 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFER: Data-Efficient and Safe Reinforcement Learning via Skill Acquisition
Paper and Code
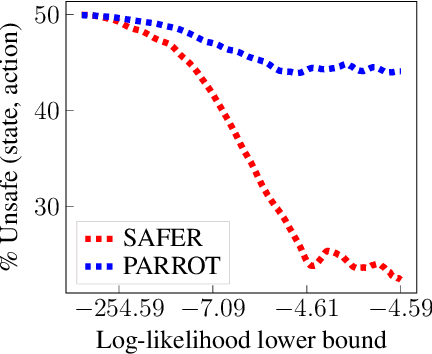
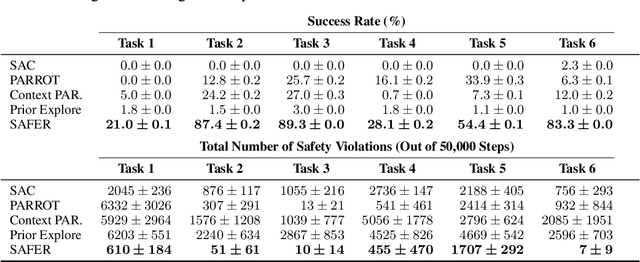
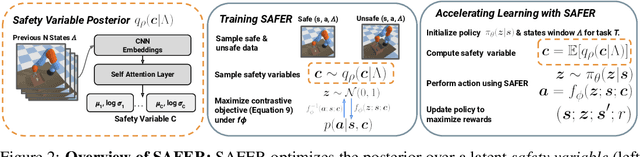
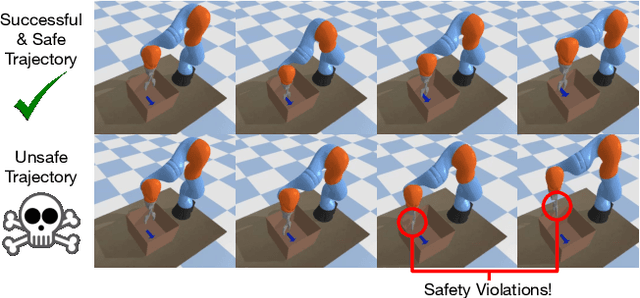
Though many reinforcement learning (RL) problems involve learning policies in settings with difficult-to-specify safety constraints and sparse rewards, current methods struggle to acquire successful and safe policies. Methods that extract useful policy primitives from offline datasets using generative modeling have recently shown promise at accelerating RL in these more complex settings. However, we discover that current primitive-learning methods may not be well-equipped for safe policy learning and may promote unsafe behavior due to their tendency to ignore data from undesirable behaviors. To overcome these issues, we propose SAFEty skill pRiors (SAFER), an algorithm that accelerates policy learning on complex control tasks under safety constraints. Through principled training on an offline dataset, SAFER learns to extract safe primitive skills. In the inference stage, policies trained with SAFER learn to compose safe skills into successful policies. We theoretically characterize why SAFER can enforce safe policy learning and demonstrate its effectiveness on several complex safety-critical robotic grasping tasks inspired by the game Operation, in which SAFER outperforms baseline methods in learning successful policies and enforcing safety.