 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold Mixup improves text recognition with CTC loss
Mar 11, 2019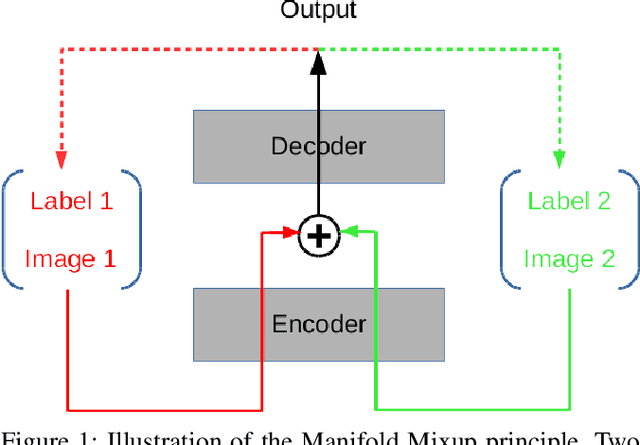
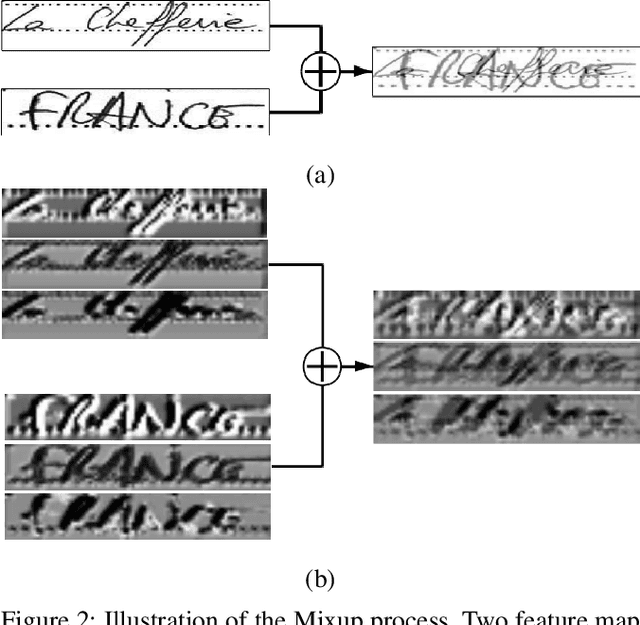
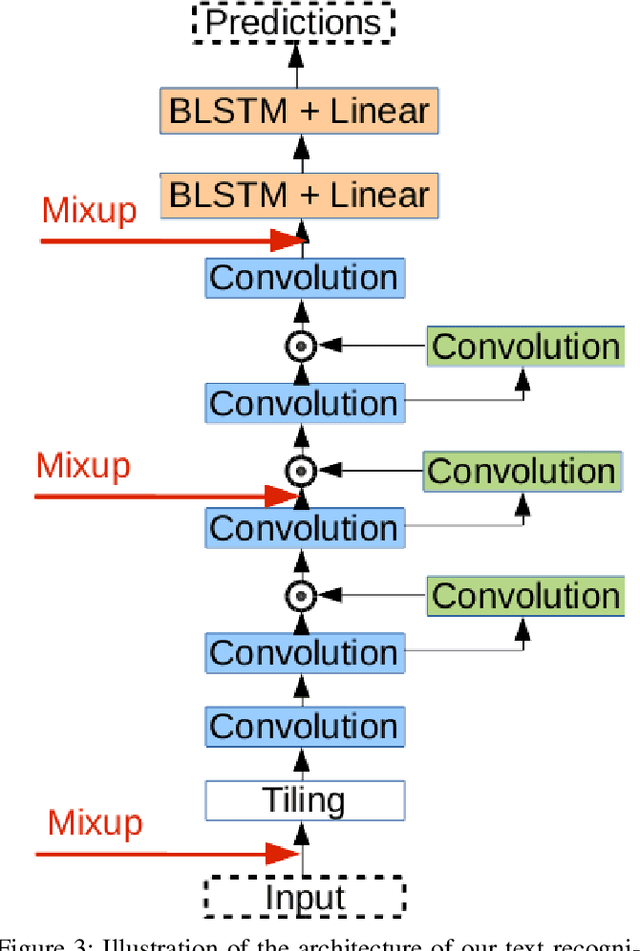
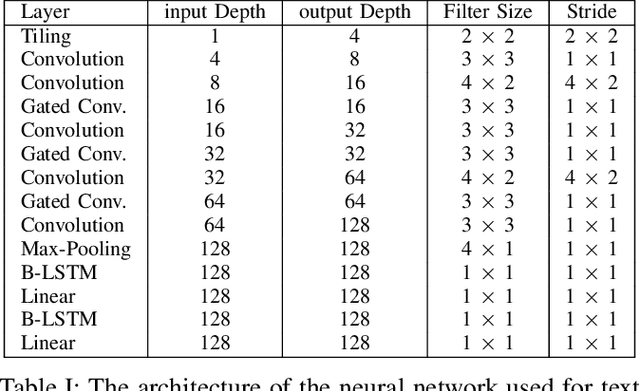
Modern handwritten text recognition techniques employ deep recurrent neural networks. The use of these techniques is especially efficient when a large amount of annotated data is available for parameter estimation. Data augmentation can be used to enhance the performance of the systems when data is scarce. Manifold Mixup is a modern method of data augmentation that meld two images or the feature maps corresponding to these images and the targets