Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Reinforcement Learning with a Planning Quasi-Metric
Paper and Code
Feb 08, 2020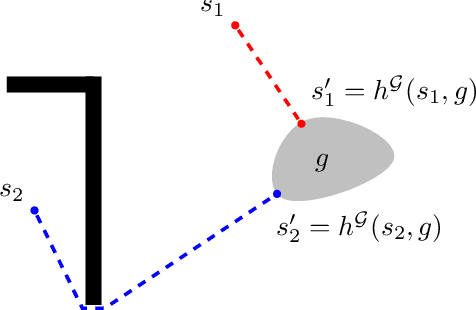
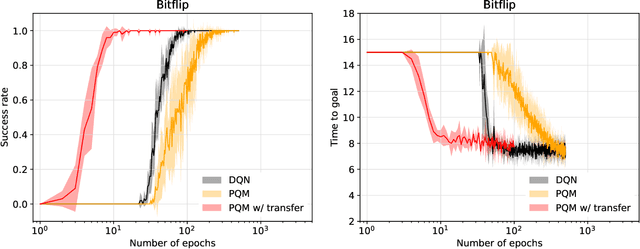
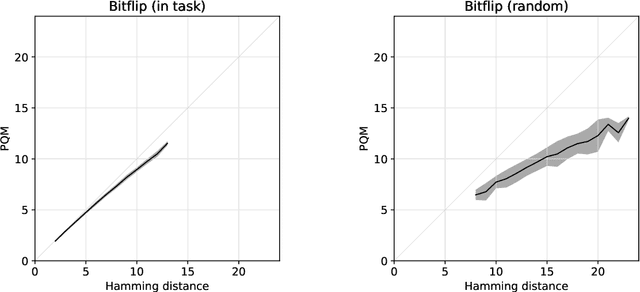

We introduce a new reinforcement learning approach combining a planning quasi-metric (PQM) that estimates the number of actions required to go from a state to another, with task-specific planners that compute a target state to reach a given goal. The main advantage of this decomposition is to allow the sharing across tasks of a task-agnostic model of the quasi-metric that captures the environment's dynamics and can be learned in a dense and unsupervised manner. We demonstrate the usefulness of this approach on the standard bit-flip problem and in the MuJoCo robotic arm simulator.
View paper on