 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Efficiency Image Compression for Large Visual-Language Models
Jul 24, 2024In recent years, large visual language models (LVLMs) have shown impressive performance and promising generalization capability in multi-modal tasks, thus replacing humans as receivers of visual information in various application scenarios. In this paper, we pioneer to propose a variable bitrate image compression framework consisting of a pre-editing module and an end-to-end codec to achieve promising rate-accuracy performance for different LVLMs. In particular, instead of optimizing an adaptive pre-editing network towards a particular task or several representative tasks, we propose a new optimization strategy tailored for LVLMs, which is designed based on the representation and discrimination capability with token-level distortion and rank. The pre-editing module and the variable bitrate end-to-end image codec are jointly trained by the losses based on semantic tokens of the large model, which introduce enhanced generalization capability for various data and tasks. {Experimental results demonstrate that the proposed framework could efficiently achieve much better rate-accuracy performance compared to the state-of-the-art coding standard, Versatile Video Coding.} Meanwhile, experiments with multi-modal tasks have revealed the robustness and generalization capability of the proposed framework.
Interactive Face Video Coding: A Generative Compression Framework
Feb 20, 2023



In this paper, we propose a novel framework for Interactive Face Video Coding (IFVC), which allows humans to interact with the intrinsic visual representations instead of the signals. The proposed solution enjoys several distinct advantages, including ultra-compact representation, low delay interaction, and vivid expression and headpose animation. In particular, we propose the Internal Dimension Increase (IDI) based representation, greatly enhancing the fidelity and flexibility in rendering the appearance while maintaining reasonable representation cost. By leveraging strong statistical regularities, the visual signals can be effectively projected into controllable semantics in the three dimensional space (e.g., mouth motion, eye blinking, head rotation and head translation), which are compressed and transmitted. The editable bitstream, which naturally supports the interactivity at the semantic level, can synthesize the face frames via the strong inference ability of the deep generative model. Experimental results have demonstrated the performance superiority and application prospects of our proposed IFVC scheme. In particular, the proposed scheme not only outperforms the state-of-the-art video coding standard Versatile Video Coding (VVC) and the latest generative compression schemes in terms of rate-distortion performance for face videos, but also enables the interactive coding without introducing additional manipulation processes. Furthermore, the proposed framework is expected to shed lights on the future design of the digital human communication in the metaverse.
Just Noticeable Difference Modeling for Face Recognition System
Sep 13, 2022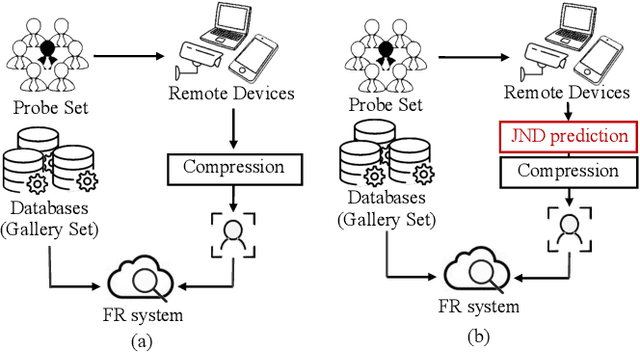
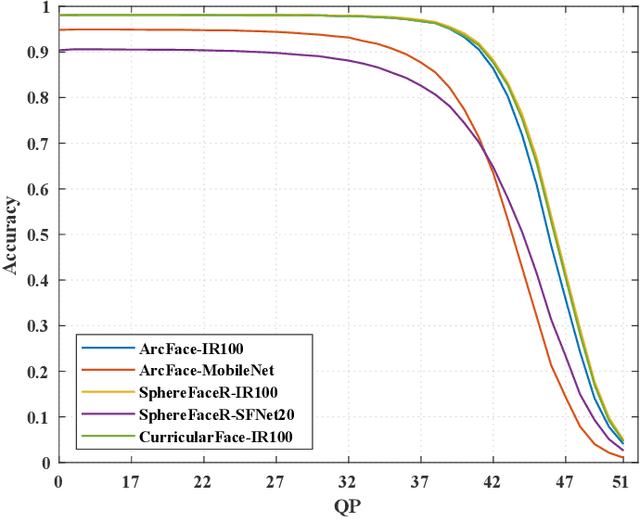
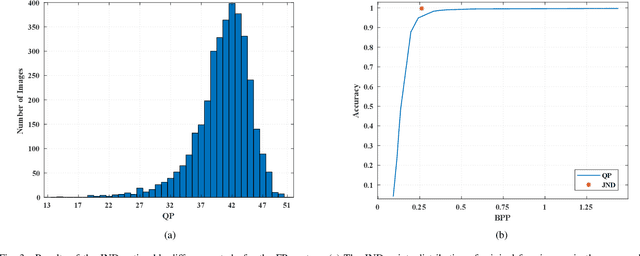
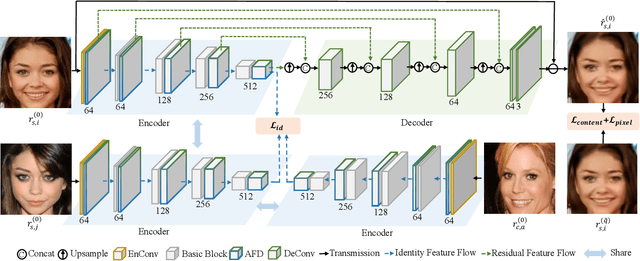
High-quality face images are required to guarantee the stability and reliability of automatic face recognition (FR) systems in surveillance and security scenarios. However, a massive amount of face data is usually compressed before being analyzed due to limitations on transmission or storage. The compressed images may lose the powerful identity information, resulting in the performance degradation of the FR system. Herein, we make the first attempt to study just noticeable difference (JND) for the FR system, which can be defined as the maximum distortion that the FR system cannot notice. More specifically, we establish a JND dataset including 3530 original images and 137,670 compressed images generated by advanced reference encoding/decoding software based on the Versatile Video Coding (VVC) standard (VTM-15.0). Subsequently, we develop a novel JND prediction model to directly infer JND images for the FR system. In particular, in order to maximum redundancy removal without impairment of robust identity information, we apply the encoder with multiple feature extraction and attention-based feature decomposition modules to progressively decompose face features into two uncorrelated components, i.e., identity and residual features, via self-supervised learning. Then, the residual feature is fed into the decoder to generate the residual map. Finally, the predicted JND map is obtained by subtracting the residual map from the original image. Experimental results have demonstrated that the proposed model achieves higher accuracy of JND map prediction compared with the state-of-the-art JND models, and is capable of saving more bits while maintaining the performance of the FR system compared with VTM-15.0.
End-to-end Compression Towards Machine Vision: Network Architecture Design and Optimization
Jul 01, 2021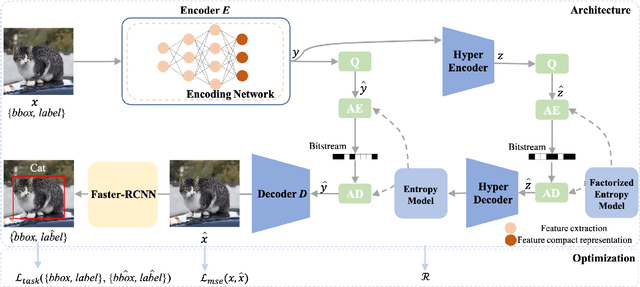