are fused accordingly. We propose to apply the Manifold Mixup to text recognition while adapting it to work with a Connectionist Temporal Classification cost. We show that Manifold Mixup improves text recognition results on various languages and datasets.
Adversarial Generation of Handwritten Text Images Conditioned on Sequences
Mar 01, 2019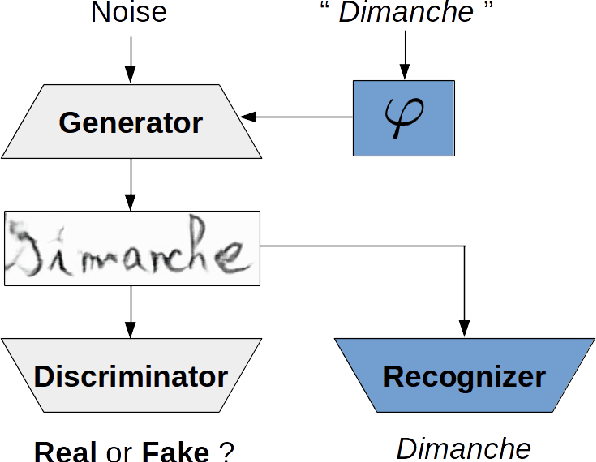
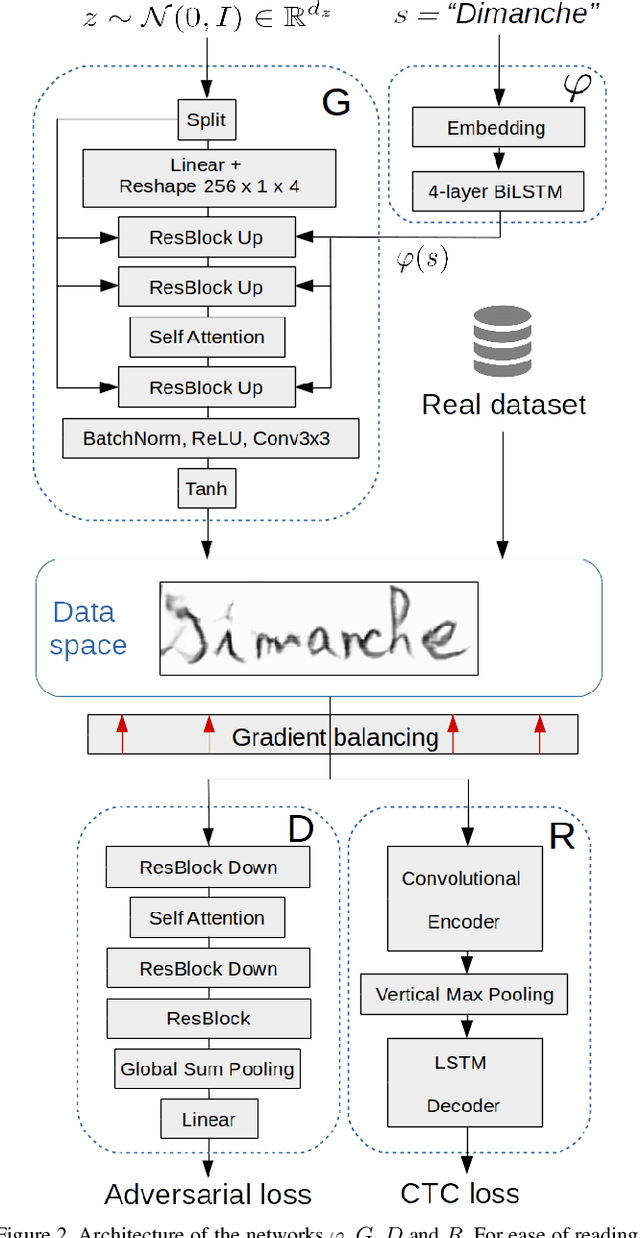
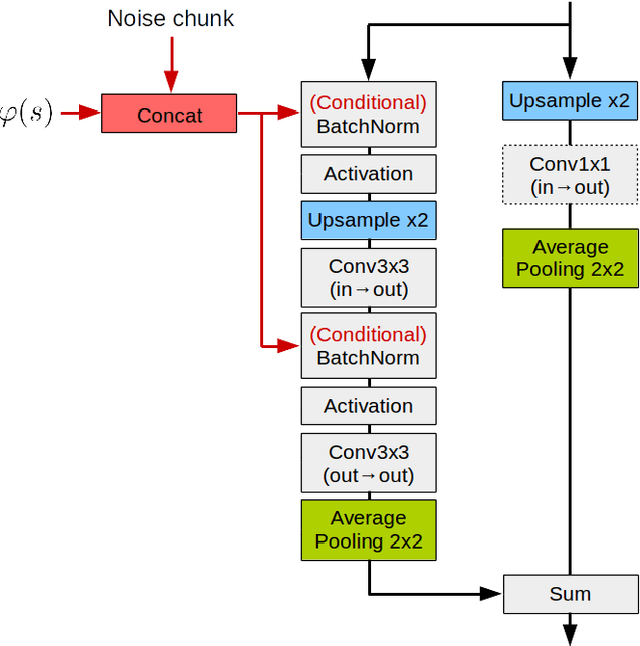
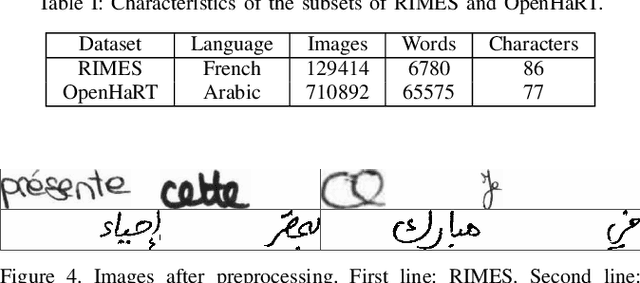
State-of-the-art offline handwriting text recognition systems tend to use neural networks and therefore require a large amount of annotated data to be trained. In order to partially satisfy this requirement, we propose a system based on Generative Adversarial Networks (GAN) to produce synthetic images of handwritten words. We use bidirectional LSTM recurrent layers to get an embedding of the word to be rendered, and we feed it to the generator network. We also modify the standard GAN by adding an auxiliary network for text recognition. The system is then trained with a balanced combination of an adversarial loss and a CTC loss. Together, these extensions to GAN enable to control the textual content of the generated word images. We obtain realistic images on both French and Arabic datasets, and we show that integrating these synthetic images into the existing training data of a text recognition system can slightly enhance its performance.
