 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Audio-Visual-conditioned Diffusion Model for Video Saliency Prediction
Apr 19, 2025

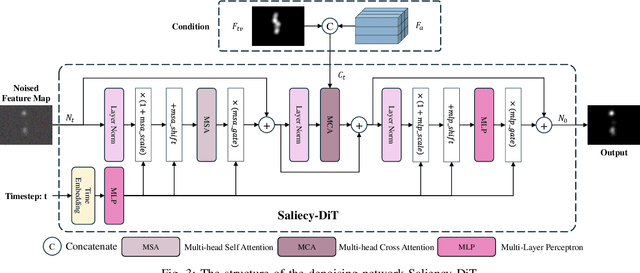

Video saliency prediction is crucial for downstream applications, such as video compression and human-computer interaction. With the flourishing of multimodal learning, researchers started to explore multimodal video saliency prediction, including audio-visual and text-visual approaches. Auditory cues guide the gaze of viewers to sound sources, while textual cues provide semantic guidance for understanding video content. Integrating these complementary cues can improve the accuracy of saliency prediction. Therefore, we attempt to simultaneously analyze visual, auditory, and textual modalities in this paper, and propose TAVDiff, a Text-Audio-Visual-conditioned Diffusion Model for video saliency prediction. TAVDiff treats video saliency prediction as an image generation task conditioned on textual, audio, and visual inputs, and predicts saliency maps through stepwise denoising. To effectively utilize text, a large multimodal model is used to generate textual descriptions for video frames and introduce a saliency-oriented image-text response (SITR) mechanism to generate image-text response maps. It is used as conditional information to guide the model to localize the visual regions that are semantically related to the textual description. Regarding the auditory modality, it is used as another conditional information for directing the model to focus on salient regions indicated by sounds. At the same time, since the diffusion transformer (DiT) directly concatenates the conditional information with the timestep, which may affect the estimation of the noise level. To achieve effective conditional guidance, we propose Saliency-DiT, which decouples the conditional information from the timestep. Experimental results show that TAVDiff outperforms existing methods, improving 1.03\%, 2.35\%, 2.71\% and 0.33\% on SIM, CC, NSS and AUC-J metrics, respectively.
Relevance-guided Audio Visual Fusion for Video Saliency Prediction
Nov 18, 2024
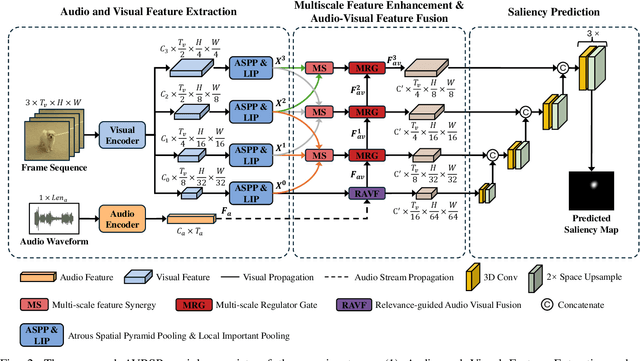
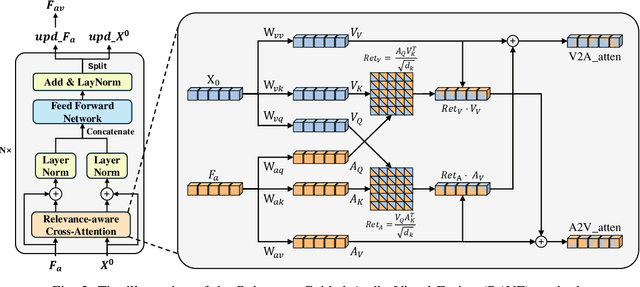
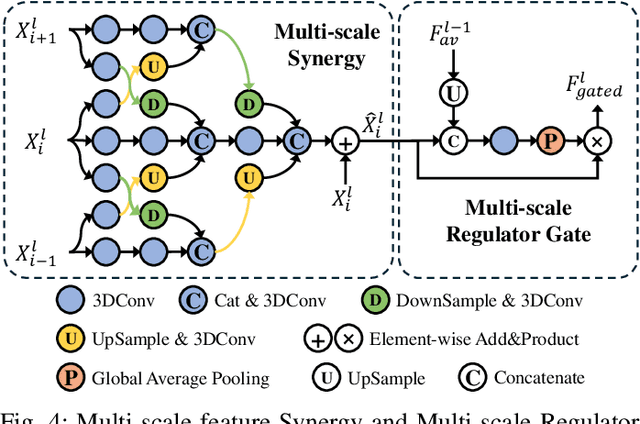
Audio data, often synchronized with video frames, plays a crucial role in guiding the audience's visual attention. Incorporating audio information into video saliency prediction tasks can enhance the prediction of human visual behavior. However, existing audio-visual saliency prediction methods often directly fuse audio and visual features, which ignore the possibility of inconsistency between the two modalities, such as when the audio serves as background music. To address this issue, we propose a novel relevance-guided audio-visual saliency prediction network dubbed AVRSP. Specifically, the Relevance-guided Audio-Visual feature Fusion module (RAVF) dynamically adjusts the retention of audio features based on the semantic relevance between audio and visual elements, thereby refining the integration process with visual features. Furthermore, the Multi-scale feature Synergy (MS) module integrates visual features from different encoding stages, enhancing the network's ability to represent objects at various scales. The Multi-scale Regulator Gate (MRG) could transfer crucial fusion information to visual features, thus optimizing the utilization of multi-scale visual features. Extensive experiments on six audio-visual eye movement datasets have demonstrated that our AVRSP network achieves competitive performance in audio-visual saliency prediction.