 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMajor Cooperative Transitions and Management Theory in the Game of Life
Apr 02, 2021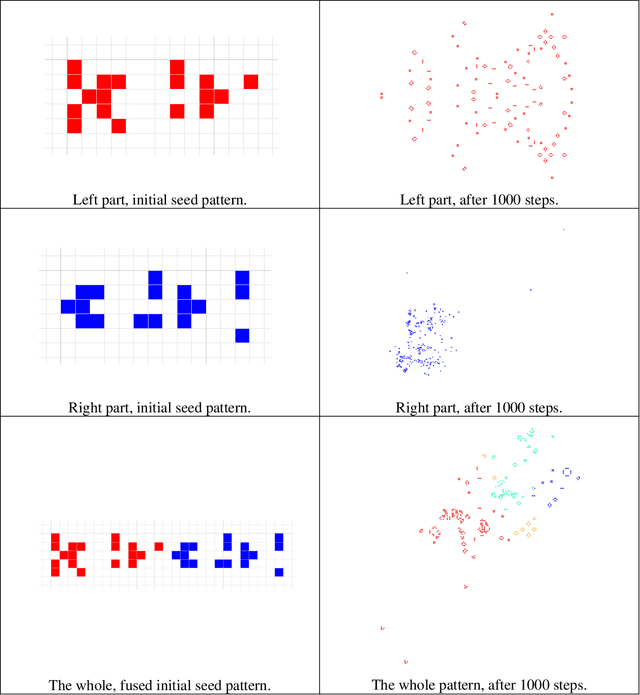

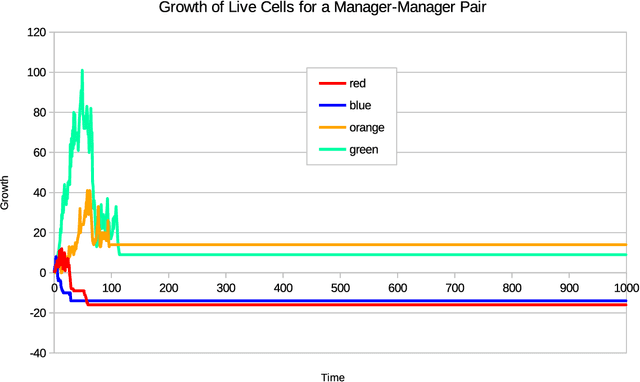

Biological and cultural evolution show a trend towards increasing hierarchical organization, in which entities at one level combine cooperatively to form a new entity at a higher level of organization. In each case where such a cooperative transition has been studied, we have some understanding of how the transition came about, but it is difficult to formulate a unified theory that covers all of these transitions. John Stewart has proposed a theoretical framework called Management Theory, which attempts to explain all of the major cooperative transitions in biological and cultural evolution. The idea is that successful transitions require the integration of managers and workers into a cooperative organization. This theory seems appropriate when we consider the cultural evolution of corporations, where managers and workers are clearly essential, but it seems less plausible when we consider the biological evolution of entities that do not invite anthropomorphic projection. However, in the following article, we define managers and workers in an abstract way that enables us to apply these terms over a broad range of cases, including cultural evolution, biological evolution, and computational simulations of evolution. The core idea is that a worker is an entity that takes the main role in the production of something and a manager is an entity that plays a supporting role in the production of something. We apply this abstract view of managers and workers to a computational simulation of evolving cooperative transitions in John Conway's Game of Life. The simulation confirms the expectations of Management Theory: Manager-worker relations result in robust and productive cooperation, whereas workers without managers tend to lack robustness, and managers without workers tend to lack productivity.
What Makes the Game of Life Special?
