 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning with Preference Constraints: A Benchmark for Language Models in Many-to-One Matching Markets
Sep 16, 2025Recent advances in reasoning with large language models (LLMs) have demonstrated strong performance on complex mathematical tasks, including combinatorial optimization. Techniques such as Chain-of-Thought and In-Context Learning have further enhanced this capability, making LLMs both powerful and accessible tools for a wide range of users, including non-experts. However, applying LLMs to matching problems, which require reasoning under preferential and structural constraints, remains underexplored. To address this gap, we introduce a novel benchmark of 369 instances of the College Admission Problem, a canonical example of a matching problem with preferences, to evaluate LLMs across key dimensions: feasibility, stability, and optimality. We employ this benchmark to assess the performance of several open-weight LLMs. Our results first reveal that while LLMs can satisfy certain constraints, they struggle to meet all evaluation criteria consistently. They also show that reasoning LLMs, like QwQ and GPT-oss, significantly outperform traditional models such as Llama, Qwen or Mistral, defined here as models used without any dedicated reasoning mechanisms. Moreover, we observed that LLMs reacted differently to the various prompting strategies tested, which include Chain-of-Thought, In-Context Learning and role-based prompting, with no prompt consistently offering the best performance. Finally, we report the performances from iterative prompting with auto-generated feedback and show that they are not monotonic; they can peak early and then significantly decline in later attempts. Overall, this work offers a new perspective on model reasoning performance and the effectiveness of prompting strategies in combinatorial optimization problems with preferential constraints.
Crossing Boundaries: Leveraging Semantic Divergences to Explore Cultural Novelty in Cooking Recipes
Mar 31, 2025Novelty modeling and detection is a core topic in Natural Language Processing (NLP), central to numerous tasks such as recommender systems and automatic summarization. It involves identifying pieces of text that deviate in some way from previously known information. However, novelty is also a crucial determinant of the unique perception of relevance and quality of an experience, as it rests upon each individual's understanding of the world. Social factors, particularly cultural background, profoundly influence perceptions of novelty and innovation. Cultural novelty arises from differences in salience and novelty as shaped by the distance between distinct communities. While cultural diversity has garnered increasing attention in artificial intelligence (AI), the lack of robust metrics for quantifying cultural novelty hinders a deeper understanding of these divergences. This gap limits quantifying and understanding cultural differences within computational frameworks. To address this, we propose an interdisciplinary framework that integrates knowledge from sociology and management. Central to our approach is GlobalFusion, a novel dataset comprising 500 dishes and approximately 100,000 cooking recipes capturing cultural adaptation from over 150 countries. By introducing a set of Jensen-Shannon Divergence metrics for novelty, we leverage this dataset to analyze textual divergences when recipes from one community are modified by another with a different cultural background. The results reveal significant correlations between our cultural novelty metrics and established cultural measures based on linguistic, religious, and geographical distances. Our findings highlight the potential of our framework to advance the understanding and measurement of cultural diversity in AI.
Embedding Cultural Diversity in Prototype-based Recommender Systems
Dec 18, 2024

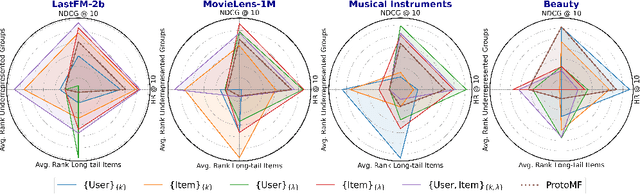

Popularity bias in recommender systems can increase cultural overrepresentation by favoring norms from dominant cultures and marginalizing underrepresented groups. This issue is critical for platforms offering cultural products, as they influence consumption patterns and human perceptions. In this work, we address popularity bias by identifying demographic biases within prototype-based matrix factorization methods. Using the country of origin as a proxy for cultural identity, we link this demographic attribute to popularity bias by refining the embedding space learning process. First, we propose filtering out irrelevant prototypes to improve representativity. Second, we introduce a regularization technique to enforce a uniform distribution of prototypes within the embedding space. Across four datasets, our results demonstrate a 27\% reduction in the average rank of long-tail items and a 2\% reduction in the average rank of items from underrepresented countries. Additionally, our model achieves a 2\% improvement in HitRatio@10 compared to the state-of-the-art, highlighting that fairness is enhanced without compromising recommendation quality. Moreover, the distribution of prototypes leads to more inclusive explanations by better aligning items with diverse prototypes.
Understanding Intrinsic Socioeconomic Biases in Large Language Models
May 28, 2024



Large Language Models (LLMs) are increasingly integrated into critical decision-making processes, such as loan approvals and visa applications, where inherent biases can lead to discriminatory outcomes. In this paper, we examine the nuanced relationship between demographic attributes and socioeconomic biases in LLMs, a crucial yet understudied area of fairness in LLMs. We introduce a novel dataset of one million English sentences to systematically quantify socioeconomic biases across various demographic groups. Our findings reveal pervasive socioeconomic biases in both established models such as GPT-2 and state-of-the-art models like Llama 2 and Falcon. We demonstrate that these biases are significantly amplified when considering intersectionality, with LLMs exhibiting a remarkable capacity to extract multiple demographic attributes from names and then correlate them with specific socioeconomic biases. This research highlights the urgent necessity for proactive and robust bias mitigation techniques to safeguard against discriminatory outcomes when deploying these powerful models in critical real-world applications.