 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness and Robustness in Invariant Learning: A Case Study in Toxicity Classification
Dec 02, 2020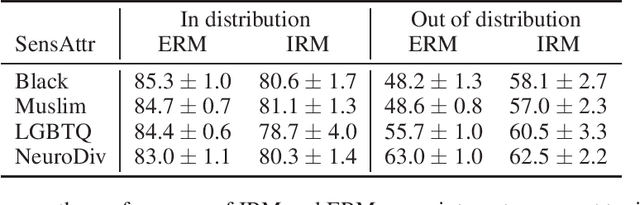
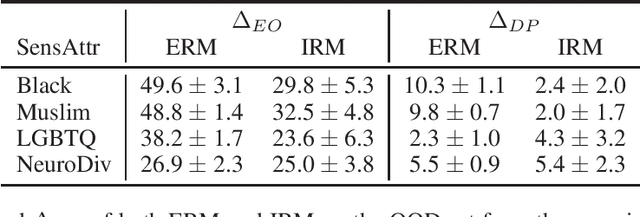


Robustness is of central importance in machine learning and has given rise to the fields of domain generalization and invariant learning, which are concerned with improving performance on a test distribution distinct from but related to the training distribution. In light of recent work suggesting an intimate connection between fairness and robustness, we investigate whether algorithms from robust ML can be used to improve the fairness of classifiers that are trained on biased data and tested on unbiased data. We apply Invariant Risk Minimization (IRM), a domain generalization algorithm that employs a causal discovery inspired method to find robust predictors, to the task of fairly predicting the toxicity of internet comments. We show that IRM achieves better out-of-distribution accuracy and fairness than Empirical Risk Minimization (ERM) methods, and analyze both the difficulties that arise when applying IRM in practice and the conditions under which IRM will likely be effective in this scenario. We hope that this work will inspire further studies of how robust machine learning methods relate to algorithmic fairness.