Oct 16, 2020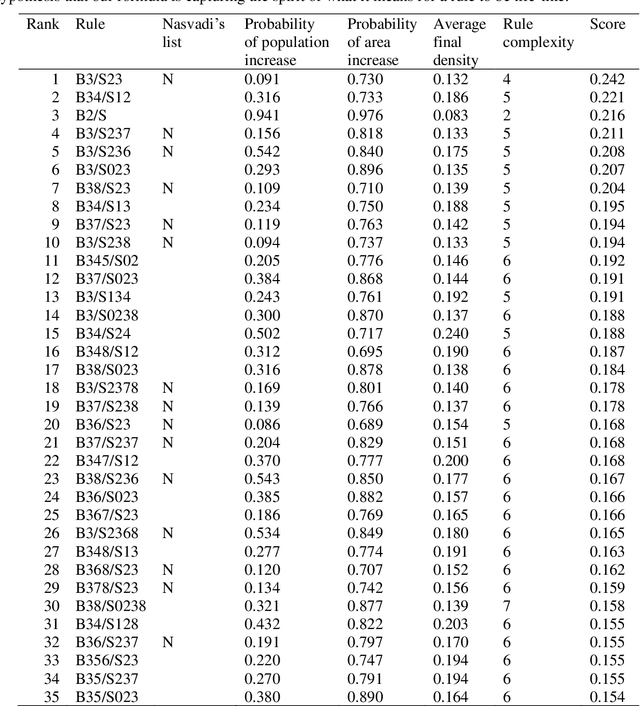
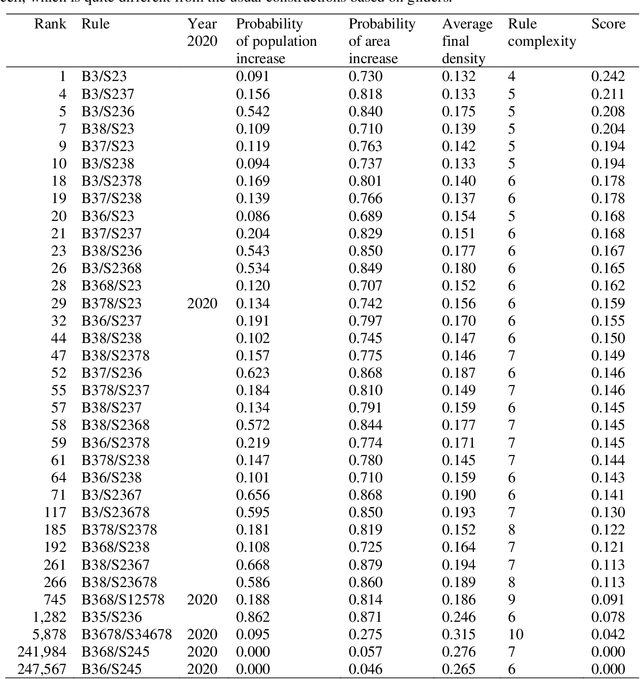
Conway's Game of Life (GoL) is the best-known cellular automaton. It is a classic model of emergence and self-organization, it is Turing-complete, and it can simulate a universal constructor. GoL belongs to the set of semi-totalistic cellular automata, a family with 262,144 members. In such a large family, what makes GoL stand out? Packard and Wolfram (1985) proposed a set of four qualitative classes for cellular automata. Eppstein (2010) proposed four objective classes. Both classification systems are interesting, but neither can distinguish GoL from its many near relatives. Instead of a classification system, we present a simple and objective metric that assigns a numerical score to all semi-totalistic cellular automata. The metric uses four properties to distinguish GoL from its relatives: GoL is evenly balanced between growth and decay, measured by (1) the number of living cells and (2) the area covered by the living cells; (3) the rule for GoL is simple; and (4) GoL has low density, measured by living cells per area. We combine these four properties in a simple mathematical expression. When we score the 262,144 semi-totalistic cellular automata with this formula, GoL achieves the maximum score. We show that the metric favours Turing-complete automata, although it was not designed to do so, which suggests it captures the spirit of the Game of Life.
