 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Nov 11, 2025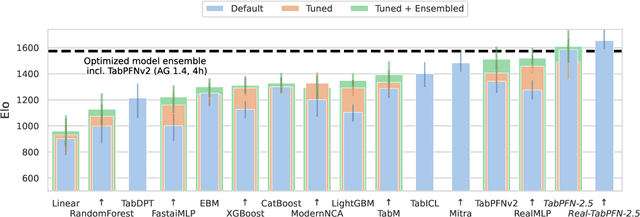
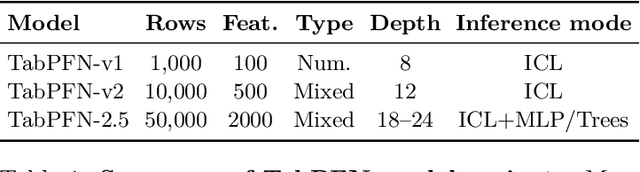
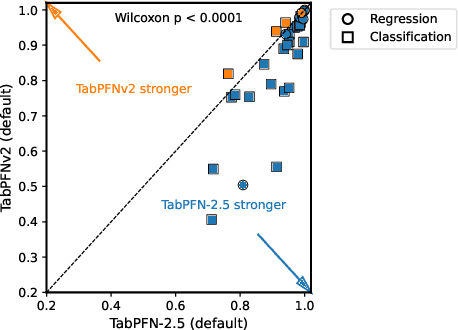
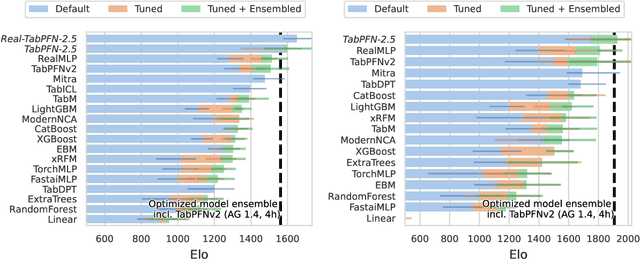
The first tabular foundation model, TabPFN, and its successor TabPFNv2 have impacted tabular AI substantially, with dozens of methods building on it and hundreds of applications across different use cases. This report introduces TabPFN-2.5, the next generation of our tabular foundation model, built for datasets with up to 50,000 data points and 2,000 features, a 20x increase in data cells compared to TabPFNv2. TabPFN-2.5 is now the leading method for the industry standard benchmark TabArena (which contains datasets with up to 100,000 training data points), substantially outperforming tuned tree-based models and matching the accuracy of AutoGluon 1.4, a complex four-hour tuned ensemble that even includes the previous TabPFNv2. Remarkably, default TabPFN-2.5 has a 100% win rate against default XGBoost on small to medium-sized classification datasets (<=10,000 data points, 500 features) and a 87% win rate on larger datasets up to 100K samples and 2K features (85% for regression). For production use cases, we introduce a new distillation engine that converts TabPFN-2.5 into a compact MLP or tree ensemble, preserving most of its accuracy while delivering orders-of-magnitude lower latency and plug-and-play deployment. This new release will immediately strengthen the performance of the many applications and methods already built on the TabPFN ecosystem.