The research of visual signal compression has a long history. Fueled by deep learning, exciting progress has been made recently. Despite achieving better compression performance, existing end-to-end compression algorithms are still designed towards better signal quality in terms of rate-distortion optimization. In this paper, we show that the design and optimization of network architecture could be further improved for compression towards machine vision. We propose an inverted bottleneck structure for end-to-end compression towards machine vision, which specifically accounts for efficient representation of the semantic information. Moreover, we quest the capability of optimization by incorporating the analytics accuracy into the optimization process, and the optimality is further explored with generalized rate-accuracy optimization in an iterative manner. We use object detection as a showcase for end-to-end compression towards machine vision, and extensive experiments show that the proposed scheme achieves significant BD-rate savings in terms of analysis performance. Moreover, the promise of the scheme is also demonstrated with strong generalization capability towards other machine vision tasks, due to the enabling of signal-level reconstruction.
Towards Analysis-friendly Face Representation with Scalable Feature and Texture Compression
Apr 21, 2020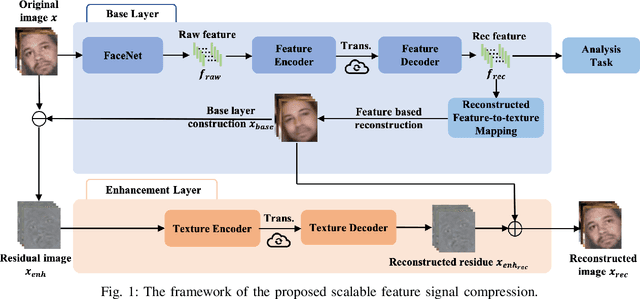