Evolution, Symbiosis, and Autopoiesis in the Game of Life
Sep 23, 2020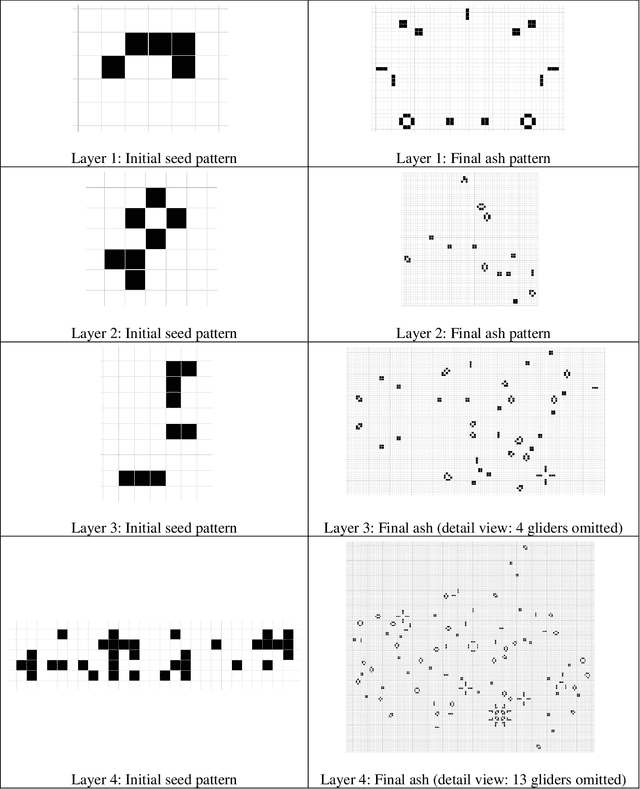
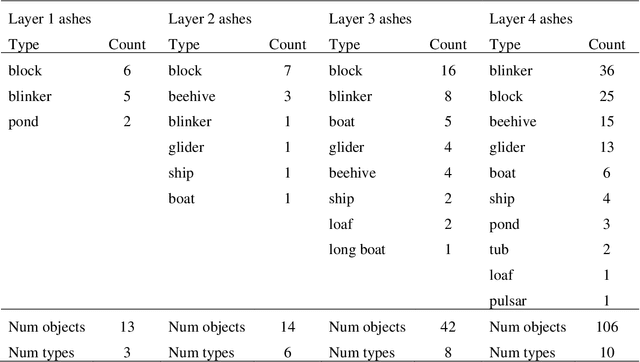
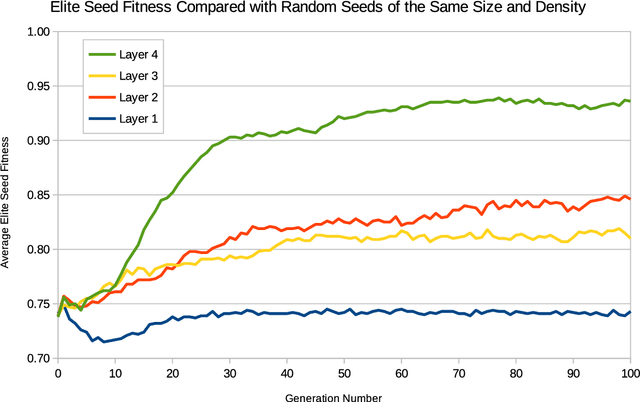
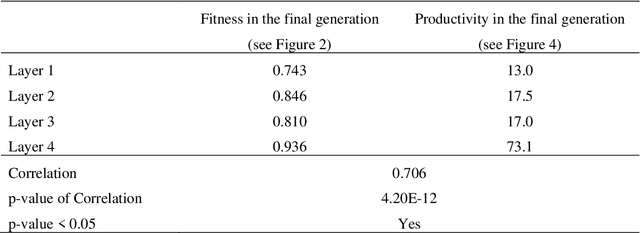
Recently we introduced a model of symbiosis, Model-S, based on the evolution of seed patterns in Conway's Game of Life. In the model, the fitness of a seed pattern is measured by one-on-one competitions in the Immigration Game, a two-player variation of the Game of Life. This article examines the role of autopoiesis in determining fitness in Model-S. We connect our research on evolution, symbiosis, and autopoiesis with research on soups in the Game of Life community. A soup is a random initial pattern in a cellular automaton, such as the Game of Life. When a game begins, there is usually a flare of rapid change in the soup, resembling a fire spreading through a forest. Eventually the fire burns down and the remaining patterns are called ash. Ashes are stable, oscillating, and flying patterns, studied intensively by the Game of Life community for insights into the game. Ashes are instances of autopoietic structures. We use the apgsearch software (Ash Pattern Generator Search), developed for the study of ash, to analyze autopoiesis in Model-S. We find that the fitness of evolved seed patterns in Model-S is highly correlated with the diversity and quantity of autopoietic structures (ash).
