 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTable Foundation Models: on knowledge pre-training for tabular learning
May 20, 2025Table foundation models bring high hopes to data science: pre-trained on tabular data to embark knowledge or priors, they should facilitate downstream tasks on tables. One specific challenge is that of data semantics: numerical entries take their meaning from context, e.g., column name. Pre-trained neural networks that jointly model column names and table entries have recently boosted prediction accuracy. While these models outline the promises of world knowledge to interpret table values, they lack the convenience of popular foundation models in text or vision. Indeed, they must be fine-tuned to bring benefits, come with sizeable computation costs, and cannot easily be reused or combined with other architectures. Here we introduce TARTE, a foundation model that transforms tables to knowledge-enhanced vector representations using the string to capture semantics. Pre-trained on large relational data, TARTE yields representations that facilitate subsequent learning with little additional cost. These representations can be fine-tuned or combined with other learners, giving models that push the state-of-the-art prediction performance and improve the prediction/computation performance trade-off. Specialized to a task or a domain, TARTE gives domain-specific representations that facilitate further learning. Our study demonstrates an effective approach to knowledge pre-training for tabular learning.
CARTE: pretraining and transfer for tabular learning
Feb 26, 2024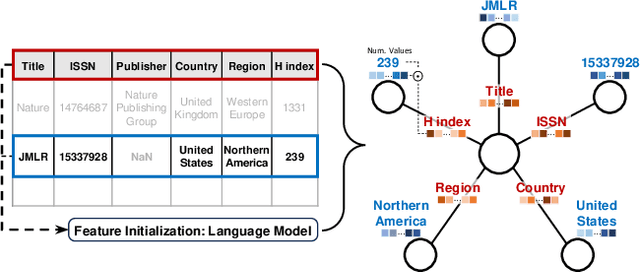



Pretrained deep-learning models are the go-to solution for images or text. However, for tabular data the standard is still to train tree-based models. Pre-training or transfer is a huge challenge as in general tables have columns about different quantities and naming conventions that vary vastly across sources. Data integration tackles correspondences across multiple sources: schema matching for columns, and entity matching for entries. We propose a neural architecture that does not need such matches. As a result, we can pretrain it on background data that has not been matched. The architecture - CARTE for Context Aware Representation of Table Entries - uses a graph representation of tabular (or relational) data to process tables with different columns, string embeddings of entries and columns names to model an open vocabulary, and a graph-attentional network to contextualize entries with column names and neighboring entries. An extensive benchmark shows that CARTE facilitates learning, outperforming a solid set of baselines including the best tree-based models. CARTE also enables joint learning across tables with unmatched columns, enhancing a small table with bigger ones. CARTE opens the door to large pretrained models embarking information for tabular data.
Vectorizing string entries for data processing on tables: when are larger language models better?
Dec 15, 2023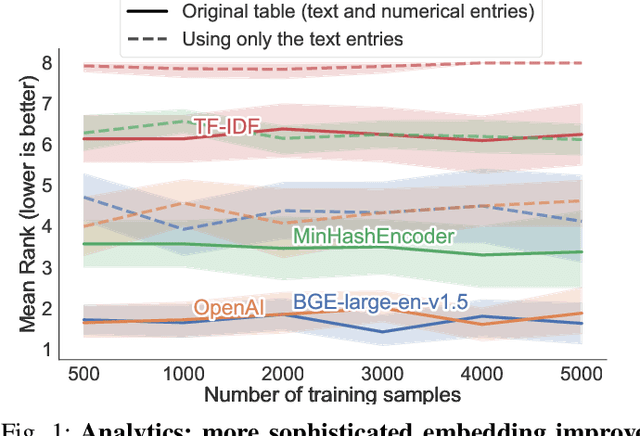
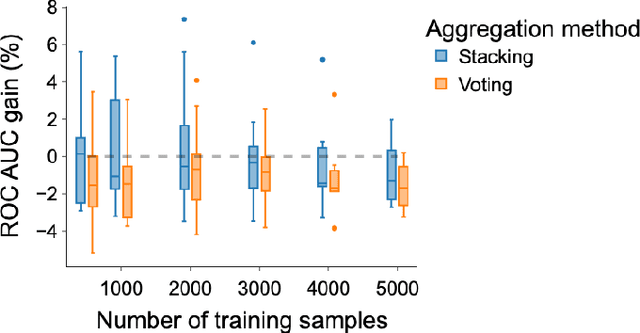

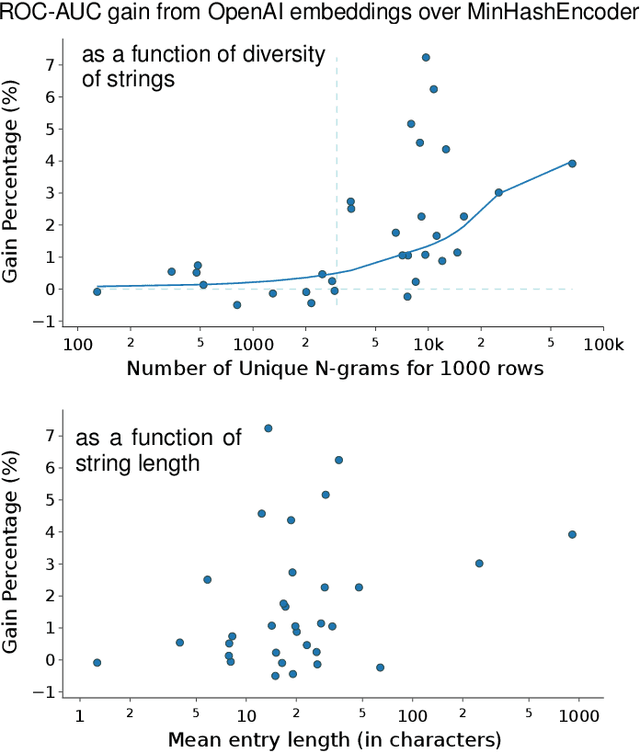
There are increasingly efficient data processing pipelines that work on vectors of numbers, for instance most machine learning models, or vector databases for fast similarity search. These require converting the data to numbers. While this conversion is easy for simple numerical and categorical entries, databases are strife with text entries, such as names or descriptions. In the age of large language models, what's the best strategies to vectorize tables entries, baring in mind that larger models entail more operational complexity? We study the benefits of language models in 14 analytical tasks on tables while varying the training size, as well as for a fuzzy join benchmark. We introduce a simple characterization of a column that reveals two settings: 1) a dirty categories setting, where strings share much similarities across entries, and conversely 2) a diverse entries setting. For dirty categories, pretrained language models bring little-to-no benefit compared to simpler string models. For diverse entries, we show that larger language models improve data processing. For these we investigate the complexity-performance tradeoffs and show that they reflect those of classic text embedding: larger models tend to perform better, but it is useful to fine tune them for embedding purposes.