 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDownstream Datasets Make Surprisingly Good Pretraining Corpora
Paper and Code
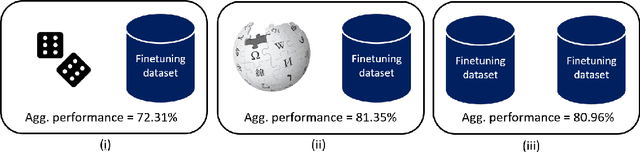
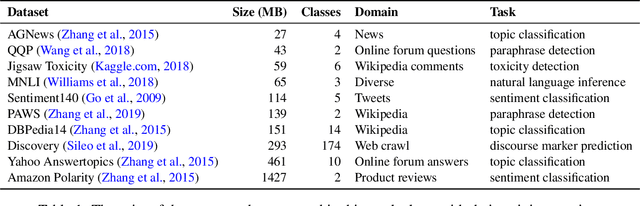
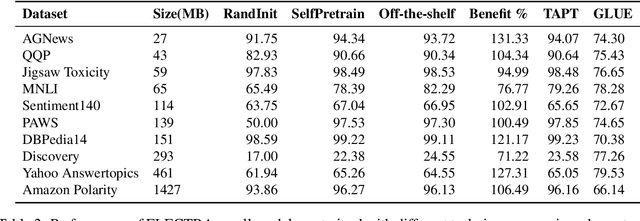
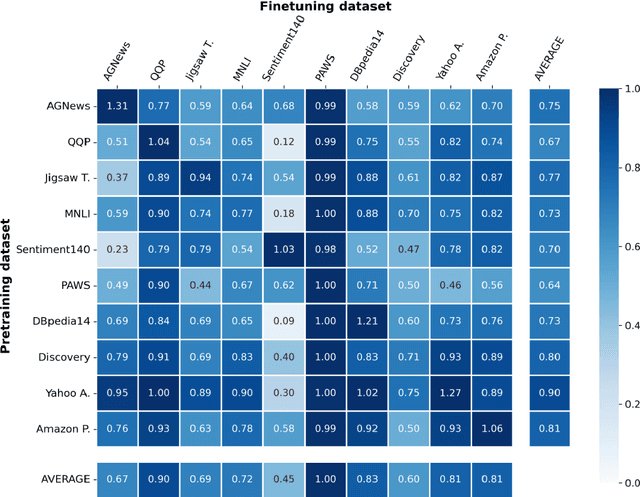
For most natural language processing tasks, the dominant practice is to finetune large pretrained transformer models (e.g., BERT) using smaller downstream datasets. Despite the success of this approach, it remains unclear to what extent these gains are attributable to the massive background corpora employed for pretraining versus to the pretraining objectives themselves. This paper introduces a large-scale study of self-pretraining, where the same (downstream) training data is used for both pretraining and finetuning. In experiments addressing both ELECTRA and RoBERTa models and 10 distinct downstream datasets, we observe that self-pretraining rivals standard pretraining on the BookWiki corpus (despite using around $10\times$--$500\times$ less data), outperforming the latter on $7$ and $5$ datasets, respectively. Surprisingly, these task-specific pretrained models often perform well on other tasks, including the GLUE benchmark. Our results suggest that in many scenarios, performance gains attributable to pretraining are driven primarily by the pretraining objective itself and are not always attributable to the incorporation of massive datasets. These findings are especially relevant in light of concerns about intellectual property and offensive content in web-scale pretraining data.