 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenefits of Overparameterization in Single-Layer Latent Variable Generative Models
Paper and Code

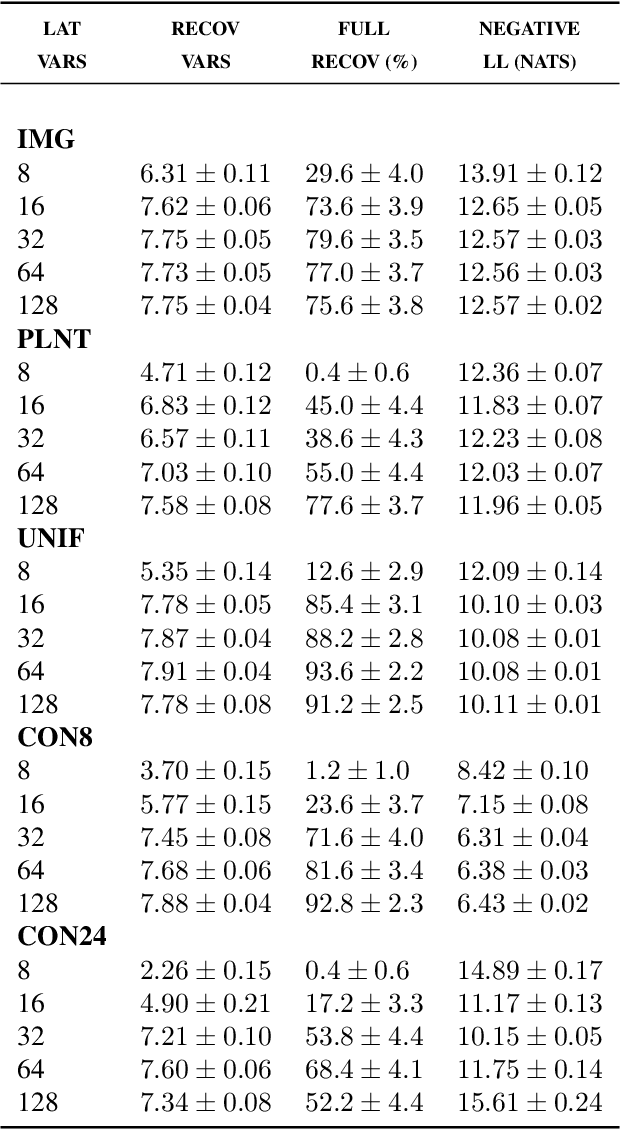
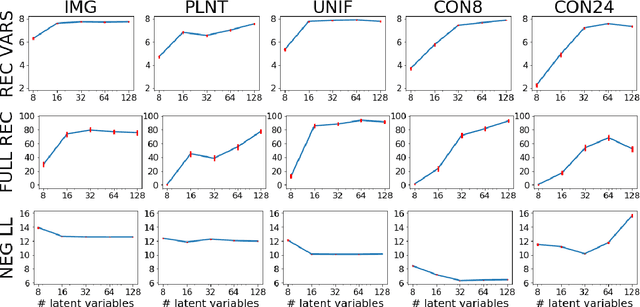
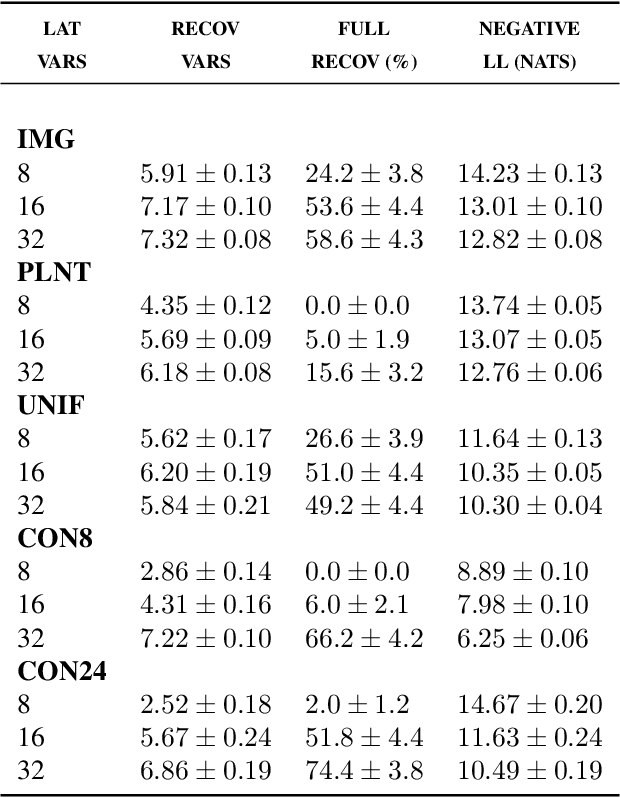
One of the most surprising and exciting discoveries in supervising learning was the benefit of overparametrization (i.e. training a very large model) to improving the optimization landscape of a problem, with minimal effect on statistical performance (i.e. generalization). In contrast, unsupervised settings have been under-explored, despite the fact that it has been observed that overparameterization can be helpful as early as Dasgupta & Schulman (2007). In this paper, we perform an exhaustive study of different aspects of overparameterization in unsupervised learning via synthetic and semi-synthetic experiments. We discuss benefits to different metrics of success (held-out log-likelihood, recovering the parameters of the ground-truth model), sensitivity to variations of the training algorithm, and behavior as the amount of overparameterization increases. We find that, when learning using methods such as variational inference, larger models can significantly increase the number of ground truth latent variables recovered.