Are 2D-LSTM really dead for offline text recognition?
Nov 27, 2018


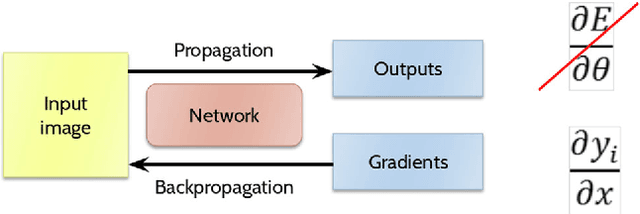
There is a recent trend in handwritten text recognition with deep neural networks to replace 2D recurrent layers with 1D, and in some cases even completely remove the recurrent layers, relying on simple feed-forward convolutional only architectures. The most used type of recurrent layer is the Long-Short Term Memory (LSTM). The motivations to do so are many: there are few open-source implementations of 2D-LSTM, even fewer supporting GPU implementations (currently cuDNN only implements 1D-LSTM); 2D recurrences reduce the amount of computations that can be parallelized, and thus possibly increase the training/inference time; recurrences create global dependencies with respect to the input, and sometimes this may not be desirable. Many recent competitions were won by systems that employed networks that use 2D-LSTM layers. Most previous work that compared 1D or pure feed-forward architectures to 2D recurrent models have done so on simple datasets or did not fully optimize the "baseline" 2D model compared to the challenger model, which was dully optimized. In this work, we aim at a fair comparison between 2D and competing models and also extensively evaluate them on more complex datasets that are more representative of challenging "real-world" data, compared to "academic" datasets that are more restricted in their complexity. We aim at determining when and why the 1D and 2D recurrent models have different results. We also compare the results with a language model to assess if linguistic constraints do level the performance of the different networks. Our results show that for challenging datasets, 2D-LSTM networks still seem to provide the highest performances and we propose a visualization strategy to explain it.
Full-Page Text Recognition: Learning Where to Start and When to Stop
Apr 27, 2017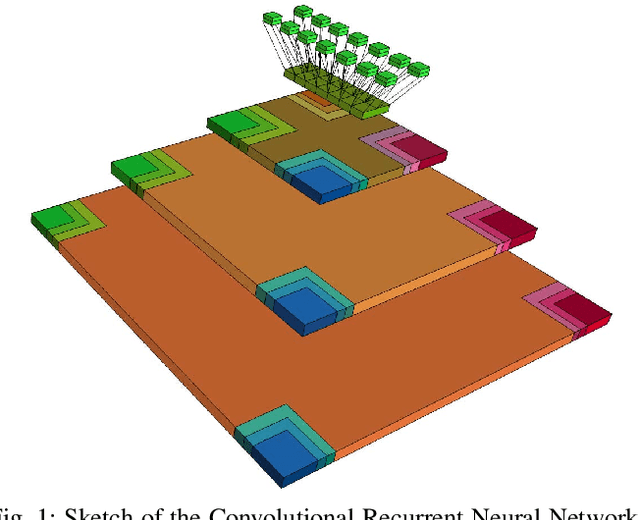


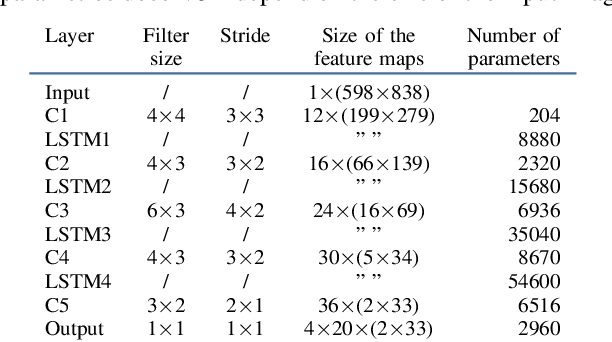
Text line detection and localization is a crucial step for full page document analysis, but still suffers from heterogeneity of real life documents. In this paper, we present a new approach for full page text recognition. Localization of the text lines is based on regressions with Fully Convolutional Neural Networks and Multidimensional Long Short-Term Memory as contextual layers. In order to increase the efficiency of this localization method, only the position of the left side of the text lines are predicted. The text recognizer is then in charge of predicting the end of the text to recognize. This method has shown good results for full page text recognition on the highly heterogeneous Maurdor dataset.
