 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Graph-Like Learning with Contrastive Clustering on Temporally-Factored Ship Motion Data for Imbalanced Sea State Estimation in Autonomous Vessel
Apr 21, 2025



Accurate sea state estimation is crucial for the real-time control and future state prediction of autonomous vessels. However, traditional methods struggle with challenges such as data imbalance and feature redundancy in ship motion data, limiting their effectiveness. To address these challenges, we propose the Temporal-Graph Contrastive Clustering Sea State Estimator (TGC-SSE), a novel deep learning model that combines three key components: a time dimension factorization module to reduce data redundancy, a dynamic graph-like learning module to capture complex variable interactions, and a contrastive clustering loss function to effectively manage class imbalance. Our experiments demonstrate that TGC-SSE significantly outperforms existing methods across 14 public datasets, achieving the highest accuracy in 9 datasets, with a 20.79% improvement over EDI. Furthermore, in the field of sea state estimation, TGC-SSE surpasses five benchmark methods and seven deep learning models. Ablation studies confirm the effectiveness of each module, demonstrating their respective roles in enhancing overall model performance. Overall, TGC-SSE not only improves the accuracy of sea state estimation but also exhibits strong generalization capabilities, providing reliable support for autonomous vessel operations.
Prototype-based Heterogeneous Federated Learning for Blade Icing Detection in Wind Turbines with Class Imbalanced Data
Mar 11, 2025Wind farms, typically in high-latitude regions, face a high risk of blade icing. Traditional centralized training methods raise serious privacy concerns. To enhance data privacy in detecting wind turbine blade icing, traditional federated learning (FL) is employed. However, data heterogeneity, resulting from collections across wind farms in varying environmental conditions, impacts the model's optimization capabilities. Moreover, imbalances in wind turbine data lead to models that tend to favor recognizing majority classes, thus neglecting critical icing anomalies. To tackle these challenges, we propose a federated prototype learning model for class-imbalanced data in heterogeneous environments to detect wind turbine blade icing. We also propose a contrastive supervised loss function to address the class imbalance problem. Experiments on real data from 20 turbines across two wind farms show our method outperforms five FL models and five class imbalance methods, with an average improvement of 19.64\% in \( mF_{\beta} \) and 5.73\% in \( m \)BA compared to the second-best method, BiFL.
An End-to-End Model for Time Series Classification In the Presence of Missing Values
Aug 11, 2024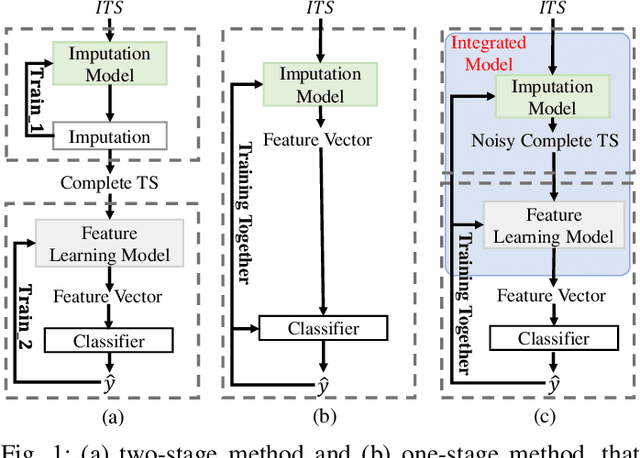
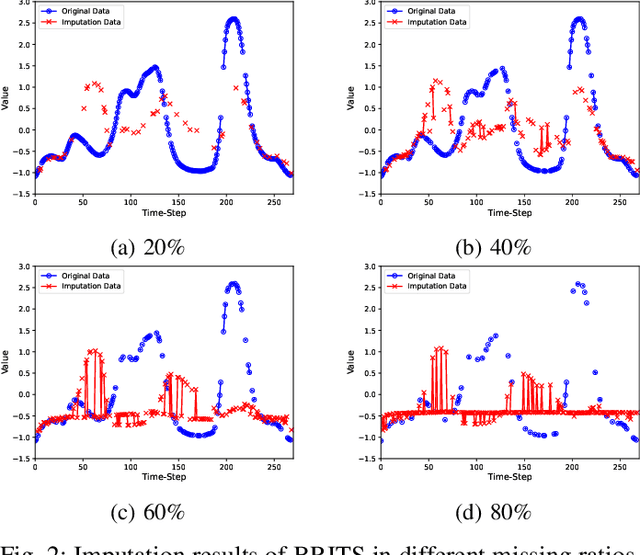
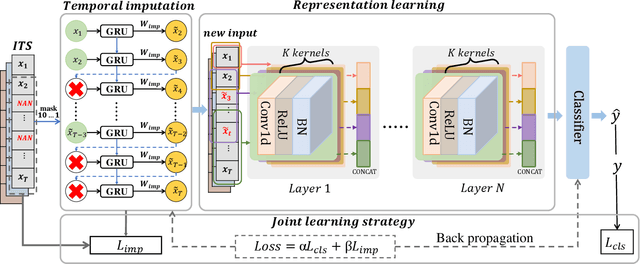
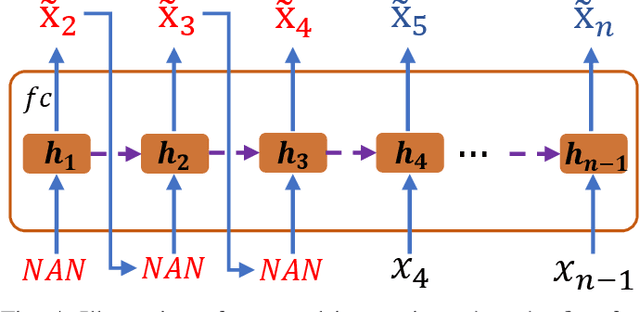
Time series classification with missing data is a prevalent issue in time series analysis, as temporal data often contain missing values in practical applications. The traditional two-stage approach, which handles imputation and classification separately, can result in sub-optimal performance as label information is not utilized in the imputation process. On the other hand, a one-stage approach can learn features under missing information, but feature representation is limited as imputed errors are propagated in the classification process. To overcome these challenges, this study proposes an end-to-end neural network that unifies data imputation and representation learning within a single framework, allowing the imputation process to take advantage of label information. Differing from previous methods, our approach places less emphasis on the accuracy of imputation data and instead prioritizes classification performance. A specifically designed multi-scale feature learning module is implemented to extract useful information from the noise-imputation data. The proposed model is evaluated on 68 univariate time series datasets from the UCR archive, as well as a multivariate time series dataset with various missing data ratios and 4 real-world datasets with missing information. The results indicate that the proposed model outperforms state-of-the-art approaches for incomplete time series classification, particularly in scenarios with high levels of missing data.