Better by Default: Strong Pre-Tuned MLPs and Boosted Trees on Tabular Data
Jul 05, 2024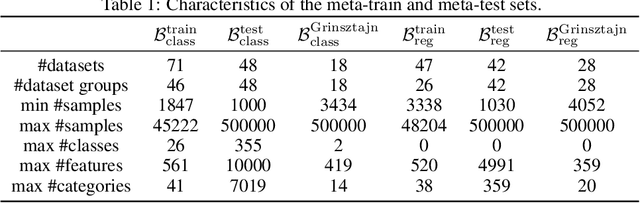
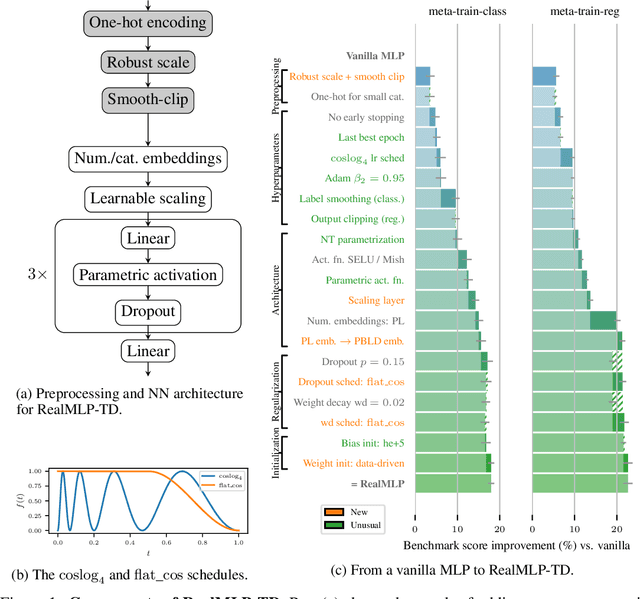
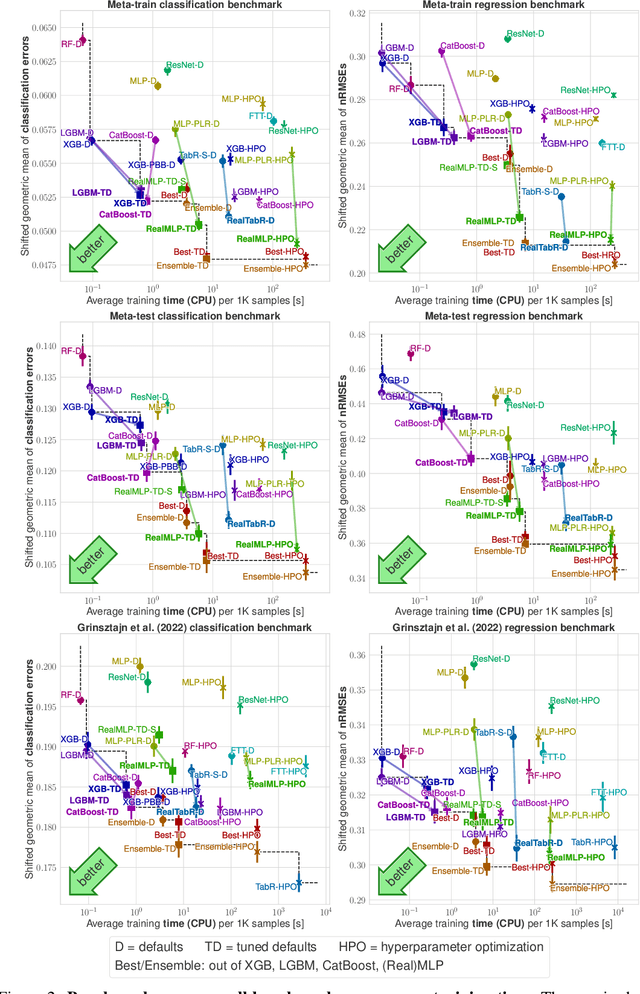
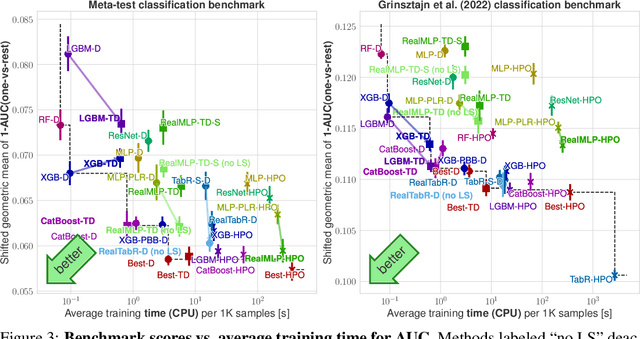
For classification and regression on tabular data, the dominance of gradient-boosted decision trees (GBDTs) has recently been challenged by often much slower deep learning methods with extensive hyperparameter tuning. We address this discrepancy by introducing (a) RealMLP, an improved multilayer perceptron (MLP), and (b) improved default parameters for GBDTs and RealMLP. We tune RealMLP and the default parameters on a meta-train benchmark with 71 classification and 47 regression datasets and compare them to hyperparameter-optimized versions on a disjoint meta-test benchmark with 48 classification and 42 regression datasets, as well as the GBDT-friendly benchmark by Grinsztajn et al. (2022). Our benchmark results show that RealMLP offers a better time-accuracy tradeoff than other neural nets and is competitive with GBDTs. Moreover, a combination of RealMLP and GBDTs with improved default parameters can achieve excellent results on medium-sized tabular datasets (1K--500K samples) without hyperparameter tuning.