Conditions for Open-Ended Evolution in Immigration Games
Apr 06, 2020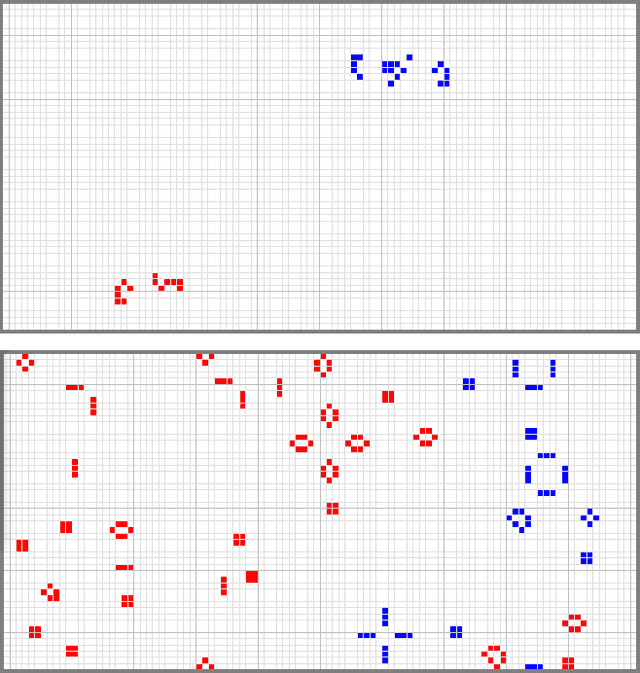
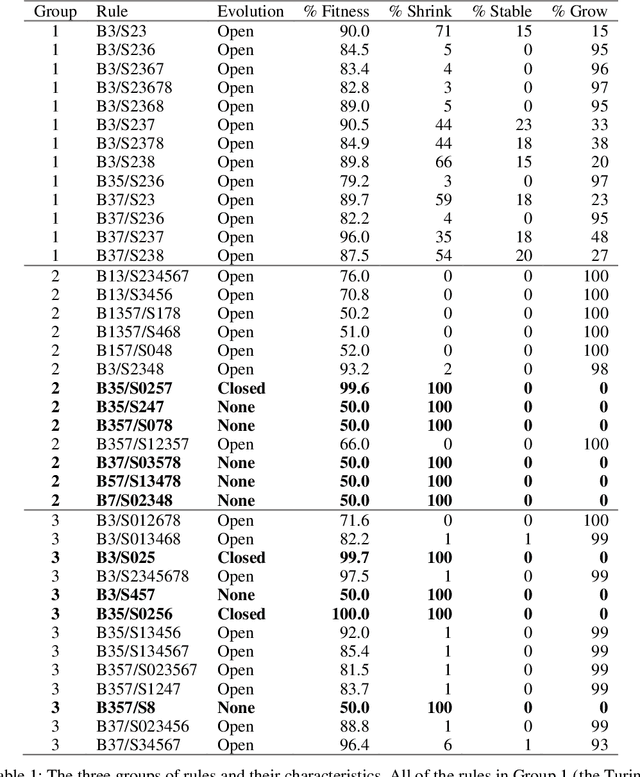
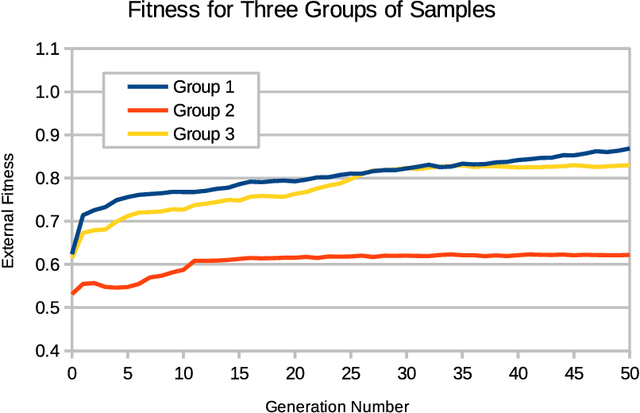
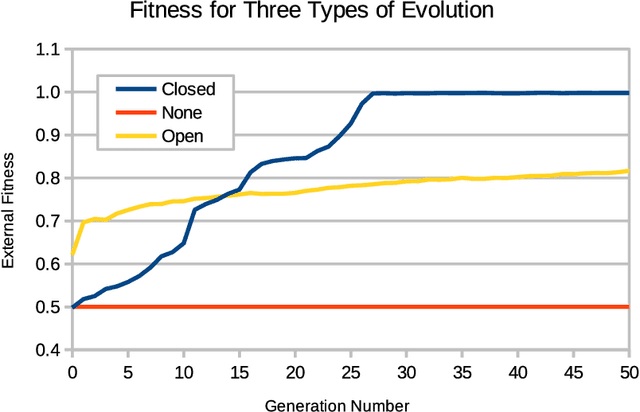
The Immigration Game (invented by Don Woods in 1971) extends the solitaire Game of Life (invented by John Conway in 1970) to enable two-player competition. The Immigration Game can be used in a model of evolution by natural selection, where fitness is measured with competitions. The rules for the Game of Life belong to the family of semitotalistic rules, a family with 262,144 members. Woods' method for converting the Game of Life into a two-player game generalizes to 8,192 members of the family of semitotalistic rules. In this paper, we call the original Immigration Game the Life Immigration Game and we call the 8,192 generalizations Immigration Games (including the Life Immigration Game). The question we examine here is, what are the conditions for one of the 8,192 Immigration Games to be suitable for modeling open-ended evolution? Our focus here is specifically on conditions for the rules, as opposed to conditions for other aspects of the model of evolution. In previous work, it was conjectured that Turing-completeness of the rules for the Game of Life may have been necessary for the success of evolution using the Life Immigration Game. Here we present evidence that Turing-completeness is a sufficient condition on the rules of Immigration Games, but not a necessary condition. The evidence suggests that a necessary and sufficient condition on the rules of Immigration Games, for open-ended evolution, is that the rules should allow growth.
