 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARTE: pretraining and transfer for tabular learning
Paper and Code
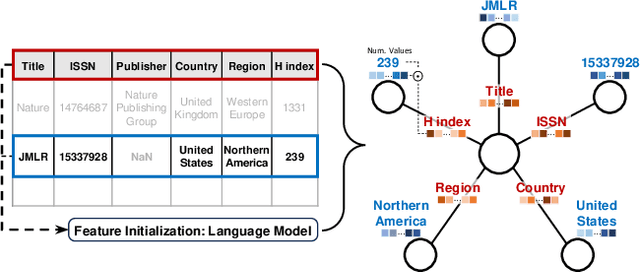



Pretrained deep-learning models are the go-to solution for images or text. However, for tabular data the standard is still to train tree-based models. Pre-training or transfer is a huge challenge as in general tables have columns about different quantities and naming conventions that vary vastly across sources. Data integration tackles correspondences across multiple sources: schema matching for columns, and entity matching for entries. We propose a neural architecture that does not need such matches. As a result, we can pretrain it on background data that has not been matched. The architecture - CARTE for Context Aware Representation of Table Entries - uses a graph representation of tabular (or relational) data to process tables with different columns, string embeddings of entries and columns names to model an open vocabulary, and a graph-attentional network to contextualize entries with column names and neighboring entries. An extensive benchmark shows that CARTE facilitates learning, outperforming a solid set of baselines including the best tree-based models. CARTE also enables joint learning across tables with unmatched columns, enhancing a small table with bigger ones. CARTE opens the door to large pretrained models embarking information for tabular data.