 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenging common interpretability assumptions in feature attribution explanations
Paper and Code
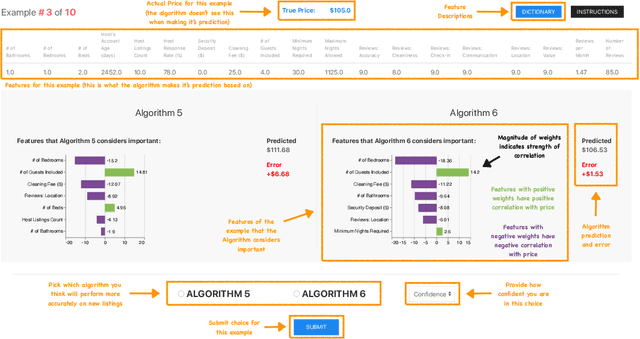

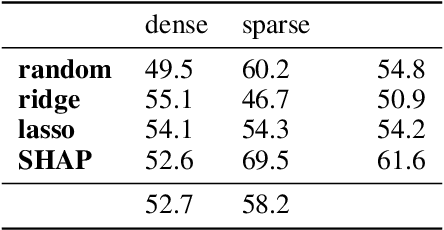
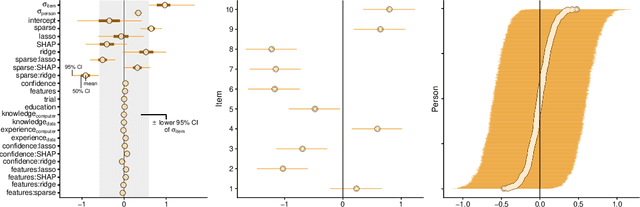
As machine learning and algorithmic decision making systems are increasingly being leveraged in high-stakes human-in-the-loop settings, there is a pressing need to understand the rationale of their predictions. Researchers have responded to this need with explainable AI (XAI), but often proclaim interpretability axiomatically without evaluation. When these systems are evaluated, they are often tested through offline simulations with proxy metrics of interpretability (such as model complexity). We empirically evaluate the veracity of three common interpretability assumptions through a large scale human-subjects experiment with a simple "placebo explanation" control. We find that feature attribution explanations provide marginal utility in our task for a human decision maker and in certain cases result in worse decisions due to cognitive and contextual confounders. This result challenges the assumed universal benefit of applying these methods and we hope this work will underscore the importance of human evaluation in XAI research. Supplemental materials -- including anonymized data from the experiment, code to replicate the study, an interactive demo of the experiment, and the models used in the analysis -- can be found at: https://doi.pizza/challenging-xai.