 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples
Paper and Code
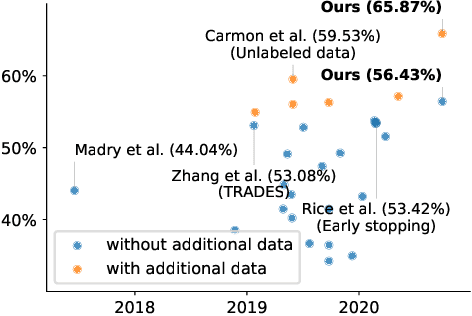

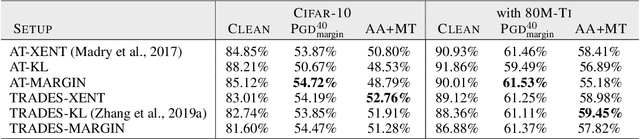
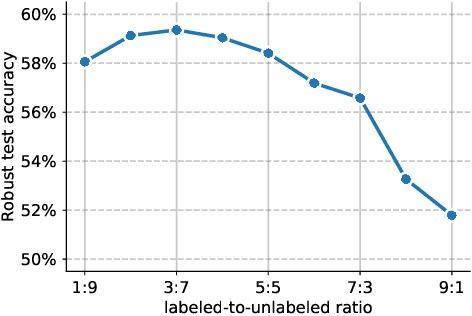
Adversarial training and its variants have become de facto standards for learning robust deep neural networks. In this paper, we explore the landscape around adversarial training in a bid to uncover its limits. We systematically study the effect of different training losses, model sizes, activation functions, the addition of unlabeled data (through pseudo-labeling) and other factors on adversarial robustness. We discover that it is possible to train robust models that go well beyond state-of-the-art results by combining larger models, Swish/SiLU activations and model weight averaging. We demonstrate large improvements on CIFAR-10 and CIFAR-100 against $\ell_\infty$ and $\ell_2$ norm-bounded perturbations of size $8/255$ and $128/255$, respectively. In the setting with additional unlabeled data, we obtain an accuracy under attack of 65.88% against $\ell_\infty$ perturbations of size $8/255$ on CIFAR-10 (+6.35% with respect to prior art). Without additional data, we obtain an accuracy under attack of 57.20% (+3.46%). To test the generality of our findings and without any additional modifications, we obtain an accuracy under attack of 80.53% (+7.62%) against $\ell_2$ perturbations of size $128/255$ on CIFAR-10, and of 36.88% (+8.46%) against $\ell_\infty$ perturbations of size $8/255$ on CIFAR-100.