 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLasso and Partially-Rotated Designs
May 16, 2025We consider the sparse linear regression model $\mathbf{y} = X \beta +\mathbf{w}$, where $X \in \mathbb{R}^{n \times d}$ is the design, $\beta \in \mathbb{R}^{d}$ is a $k$-sparse secret, and $\mathbf{w} \sim N(0, I_n)$ is the noise. Given input $X$ and $\mathbf{y}$, the goal is to estimate $\beta$. In this setting, the Lasso estimate achieves prediction error $O(k \log d / \gamma n)$, where $\gamma$ is the restricted eigenvalue (RE) constant of $X$ with respect to $\mathrm{support}(\beta)$. In this paper, we introduce a new $\textit{semirandom}$ family of designs -- which we call $\textit{partially-rotated}$ designs -- for which the RE constant with respect to the secret is bounded away from zero even when a subset of the design columns are arbitrarily correlated among themselves. As an example of such a design, suppose we start with some arbitrary $X$, and then apply a random rotation to the columns of $X$ indexed by $\mathrm{support}(\beta)$. Let $\lambda_{\min}$ be the smallest eigenvalue of $\frac{1}{n} X_{\mathrm{support}(\beta)}^\top X_{\mathrm{support}(\beta)}$, where $X_{\mathrm{support}(\beta)}$ is the restriction of $X$ to the columns indexed by $\mathrm{support}(\beta)$. In this setting, our results imply that Lasso achieves prediction error $O(k \log d / \lambda_{\min} n)$ with high probability. This prediction error bound is independent of the arbitrary columns of $X$ not indexed by $\mathrm{support}(\beta)$, and is as good as if all of these columns were perfectly well-conditioned. Technically, our proof reduces to showing that matrices with a certain deterministic property -- which we call $\textit{restricted normalized orthogonality}$ (RNO) -- lead to RE constants that are independent of a subset of the matrix columns. This property is similar but incomparable with the restricted orthogonality condition of [CT05].
Dimension Reduction via Sum-of-Squares and Improved Clustering Algorithms for Non-Spherical Mixtures
Nov 19, 2024We develop a new approach for clustering non-spherical (i.e., arbitrary component covariances) Gaussian mixture models via a subroutine, based on the sum-of-squares method, that finds a low-dimensional separation-preserving projection of the input data. Our method gives a non-spherical analog of the classical dimension reduction, based on singular value decomposition, that forms a key component of the celebrated spherical clustering algorithm of Vempala and Wang [VW04] (in addition to several other applications). As applications, we obtain an algorithm to (1) cluster an arbitrary total-variation separated mixture of $k$ centered (i.e., zero-mean) Gaussians with $n\geq \operatorname{poly}(d) f(w_{\min}^{-1})$ samples and $\operatorname{poly}(n)$ time, and (2) cluster an arbitrary total-variation separated mixture of $k$ Gaussians with identical but arbitrary unknown covariance with $n \geq d^{O(\log w_{\min}^{-1})} f(w_{\min}^{-1})$ samples and $n^{O(\log w_{\min}^{-1})}$ time. Here, $w_{\min}$ is the minimum mixing weight of the input mixture, and $f$ does not depend on the dimension $d$. Our algorithms naturally extend to tolerating a dimension-independent fraction of arbitrary outliers. Before this work, the techniques in the state-of-the-art non-spherical clustering algorithms needed $d^{O(k)} f(w_{\min}^{-1})$ time and samples for clustering such mixtures. Our results may come as a surprise in the context of the $d^{\Omega(k)}$ statistical query lower bound [DKS17] for clustering non-spherical Gaussian mixtures. While this result is usually thought to rule out $d^{o(k)}$ cost algorithms for the problem, our results show that the lower bounds can in fact be circumvented for a remarkably general class of Gaussian mixtures.
Robust Mixture Learning when Outliers Overwhelm Small Groups
Jul 22, 2024



We study the problem of estimating the means of well-separated mixtures when an adversary may add arbitrary outliers. While strong guarantees are available when the outlier fraction is significantly smaller than the minimum mixing weight, much less is known when outliers may crowd out low-weight clusters - a setting we refer to as list-decodable mixture learning (LD-ML). In this case, adversarial outliers can simulate additional spurious mixture components. Hence, if all means of the mixture must be recovered up to a small error in the output list, the list size needs to be larger than the number of (true) components. We propose an algorithm that obtains order-optimal error guarantees for each mixture mean with a minimal list-size overhead, significantly improving upon list-decodable mean estimation, the only existing method that is applicable for LD-ML. Although improvements are observed even when the mixture is non-separated, our algorithm achieves particularly strong guarantees when the mixture is separated: it can leverage the mixture structure to partially cluster the samples before carefully iterating a base learner for list-decodable mean estimation at different scales.