Learning to detect and localize many objects from few examples
Nov 17, 2016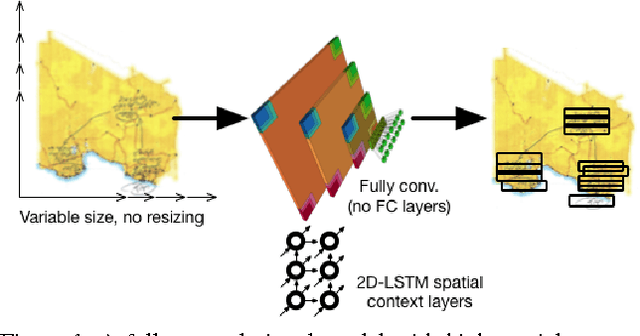
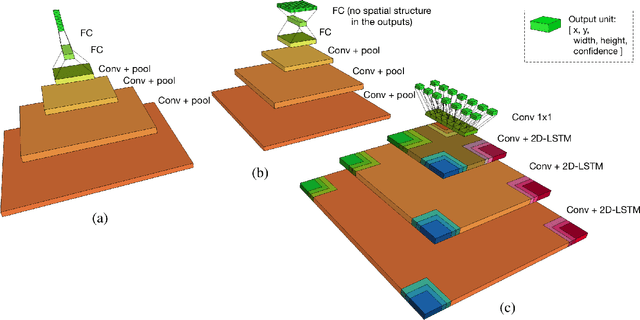
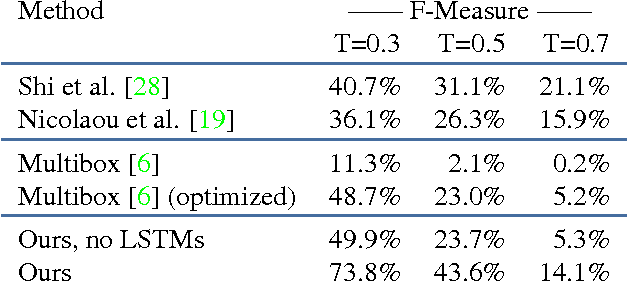
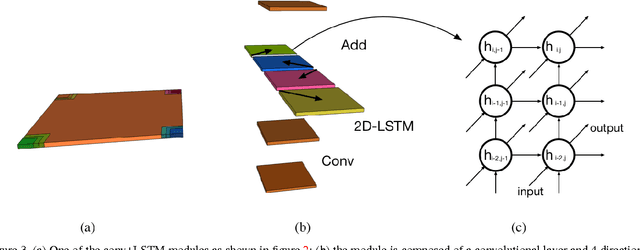
The current trend in object detection and localization is to learn predictions with high capacity deep neural networks trained on a very large amount of annotated data and using a high amount of processing power. In this work, we propose a new neural model which directly predicts bounding box coordinates. The particularity of our contribution lies in the local computations of predictions with a new form of local parameter sharing which keeps the overall amount of trainable parameters low. Key components of the model are spatial 2D-LSTM recurrent layers which convey contextual information between the regions of the image. We show that this model is more powerful than the state of the art in applications where training data is not as abundant as in the classical configuration of natural images and Imagenet/Pascal VOC tasks. We particularly target the detection of text in document images, but our method is not limited to this setting. The proposed model also facilitates the detection of many objects in a single image and can deal with inputs of variable sizes without resizing.