 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSportsHHI: A Dataset for Human-Human Interaction Detection in Sports Videos
Apr 06, 2024
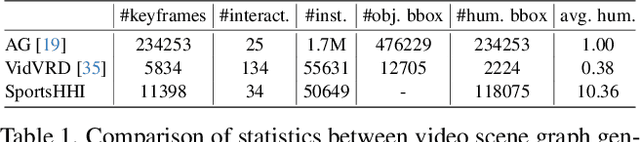
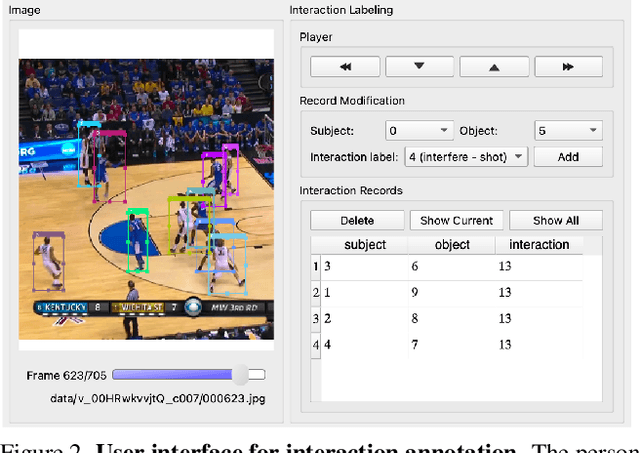
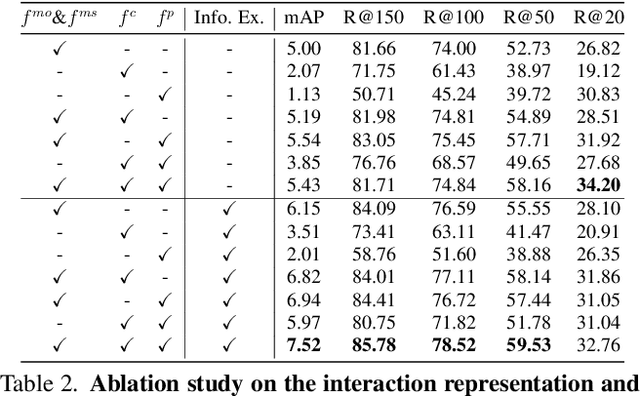
Video-based visual relation detection tasks, such as video scene graph generation, play important roles in fine-grained video understanding. However, current video visual relation detection datasets have two main limitations that hinder the progress of research in this area. First, they do not explore complex human-human interactions in multi-person scenarios. Second, the relation types of existing datasets have relatively low-level semantics and can be often recognized by appearance or simple prior information, without the need for detailed spatio-temporal context reasoning. Nevertheless, comprehending high-level interactions between humans is crucial for understanding complex multi-person videos, such as sports and surveillance videos. To address this issue, we propose a new video visual relation detection task: video human-human interaction detection, and build a dataset named SportsHHI for it. SportsHHI contains 34 high-level interaction classes from basketball and volleyball sports. 118,075 human bounding boxes and 50,649 interaction instances are annotated on 11,398 keyframes. To benchmark this, we propose a two-stage baseline method and conduct extensive experiments to reveal the key factors for a successful human-human interaction detector. We hope that SportsHHI can stimulate research on human interaction understanding in videos and promote the development of spatio-temporal context modeling techniques in video visual relation detection.
MultiSports: A Multi-Person Video Dataset of Spatio-Temporally Localized Sports Actions
May 16, 2021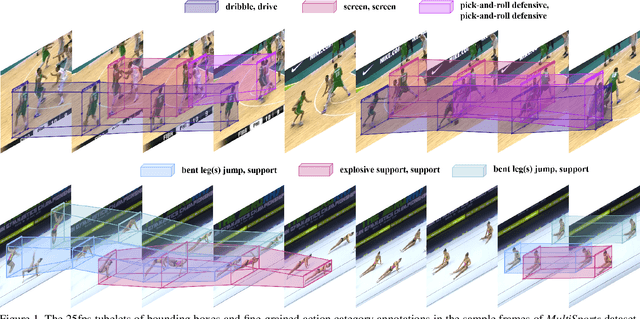
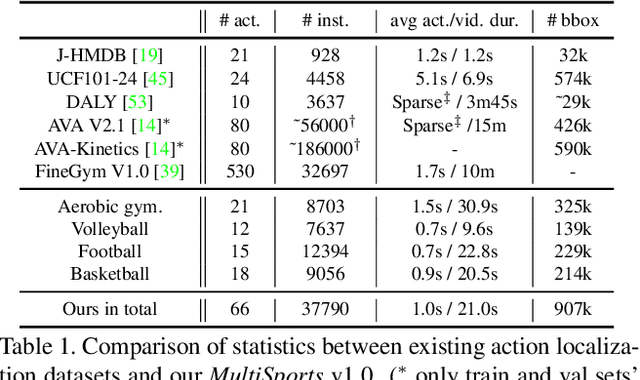
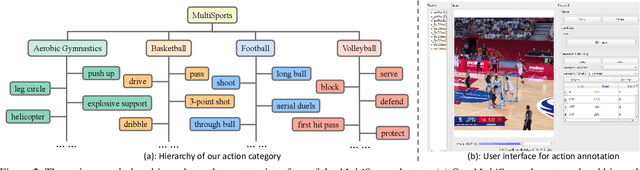

Spatio-temporal action detection is an important and challenging problem in video understanding. The existing action detection benchmarks are limited in aspects of small numbers of instances in a trimmed video or relatively low-level atomic actions. This paper aims to present a new multi-person dataset of spatio-temporal localized sports actions, coined as MultiSports. We first analyze the important ingredients of constructing a realistic and challenging dataset for spatio-temporal action detection by proposing three criteria: (1) motion dependent identification, (2) with well-defined boundaries, (3) relatively high-level classes. Based on these guidelines, we build the dataset of Multi-Sports v1.0 by selecting 4 sports classes, collecting around 3200 video clips, and annotating around 37790 action instances with 907k bounding boxes. Our datasets are characterized with important properties of strong diversity, detailed annotation, and high quality. Our MultiSports, with its realistic setting and dense annotations, exposes the intrinsic challenge of action localization. To benchmark this, we adapt several representative methods to our dataset and give an in-depth analysis on the difficulty of action localization in our dataset. We hope our MultiSports can serve as a standard benchmark for spatio-temporal action detection in the future. Our dataset website is at https://deeperaction.github.io/multisports/.