 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTABLET: Learning From Instructions For Tabular Data
Paper and Code

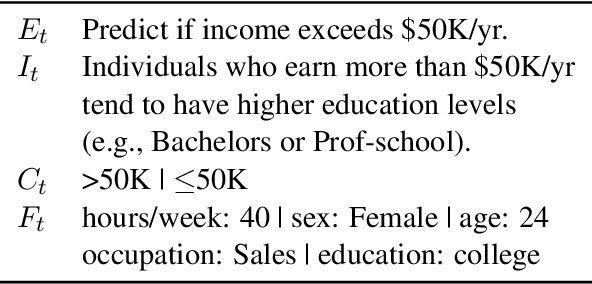

Acquiring high-quality data is often a significant challenge in training machine learning (ML) models for tabular prediction, particularly in privacy-sensitive and costly domains like medicine and finance. Providing natural language instructions to large language models (LLMs) offers an alternative solution. However, it is unclear how effectively instructions leverage the knowledge in LLMs for solving tabular prediction problems. To address this gap, we introduce TABLET, a benchmark of 20 diverse tabular datasets annotated with instructions that vary in their phrasing, granularity, and technicality. Additionally, TABLET includes the instructions' logic and structured modifications to the instructions. We find in-context instructions increase zero-shot F1 performance for Flan-T5 11b by 44% on average and 13% for ChatGPT on TABLET. Also, we explore the limitations of using LLMs for tabular prediction in our benchmark by evaluating instruction faithfulness. We find LLMs often ignore instructions and fail to predict specific instances correctly, even with examples. Our analysis on TABLET shows that, while instructions help LLM performance, learning from instructions for tabular data requires new capabilities.