It plays a fundamental role to compactly represent the visual information towards the optimization of the ultimate utility in myriad visual data centered applications. With numerous approaches proposed to efficiently compress the texture and visual features serving human visual perception and machine intelligence respectively, much less work has been dedicated to studying the interactions between them. Here we investigate the integration of feature and texture compression, and show that a universal and collaborative visual information representation can be achieved in a hierarchical way. In particular, we study the feature and texture compression in a scalable coding framework, where the base layer serves as the deep learning feature and enhancement layer targets to perfectly reconstruct the texture. Based on the strong generative capability of deep neural networks, the gap between the base feature layer and enhancement layer is further filled with the feature level texture reconstruction, aiming to further construct texture representation from feature. As such, the residuals between the original and reconstructed texture could be further conveyed in the enhancement layer. To improve the efficiency of the proposed framework, the base layer neural network is trained in a multi-task manner such that the learned features enjoy both high quality reconstruction and high accuracy analysis. We further demonstrate the framework and optimization strategies in face image compression, and promising coding performance has been achieved in terms of both rate-fidelity and rate-accuracy.
End-to-End Facial Deep Learning Feature Compression with Teacher-Student Enhancement
Feb 10, 2020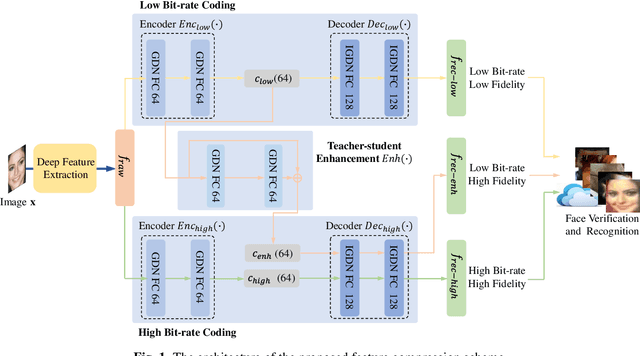


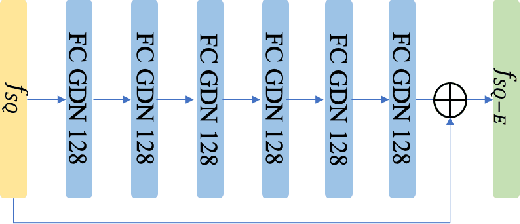
In this paper, we propose a novel end-to-end feature compression scheme by leveraging the representation and learning capability of deep neural networks, towards intelligent front-end equipped analysis with promising accuracy and efficiency. In particular, the extracted features are compactly coded in an end-to-end manner by optimizing the rate-distortion cost to achieve feature-in-feature representation. In order to further improve the compression performance, we present a latent code level teacher-student enhancement model, which could efficiently transfer the low bit-rate representation into a high bit rate one. Such a strategy further allows us to adaptively shift the representation cost to decoding computations, leading to more flexible feature compression with enhanced decoding capability. We verify the effectiveness of the proposed model with the facial feature, and experimental results reveal better compression performance in terms of rate-accuracy compared with existing models.
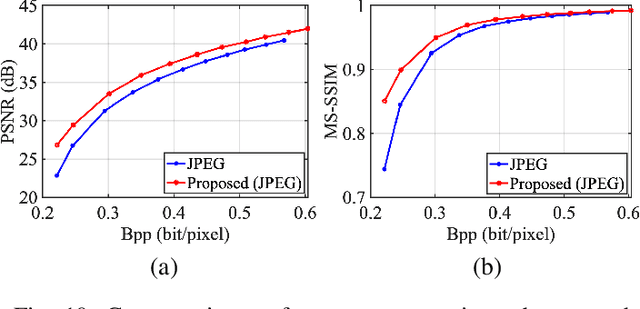
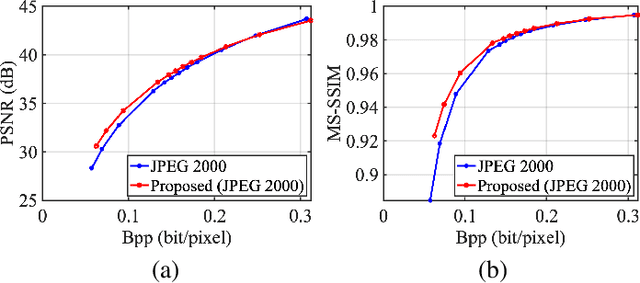
Scalable Facial Image Compression with Deep Feature Reconstruction
Mar 14, 2019



In this paper, we propose a scalable image compression scheme, including the base layer for feature representation and enhancement layer for texture representation. More specifically, the base layer is designed as the deep learning feature for analysis purpose, and it can also be converted to the fine structure with deep feature reconstruction. The enhancement layer, which serves to compress the residuals between the input image and the signals generated from the base layer, aims to faithfully reconstruct the input texture. The proposed scheme can feasibly inherit the advantages of both compress-then-analyze and analyze-then-compress schemes in surveillance applications. The performance of this framework is validated with facial images, and the conducted experiments provide useful evidences to show that the proposed framework can achieve better rate-accuracy and rate-distortion performance over conventional image compression schemes.