Computational-Statistical Gaps for Improper Learning in Sparse Linear Regression
Feb 21, 2024We study computational-statistical gaps for improper learning in sparse linear regression. More specifically, given $n$ samples from a $k$-sparse linear model in dimension $d$, we ask what is the minimum sample complexity to efficiently (in time polynomial in $d$, $k$, and $n$) find a potentially dense estimate for the regression vector that achieves non-trivial prediction error on the $n$ samples. Information-theoretically this can be achieved using $\Theta(k \log (d/k))$ samples. Yet, despite its prominence in the literature, there is no polynomial-time algorithm known to achieve the same guarantees using less than $\Theta(d)$ samples without additional restrictions on the model. Similarly, existing hardness results are either restricted to the proper setting, in which the estimate must be sparse as well, or only apply to specific algorithms. We give evidence that efficient algorithms for this task require at least (roughly) $\Omega(k^2)$ samples. In particular, we show that an improper learning algorithm for sparse linear regression can be used to solve sparse PCA problems (with a negative spike) in their Wishart form, in regimes in which efficient algorithms are widely believed to require at least $\Omega(k^2)$ samples. We complement our reduction with low-degree and statistical query lower bounds for the sparse PCA problems from which we reduce. Our hardness results apply to the (correlated) random design setting in which the covariates are drawn i.i.d. from a mean-zero Gaussian distribution with unknown covariance.
Beyond Parallel Pancakes: Quasi-Polynomial Time Guarantees for Non-Spherical Gaussian Mixtures
Dec 10, 2021We consider mixtures of $k\geq 2$ Gaussian components with unknown means and unknown covariance (identical for all components) that are well-separated, i.e., distinct components have statistical overlap at most $k^{-C}$ for a large enough constant $C\ge 1$. Previous statistical-query lower bounds [DKS17] give formal evidence that even distinguishing such mixtures from (pure) Gaussians may be exponentially hard (in $k$). We show that this kind of hardness can only appear if mixing weights are allowed to be exponentially small, and that for polynomially lower bounded mixing weights non-trivial algorithmic guarantees are possible in quasi-polynomial time. Concretely, we develop an algorithm based on the sum-of-squares method with running time quasi-polynomial in the minimum mixing weight. The algorithm can reliably distinguish between a mixture of $k\ge 2$ well-separated Gaussian components and a (pure) Gaussian distribution. As a certificate, the algorithm computes a bipartition of the input sample that separates a pair of mixture components, i.e., both sides of the bipartition contain most of the sample points of at least one component. For the special case of colinear means, our algorithm outputs a $k$ clustering of the input sample that is approximately consistent with the components of the mixture. A significant challenge for our results is that they appear to be inherently sensitive to small fractions of adversarial outliers unlike most previous results for Gaussian mixtures. The reason is that such outliers can simulate exponentially small mixing weights even for mixtures with polynomially lower bounded mixing weights. A key technical ingredient is a characterization of separating directions for well-separated Gaussian components in terms of ratios of polynomials that correspond to moments of two carefully chosen orders logarithmic in the minimum mixing weight.