Modeling Major Transitions in Evolution with the Game of Life
Aug 19, 2019
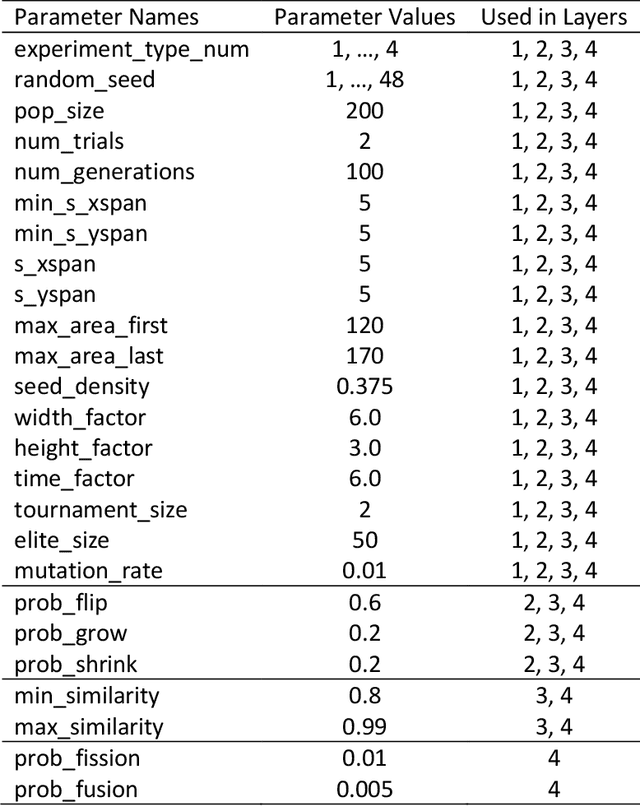
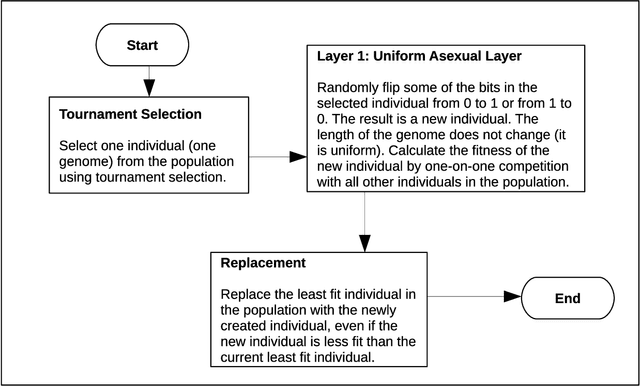
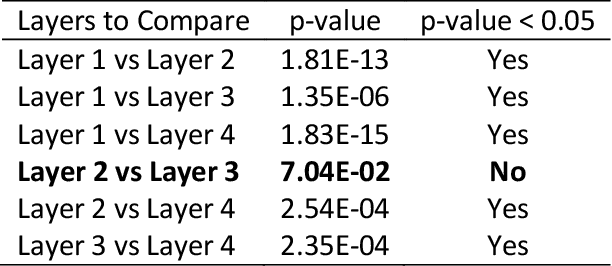
Maynard Smith and Szathm\'ary's book, The Major Transitions in Evolution, describes eight major events in the evolution of life on Earth and identifies a common theme that unites these events. In each event, smaller entities came together to form larger entities, which can be described as symbiosis or cooperation. Here we present a computational simulation of evolving entities that includes symbiosis with shifting levels of selection. In the simulation, the fitness of an entity is measured by a series of one-on-one competitions in the Immigration Game, a two-player variation of Conway's Game of Life. Mutation, reproduction, and symbiosis are implemented as operations that are external to the Immigration Game. Because these operations are external to the game, we are able to freely manipulate the operations and observe the effects of the manipulations. The simulation is composed of four layers, each layer building on the previous layer. The first layer implements a simple form of asexual reproduction, the second layer introduces a more sophisticated form of asexual reproduction, the third layer adds sexual reproduction, and the fourth layer adds symbiosis. The experiments show that a small amount of symbiosis, added to the other layers, significantly increases the fitness of the population. We suggest that, in addition to providing new insights into biological and cultural evolution, this model of symbiosis may have practical applications in evolutionary computation, such as in the task of learning deep neural network models.
