five industries(primary aluminum, lithium battery, photovoltaic, new energy vehicles, and transformers)demonstrate that the LLMs-RAG-CFA method outperforms traditional methods and other LLMs, achieving higher information retrieval rates and significantly lower information deviations and carbon footprint accounting deviations. The economically viable design utilizes RAG technology to balance real-time updates with cost-effectiveness, providing an efficient, reliable, and cost-saving solution for real-time carbon emission management, thereby enhancing environmental sustainability practices.
Fed-NILM: A Federated Learning-based Non-Intrusive Load Monitoring Method for Privacy-Protection
May 24, 2021
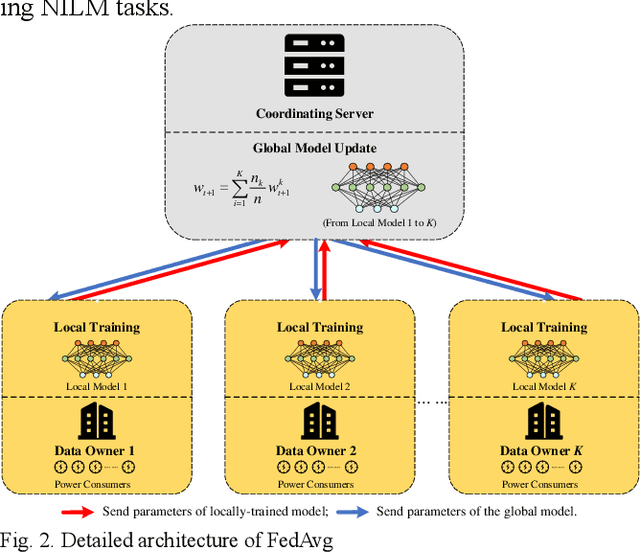
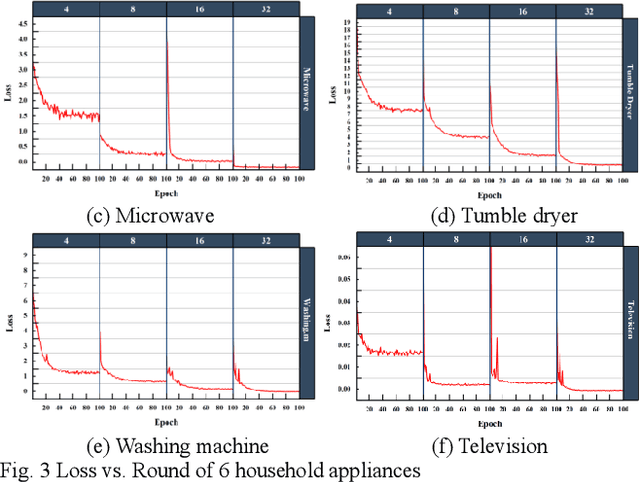
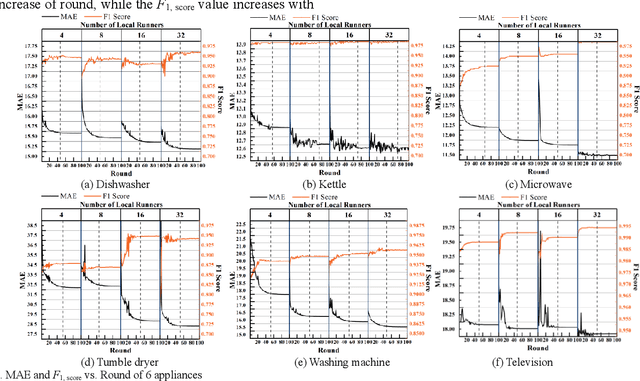
Non-intrusive load monitoring (NILM) decomposes the total load reading into appliance-level load signals. Many deep learning-based methods have been developed to accomplish NILM, and the training of deep neural networks (DNN) requires massive load data containing different types of appliances. For local data owners with inadequate load data but expect to accomplish a promising model performance, the conduction of effective NILM co-modelling is increasingly significant. While during the cooperation of local data owners, data exchange and centralized data storage may increase the risk of power consumer privacy breaches. To eliminate the potential risks, a novel NILM method named Fed-NILM ap-plying Federated Learning (FL) is proposed in this paper. In Fed-NILM, local parameters instead of load data are shared among local data owners. The global model is obtained by weighted averaging the parameters. In the experiments, Fed-NILM is validated on two real-world datasets. Besides, a comparison of Fed-NILM with locally-trained NILMs and the centrally-trained one is conducted in both residential and industrial scenarios. The experimental results show that Fed-NILM outperforms locally-trained NILMs and approximate the centrally-trained NILM which is trained on the entire load dataset without privacy preservation.
