 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetentive Neural Quantum States: Efficient Ansätze for Ab Initio Quantum Chemistry
Paper and Code
Nov 06, 2024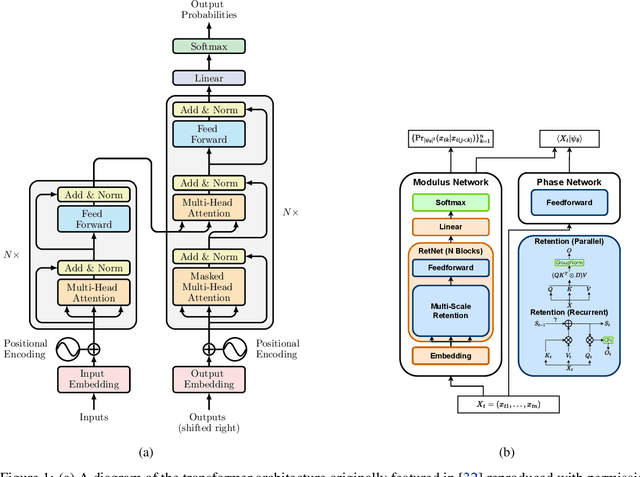

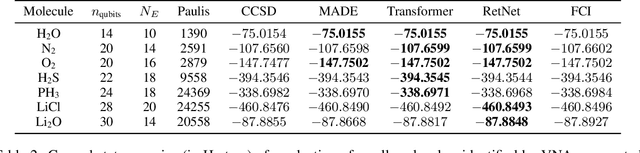
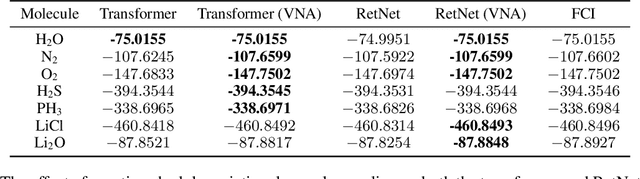
Neural-network quantum states (NQS) has emerged as a powerful application of quantum-inspired deep learning for variational Monte Carlo methods, offering a competitive alternative to existing techniques for identifying ground states of quantum problems. A significant advancement toward improving the practical scalability of NQS has been the incorporation of autoregressive models, most recently transformers, as variational ansatze. Transformers learn sequence information with greater expressiveness than recurrent models, but at the cost of increased time complexity with respect to sequence length. We explore the use of the retentive network (RetNet), a recurrent alternative to transformers, as an ansatz for solving electronic ground state problems in $\textit{ab initio}$ quantum chemistry. Unlike transformers, RetNets overcome this time complexity bottleneck by processing data in parallel during training, and recurrently during inference. We give a simple computational cost estimate of the RetNet and directly compare it with similar estimates for transformers, establishing a clear threshold ratio of problem-to-model size past which the RetNet's time complexity outperforms that of the transformer. Though this efficiency can comes at the expense of decreased expressiveness relative to the transformer, we overcome this gap through training strategies that leverage the autoregressive structure of the model -- namely, variational neural annealing. Our findings support the RetNet as a means of improving the time complexity of NQS without sacrificing accuracy. We provide further evidence that the ablative improvements of neural annealing extend beyond the RetNet architecture, suggesting it would serve as an effective general training strategy for autoregressive NQS.