The Natural Selection of Words: Finding the Features of Fitness
Aug 19, 2019
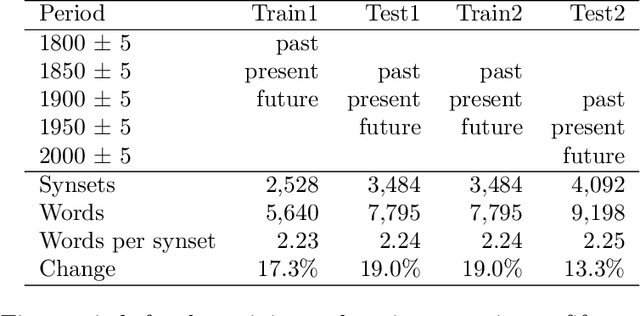

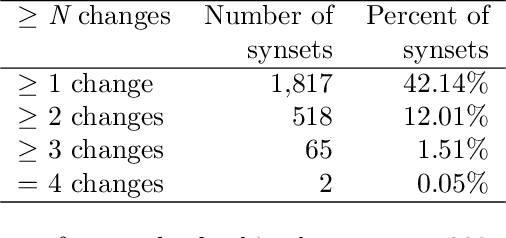
We introduce a dataset for studying the evolution of words, constructed from WordNet and the Google Books Ngram Corpus. The dataset tracks the evolution of 4,000 synonym sets (synsets), containing 9,000 English words, from 1800 AD to 2000 AD. We present a supervised learning algorithm that is able to predict the future leader of a synset: the word in the synset that will have the highest frequency. The algorithm uses features based on a word's length, the characters in the word, and the historical frequencies of the word. It can predict change of leadership (including the identity of the new leader) fifty years in the future, with an F-score considerably above random guessing. Analysis of the learned models provides insight into the causes of change in the leader of a synset. The algorithm confirms observations linguists have made, such as the trend to replace the -ise suffix with -ize, the rivalry between the -ity and -ness suffixes, and the struggle between economy (shorter words are easier to remember and to write) and clarity (longer words are more distinctive and less likely to be confused with one another). The results indicate that integration of the Google Books Ngram Corpus with WordNet has significant potential for improving our understanding of how language evolves.