A Federated Learning Framework for Non-Intrusive Load Monitoring
Apr 04, 2021
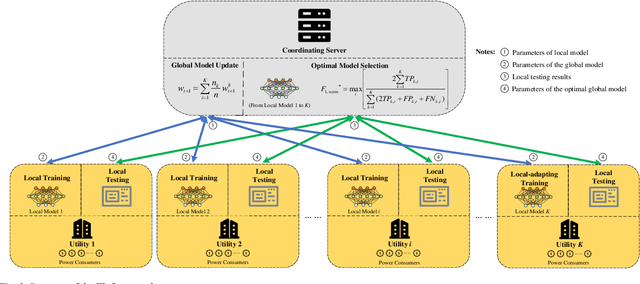
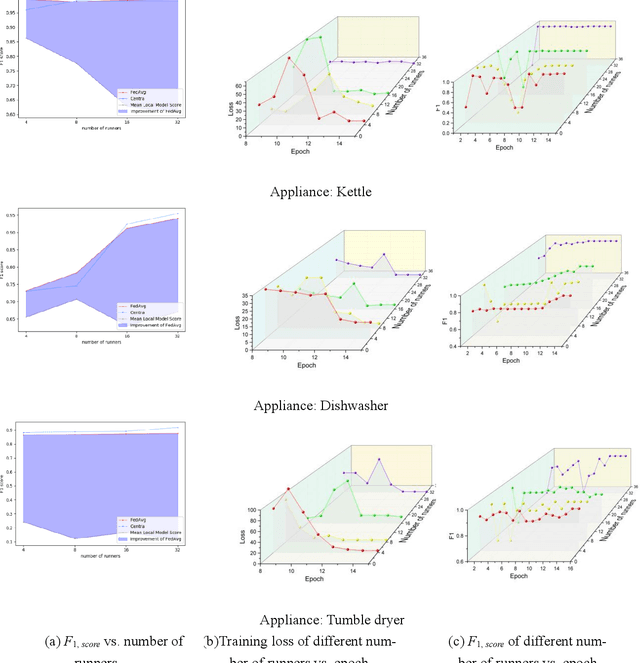
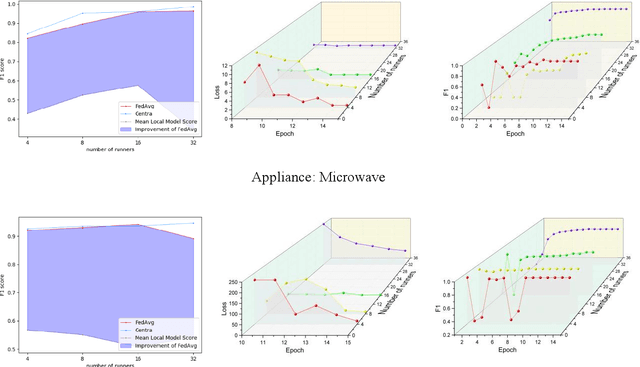
Non-intrusive load monitoring (NILM) aims at decomposing the total reading of the household power consumption into appliance-wise ones, which is beneficial for consumer behavior analysis as well as energy conservation. NILM based on deep learning has been a focus of research. To train a better neural network, it is necessary for the network to be fed with massive data containing various appliances and reflecting consumer behavior habits. Therefore, data cooperation among utilities and DNOs (distributed network operators) who own the NILM data has been increasingly significant. During the cooperation, however, risks of consumer privacy leakage and losses of data control rights arise. To deal with the problems above, a framework to improve the performance of NILM with federated learning (FL) has been set up. In the framework, model weights instead of the local data are shared among utilities. The global model is generated by weighted averaging the locally-trained model weights to gather the locally-trained model information. Optimal model selection help choose the model which adapts to the data from different domains best. Experiments show that this proposal improves the performance of local NILM runners. The performance of this framework is close to that of the centrally-trained model obtained by the convergent data without privacy protection.