CARTE: pretraining and transfer for tabular learning
Feb 26, 2024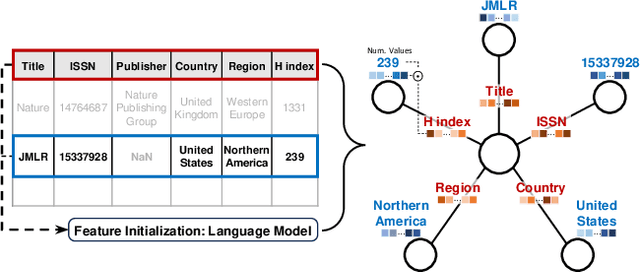



Pretrained deep-learning models are the go-to solution for images or text. However, for tabular data the standard is still to train tree-based models. Pre-training or transfer is a huge challenge as in general tables have columns about different quantities and naming conventions that vary vastly across sources. Data integration tackles correspondences across multiple sources: schema matching for columns, and entity matching for entries. We propose a neural architecture that does not need such matches. As a result, we can pretrain it on background data that has not been matched. The architecture - CARTE for Context Aware Representation of Table Entries - uses a graph representation of tabular (or relational) data to process tables with different columns, string embeddings of entries and columns names to model an open vocabulary, and a graph-attentional network to contextualize entries with column names and neighboring entries. An extensive benchmark shows that CARTE facilitates learning, outperforming a solid set of baselines including the best tree-based models. CARTE also enables joint learning across tables with unmatched columns, enhancing a small table with bigger ones. CARTE opens the door to large pretrained models embarking information for tabular data.
Vectorizing string entries for data processing on tables: when are larger language models better?
Dec 15, 2023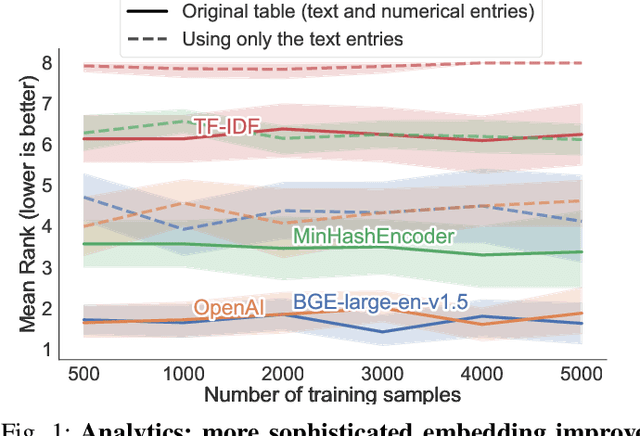
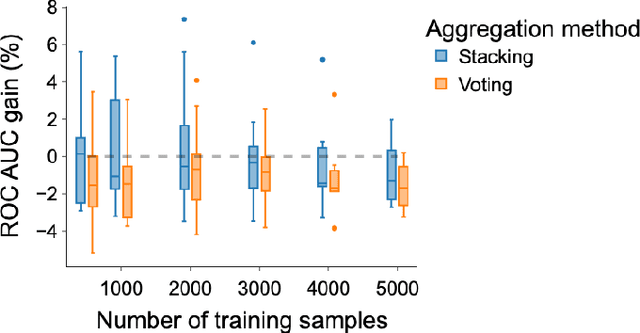

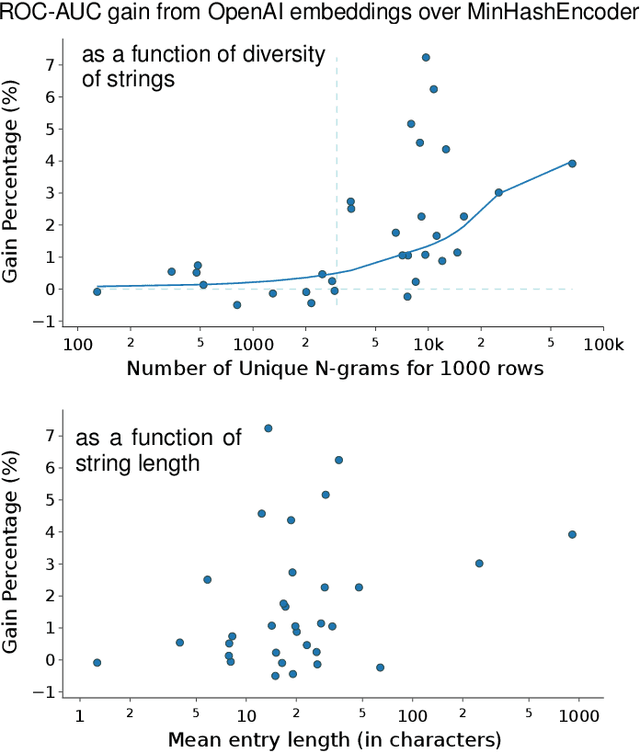
There are increasingly efficient data processing pipelines that work on vectors of numbers, for instance most machine learning models, or vector databases for fast similarity search. These require converting the data to numbers. While this conversion is easy for simple numerical and categorical entries, databases are strife with text entries, such as names or descriptions. In the age of large language models, what's the best strategies to vectorize tables entries, baring in mind that larger models entail more operational complexity? We study the benefits of language models in 14 analytical tasks on tables while varying the training size, as well as for a fuzzy join benchmark. We introduce a simple characterization of a column that reveals two settings: 1) a dirty categories setting, where strings share much similarities across entries, and conversely 2) a diverse entries setting. For dirty categories, pretrained language models bring little-to-no benefit compared to simpler string models. For diverse entries, we show that larger language models improve data processing. For these we investigate the complexity-performance tradeoffs and show that they reflect those of classic text embedding: larger models tend to perform better, but it is useful to fine tune them for embedding purposes.