Conditions for Major Transitions in Biological and Cultural Evolution
Jun 20, 2018Evolution by natural selection can be seen an algorithm for generating creative solutions to difficult problems. More precisely, evolution by natural selection is a class of algorithms that share a set of properties. The question we address here is, what are the conditions that define this class of algorithms? There is a standard answer to this question: Briefly, the conditions are variation, heredity, and selection. We agree that these three conditions are sufficient for a limited type of evolution, but they are not sufficient for open-ended evolution. By open-ended evolution, we mean evolution that generates a continuous stream of creative solutions, without stagnating. We propose a set of conditions for open-ended evolution. The new conditions build on the standard conditions by adding fission, fusion, and cooperation. We test the proposed conditions by applying them to major transitions in the evolution of life and culture. We find that the proposed conditions are able to account for the major transitions.
Leveraging Term Banks for Answering Complex Questions: A Case for Sparse Vectors
Apr 11, 2017


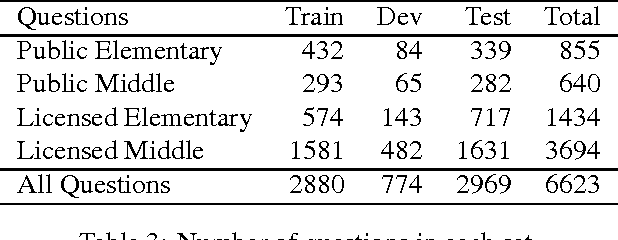
While open-domain question answering (QA) systems have proven effective for answering simple questions, they struggle with more complex questions. Our goal is to answer more complex questions reliably, without incurring a significant cost in knowledge resource construction to support the QA. One readily available knowledge resource is a term bank, enumerating the key concepts in a domain. We have developed an unsupervised learning approach that leverages a term bank to guide a QA system, by representing the terminological knowledge with thousands of specialized vector spaces. In experiments with complex science questions, we show that this approach significantly outperforms several state-of-the-art QA systems, demonstrating that significant leverage can be gained from continuous vector representations of domain terminology.
Semantic Composition and Decomposition: From Recognition to Generation
May 30, 2014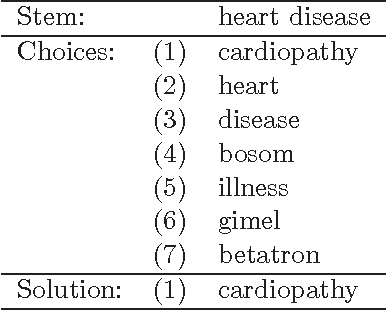
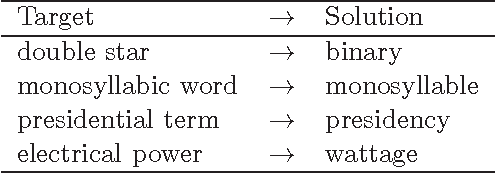


Semantic composition is the task of understanding the meaning of text by composing the meanings of the individual words in the text. Semantic decomposition is the task of understanding the meaning of an individual word by decomposing it into various aspects (factors, constituents, components) that are latent in the meaning of the word. We take a distributional approach to semantics, in which a word is represented by a context vector. Much recent work has considered the problem of recognizing compositions and decompositions, but we tackle the more difficult generation problem. For simplicity, we focus on noun-modifier bigrams and noun unigrams. A test for semantic composition is, given context vectors for the noun and modifier in a noun-modifier bigram ("red salmon"), generate a noun unigram that is synonymous with the given bigram ("sockeye"). A test for semantic decomposition is, given a context vector for a noun unigram ("snifter"), generate a noun-modifier bigram that is synonymous with the given unigram ("brandy glass"). With a vocabulary of about 73,000 unigrams from WordNet, there are 73,000 candidate unigram compositions for a bigram and 5,300,000,000 (73,000 squared) candidate bigram decompositions for a unigram. We generate ranked lists of potential solutions in two passes. A fast unsupervised learning algorithm generates an initial list of candidates and then a slower supervised learning algorithm refines the list. We evaluate the candidate solutions by comparing them to WordNet synonym sets. For decomposition (unigram to bigram), the top 100 most highly ranked bigrams include a WordNet synonym of the given unigram 50.7% of the time. For composition (bigram to unigram), the top 100 most highly ranked unigrams include a WordNet synonym of the given bigram 77.8% of the time.