Rethinking Convolutional Features in Correlation Filter Based Tracking
Dec 30, 2019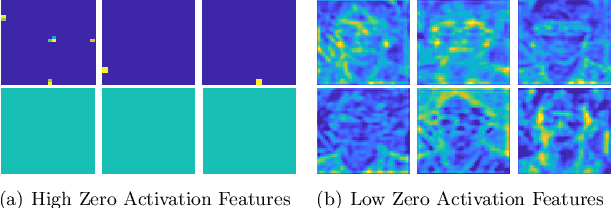

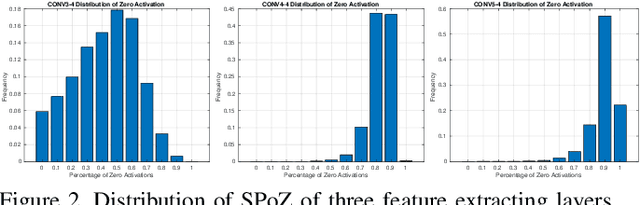
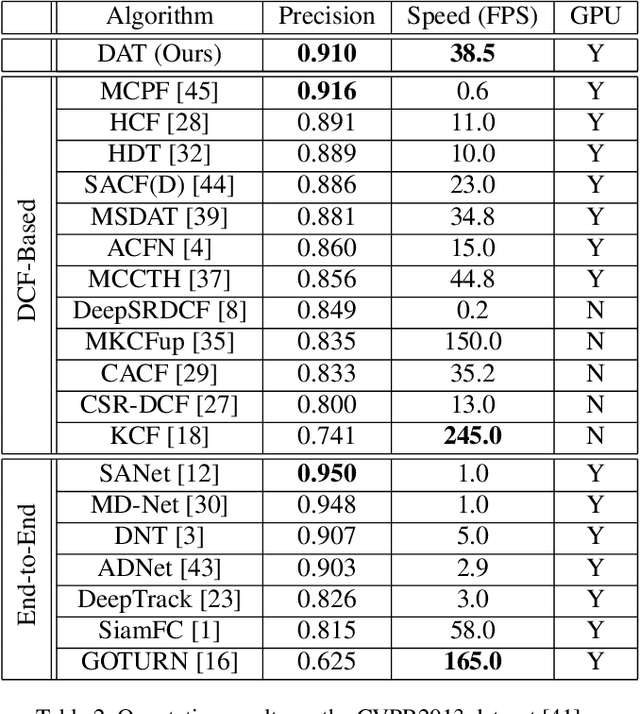
Both accuracy and efficiency are of significant importance to the task of visual object tracking. In recent years, as the surge of deep learning, Deep Convolutional NeuralNetwork (DCNN) becomes a very popular choice among the tracking community. However, due to the high computational complexity, end-to-end visual object trackers can hardly achieve an acceptable inference time and therefore can difficult to be utilized in many real-world applications. In this paper, we revisit a hierarchical deep feature-based visual tracker and found that both the performance and efficiency of the deep tracker are limited by the poor feature quality. Therefore, we propose a feature selection module to select more discriminative features for the trackers. After removing redundant features, our proposed tracker achieves significant improvements in both performance and efficiency. Finally, comparisons with state-of-the-art trackers are provided.