 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Cultural Diversity in Prototype-based Recommender Systems
Dec 18, 2024

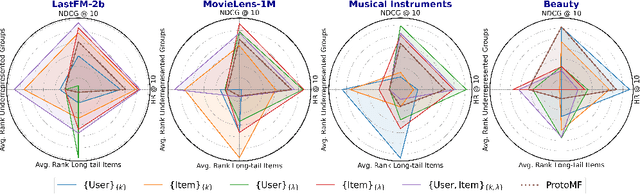

Popularity bias in recommender systems can increase cultural overrepresentation by favoring norms from dominant cultures and marginalizing underrepresented groups. This issue is critical for platforms offering cultural products, as they influence consumption patterns and human perceptions. In this work, we address popularity bias by identifying demographic biases within prototype-based matrix factorization methods. Using the country of origin as a proxy for cultural identity, we link this demographic attribute to popularity bias by refining the embedding space learning process. First, we propose filtering out irrelevant prototypes to improve representativity. Second, we introduce a regularization technique to enforce a uniform distribution of prototypes within the embedding space. Across four datasets, our results demonstrate a 27\% reduction in the average rank of long-tail items and a 2\% reduction in the average rank of items from underrepresented countries. Additionally, our model achieves a 2\% improvement in HitRatio@10 compared to the state-of-the-art, highlighting that fairness is enhanced without compromising recommendation quality. Moreover, the distribution of prototypes leads to more inclusive explanations by better aligning items with diverse prototypes.
Advancing Cultural Inclusivity: Optimizing Embedding Spaces for Balanced Music Recommendations
May 27, 2024Popularity bias in music recommendation systems -- where artists and tracks with the highest listen counts are recommended more often -- can also propagate biases along demographic and cultural axes. In this work, we identify these biases in recommendations for artists from underrepresented cultural groups in prototype-based matrix factorization methods. Unlike traditional matrix factorization methods, prototype-based approaches are interpretable. This allows us to directly link the observed bias in recommendations for minority artists (the effect) to specific properties of the embedding space (the cause). We mitigate popularity bias in music recommendation through capturing both users' and songs' cultural nuances in the embedding space. To address these challenges while maintaining recommendation quality, we propose two novel enhancements to the embedding space: i) we propose an approach to filter-out the irrelevant prototypes used to represent each user and item to improve generalizability, and ii) we introduce regularization techniques to reinforce a more uniform distribution of prototypes within the embedding space. Our results demonstrate significant improvements in reducing popularity bias and enhancing demographic and cultural fairness in music recommendations while achieving competitive -- if not better -- overall performance.
Tidying Up the Conversational Recommender Systems' Biases
Sep 05, 2023

The growing popularity of language models has sparked interest in conversational recommender systems (CRS) within both industry and research circles. However, concerns regarding biases in these systems have emerged. While individual components of CRS have been subject to bias studies, a literature gap remains in understanding specific biases unique to CRS and how these biases may be amplified or reduced when integrated into complex CRS models. In this paper, we provide a concise review of biases in CRS by surveying recent literature. We examine the presence of biases throughout the system's pipeline and consider the challenges that arise from combining multiple models. Our study investigates biases in classic recommender systems and their relevance to CRS. Moreover, we address specific biases in CRS, considering variations with and without natural language understanding capabilities, along with biases related to dialogue systems and language models. Through our findings, we highlight the necessity of adopting a holistic perspective when dealing with biases in complex CRS models.