Experiments with Three Approaches to Recognizing Lexical Entailment
Jan 31, 2014
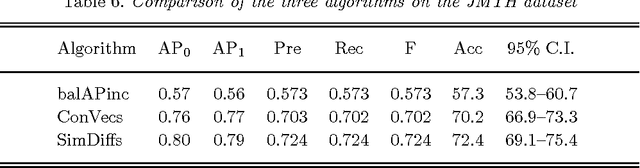
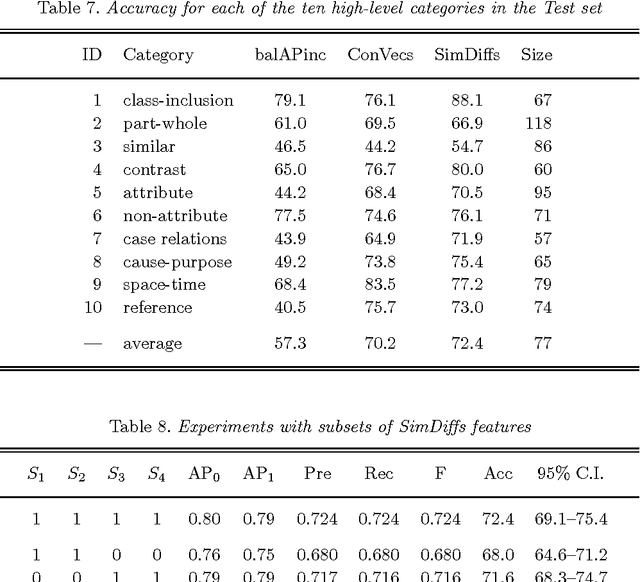

Inference in natural language often involves recognizing lexical entailment (RLE); that is, identifying whether one word entails another. For example, "buy" entails "own". Two general strategies for RLE have been proposed: One strategy is to manually construct an asymmetric similarity measure for context vectors (directional similarity) and another is to treat RLE as a problem of learning to recognize semantic relations using supervised machine learning techniques (relation classification). In this paper, we experiment with two recent state-of-the-art representatives of the two general strategies. The first approach is an asymmetric similarity measure (an instance of the directional similarity strategy), designed to capture the degree to which the contexts of a word, a, form a subset of the contexts of another word, b. The second approach (an instance of the relation classification strategy) represents a word pair, a:b, with a feature vector that is the concatenation of the context vectors of a and b, and then applies supervised learning to a training set of labeled feature vectors. Additionally, we introduce a third approach that is a new instance of the relation classification strategy. The third approach represents a word pair, a:b, with a feature vector in which the features are the differences in the similarities of a and b to a set of reference words. All three approaches use vector space models (VSMs) of semantics, based on word-context matrices. We perform an extensive evaluation of the three approaches using three different datasets. The proposed new approach (similarity differences) performs significantly better than the other two approaches on some datasets and there is no dataset for which it is significantly worse. Our results suggest it is beneficial to make connections between the research in lexical entailment and the research in semantic relation classification.
* to appear in Natural Language Engineering