 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrawing Multiple Augmentation Samples Per Image During Training Efficiently Decreases Test Error
Paper and Code
May 27, 2021

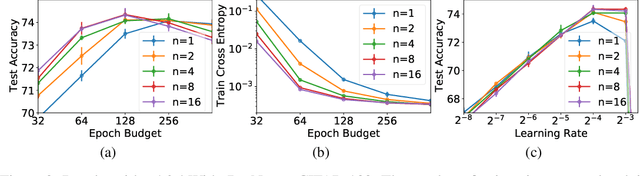

In computer vision, it is standard practice to draw a single sample from the data augmentation procedure for each unique image in the mini-batch, however it is not clear whether this choice is optimal for generalization. In this work, we provide a detailed empirical evaluation of how the number of augmentation samples per unique image influences performance on held out data. Remarkably, we find that drawing multiple samples per image consistently enhances the test accuracy achieved for both small and large batch training, despite reducing the number of unique training examples in each mini-batch. This benefit arises even when different augmentation multiplicities perform the same number of parameter updates and gradient evaluations. Our results suggest that, although the variance in the gradient estimate arising from subsampling the dataset has an implicit regularization benefit, the variance which arises from the data augmentation process harms test accuracy. By applying augmentation multiplicity to the recently proposed NFNet model family, we achieve a new ImageNet state of the art of 86.8$\%$ top-1 w/o extra data.