 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semantic-aware Attention and Visual Shielding Network for Cloth-changing Person Re-identification
Paper and Code
Jul 18, 2022

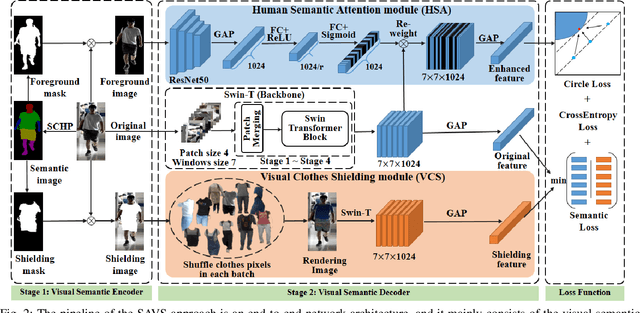

Cloth-changing person reidentification (ReID) is a newly emerging research topic that aims to retrieve pedestrians whose clothes are changed. Since the human appearance with different clothes exhibits large variations, it is very difficult for existing approaches to extract discriminative and robust feature representations. Current works mainly focus on body shape or contour sketches, but the human semantic information and the potential consistency of pedestrian features before and after changing clothes are not fully explored or are ignored. To solve these issues, in this work, a novel semantic-aware attention and visual shielding network for cloth-changing person ReID (abbreviated as SAVS) is proposed where the key idea is to shield clues related to the appearance of clothes and only focus on visual semantic information that is not sensitive to view/posture changes. Specifically, a visual semantic encoder is first employed to locate the human body and clothing regions based on human semantic segmentation information. Then, a human semantic attention module (HSA) is proposed to highlight the human semantic information and reweight the visual feature map. In addition, a visual clothes shielding module (VCS) is also designed to extract a more robust feature representation for the cloth-changing task by covering the clothing regions and focusing the model on the visual semantic information unrelated to the clothes. Most importantly, these two modules are jointly explored in an end-to-end unified framework. Extensive experiments demonstrate that the proposed method can significantly outperform state-of-the-art methods, and more robust features can be extracted for cloth-changing persons. Compared with FSAM (published in CVPR 2021), this method can achieve improvements of 32.7% (16.5%) and 14.9% (-) on the LTCC and PRCC datasets in terms of mAP (rank-1), respectively.