 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to detect and localize many objects from few examples
Paper and Code
Nov 17, 2016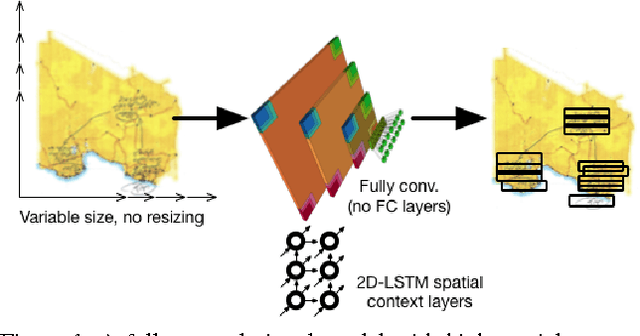
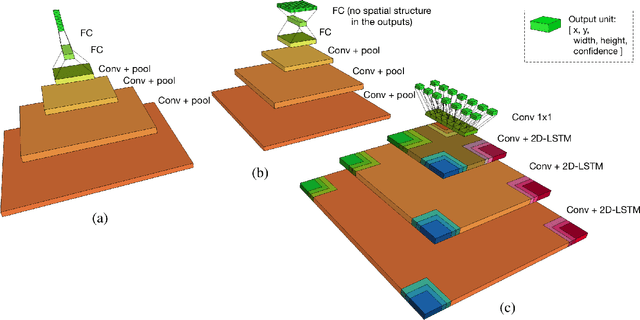
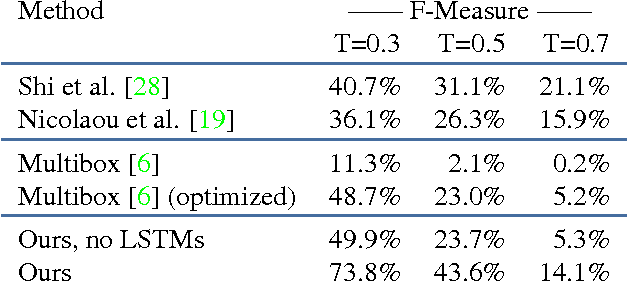
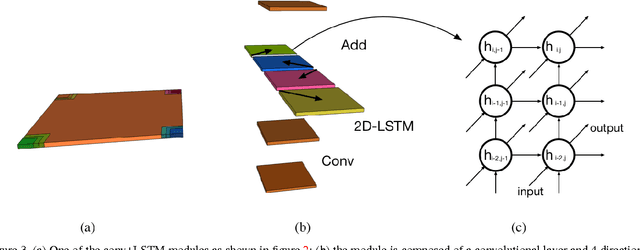
The current trend in object detection and localization is to learn predictions with high capacity deep neural networks trained on a very large amount of annotated data and using a high amount of processing power. In this work, we propose a new neural model which directly predicts bounding box coordinates. The particularity of our contribution lies in the local computations of predictions with a new form of local parameter sharing which keeps the overall amount of trainable parameters low. Key components of the model are spatial 2D-LSTM recurrent layers which convey contextual information between the regions of the image. We show that this model is more powerful than the state of the art in applications where training data is not as abundant as in the classical configuration of natural images and Imagenet/Pascal VOC tasks. We particularly target the detection of text in document images, but our method is not limited to this setting. The proposed model also facilitates the detection of many objects in a single image and can deal with inputs of variable sizes without resizing.