 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Assessment of Dialog Evaluation Metrics
Paper and Code
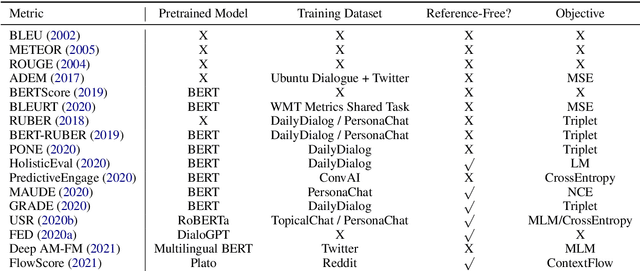
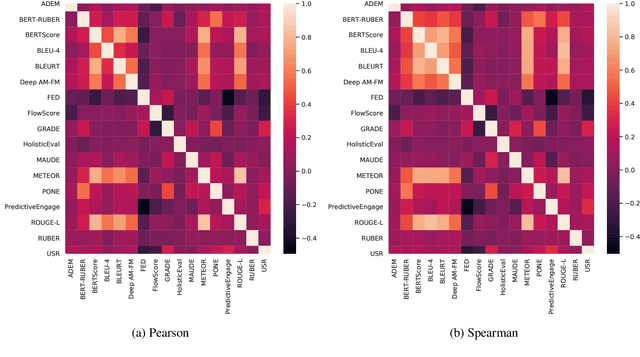

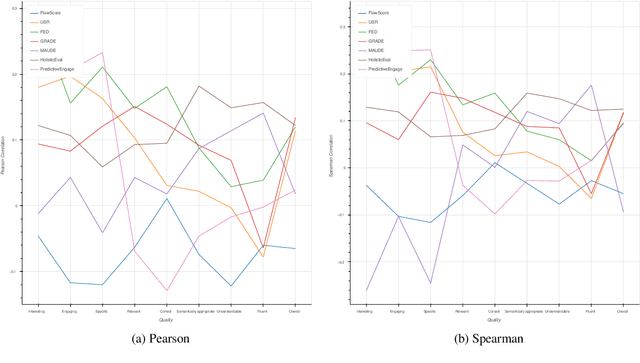
Automatic evaluation metrics are a crucial component of dialog systems research. Standard language evaluation metrics are known to be ineffective for evaluating dialog. As such, recent research has proposed a number of novel, dialog-specific metrics that correlate better with human judgements. Due to the fast pace of research, many of these metrics have been assessed on different datasets and there has as yet been no time for a systematic comparison between them. To this end, this paper provides a comprehensive assessment of recently proposed dialog evaluation metrics on a number of datasets. In this paper, 17 different automatic evaluation metrics are evaluated on 10 different datasets. Furthermore, the metrics are assessed in different settings, to better qualify their respective strengths and weaknesses. Metrics are assessed (1) on both the turn level and the dialog level, (2) for different dialog lengths, (3) for different dialog qualities (e.g., coherence, engaging), (4) for different types of response generation models (i.e., generative, retrieval, simple models and state-of-the-art models), (5) taking into account the similarity of different metrics and (6) exploring combinations of different metrics. This comprehensive assessment offers several takeaways pertaining to dialog evaluation metrics in general. It also suggests how to best assess evaluation metrics and indicates promising directions for future work.