 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale temporal network for continuous sign language recognition
Paper and Code
Apr 08, 2022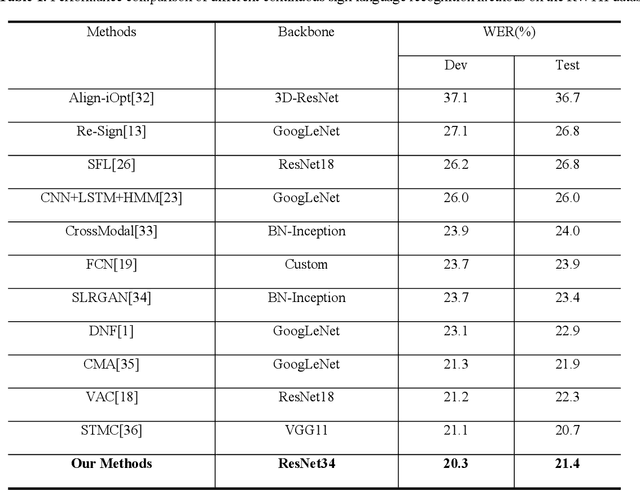
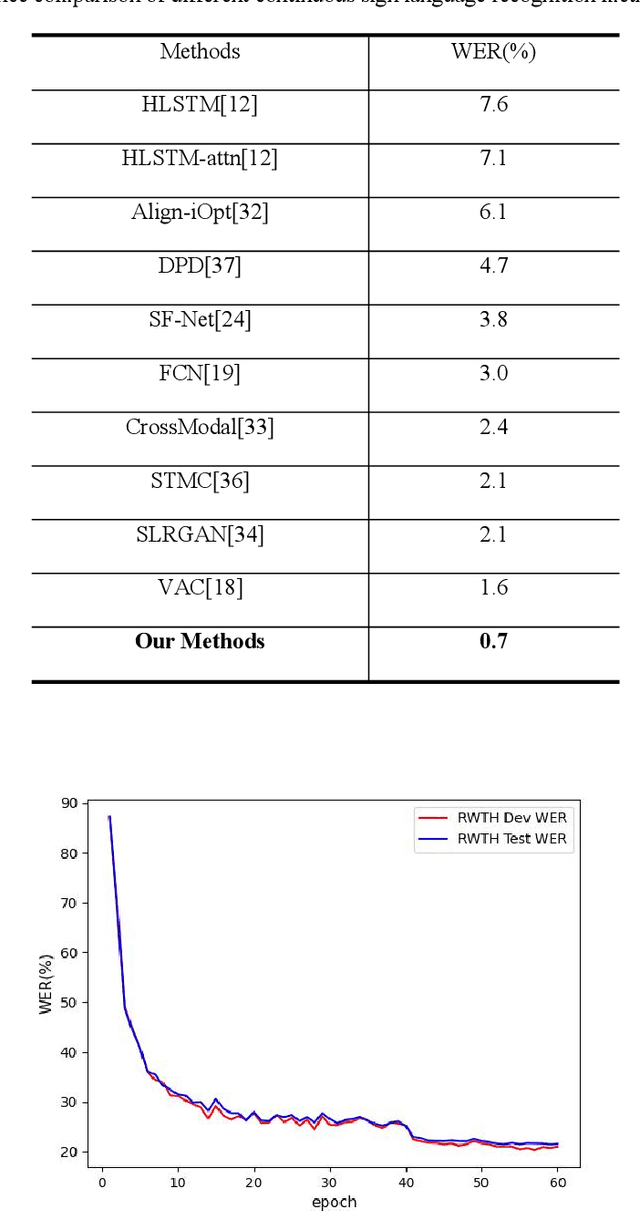
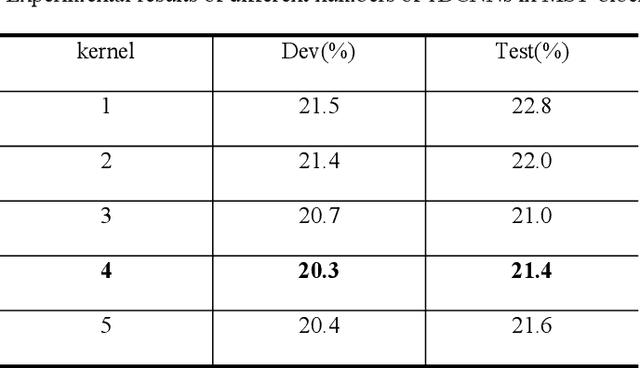

Continuous Sign Language Recognition (CSLR) is a challenging research task due to the lack of accurate annotation on the temporal sequence of sign language data. The recent popular usage is a hybrid model based on "CNN + RNN" for CSLR. However, when extracting temporal features in these works, most of the methods using a fixed temporal receptive field and cannot extract the temporal features well for each sign language word. In order to obtain more accurate temporal features, this paper proposes a multi-scale temporal network (MSTNet). The network mainly consists of three parts. The Resnet and two fully connected (FC) layers constitute the frame-wise feature extraction part. The time-wise feature extraction part performs temporal feature learning by first extracting temporal receptive field features of different scales using the proposed multi-scale temporal block (MST-block) to improve the temporal modeling capability, and then further encoding the temporal features of different scales by the transformers module to obtain more accurate temporal features. Finally, the proposed multi-level Connectionist Temporal Classification (CTC) loss part is used for training to obtain recognition results. The multi-level CTC loss enables better learning and updating of the shallow network parameters in CNN, and the method has no parameter increase and can be flexibly embedded in other models. Experimental results on two publicly available datasets demonstrate that our method can effectively extract sign language features in an end-to-end manner without any prior knowledge, improving the accuracy of CSLR and reaching the state-of-the-art.