Why do tree-based models still outperform deep learning on tabular data?
Jul 18, 2022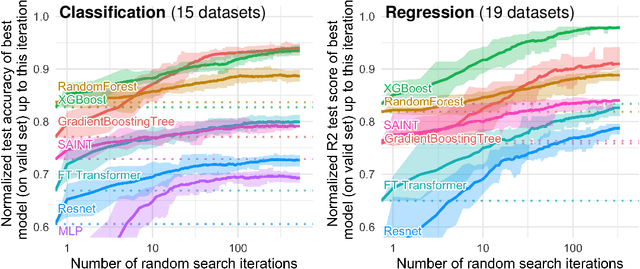
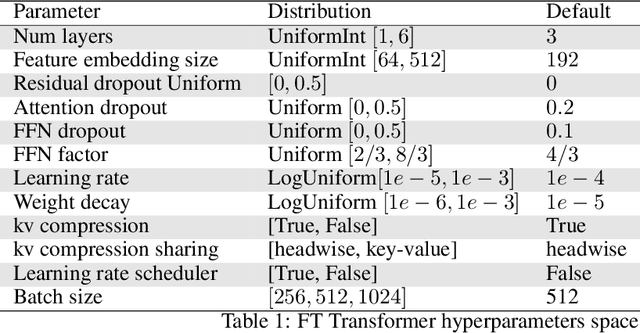
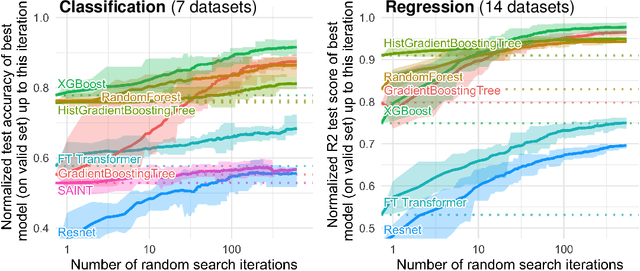
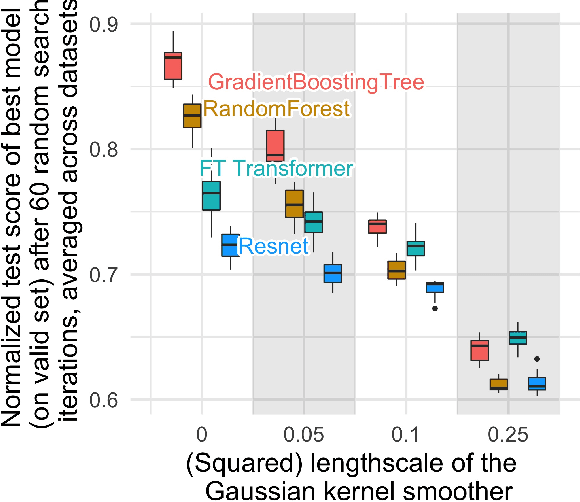
While deep learning has enabled tremendous progress on text and image datasets, its superiority on tabular data is not clear. We contribute extensive benchmarks of standard and novel deep learning methods as well as tree-based models such as XGBoost and Random Forests, across a large number of datasets and hyperparameter combinations. We define a standard set of 45 datasets from varied domains with clear characteristics of tabular data and a benchmarking methodology accounting for both fitting models and finding good hyperparameters. Results show that tree-based models remain state-of-the-art on medium-sized data ($\sim$10K samples) even without accounting for their superior speed. To understand this gap, we conduct an empirical investigation into the differing inductive biases of tree-based models and Neural Networks (NNs). This leads to a series of challenges which should guide researchers aiming to build tabular-specific NNs: 1. be robust to uninformative features, 2. preserve the orientation of the data, and 3. be able to easily learn irregular functions. To stimulate research on tabular architectures, we contribute a standard benchmark and raw data for baselines: every point of a 20 000 compute hours hyperparameter search for each learner.