Learning Restricted Boltzmann Machines with Few Latent Variables
Jun 07, 2020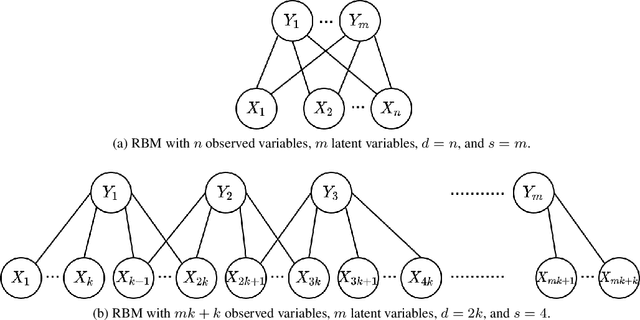
Restricted Boltzmann Machines (RBMs) are a common family of undirected graphical models with latent variables. An RBM is described by a bipartite graph, with all observed variables in one layer and all latent variables in the other. We consider the task of learning an RBM given samples generated according to it. The best algorithms for this task currently have time complexity $\tilde{O}(n^2)$ for ferromagnetic RBMs (i.e., with attractive potentials) but $\tilde{O}(n^d)$ for general RBMs, where $n$ is the number of observed variables and $d$ is the maximum degree of a latent variable. Let the MRF neighborhood of an observed variable be its neighborhood in the Markov Random Field of the marginal distribution of the observed variables. In this paper, we give an algorithm for learning general RBMs with time complexity $\tilde{O}(n^{2^s+1})$, where $s$ is the maximum number of latent variables connected to the MRF neighborhood of an observed variable. This represents an improvement when $s < \log_2 (d-1)$, which is satisfied by many classes of RBMs with "few latent variables''. Furthermore, we give a version of this learning algorithm that recovers a model with small prediction error and whose sample complexity is independent of the minimum potential in the Markov Random Field of the observed variables. This is of interest because the sample complexity of current algorithms scales with the inverse of the minimum potential, which cannot be controlled in terms of natural properties of the RBM.
Benefits of Overparameterization in Single-Layer Latent Variable Generative Models
Jun 28, 2019
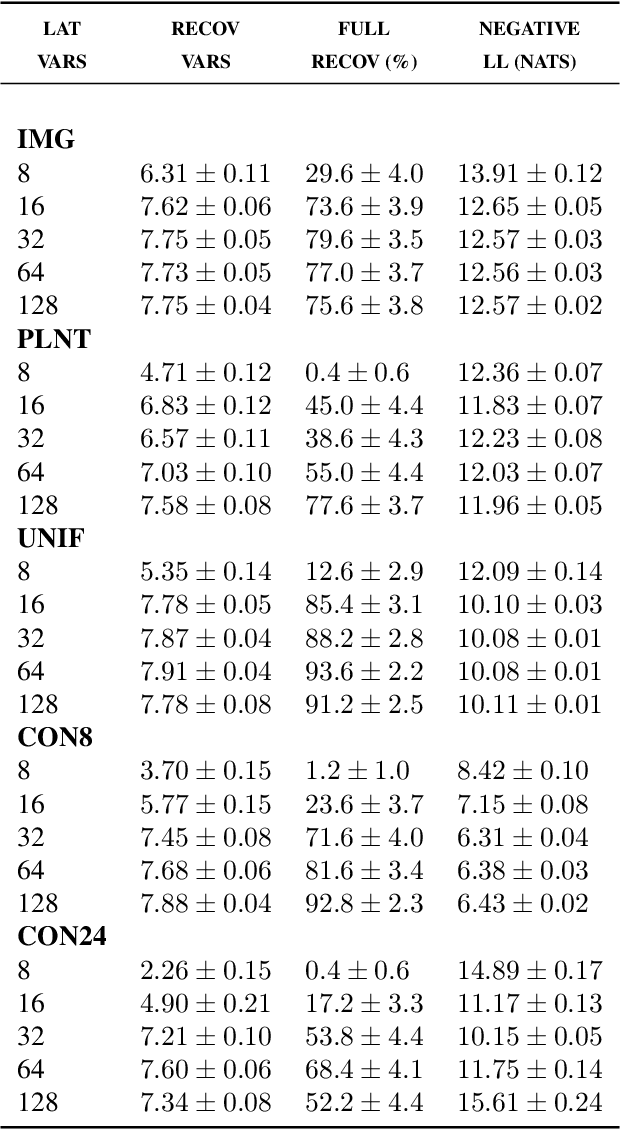
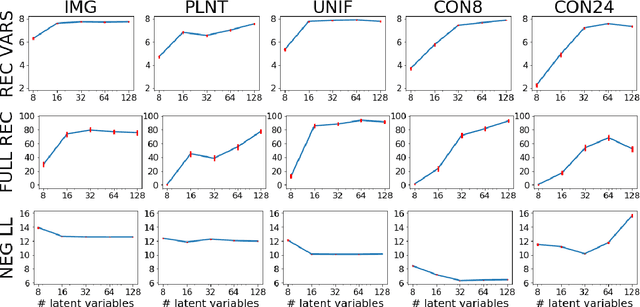
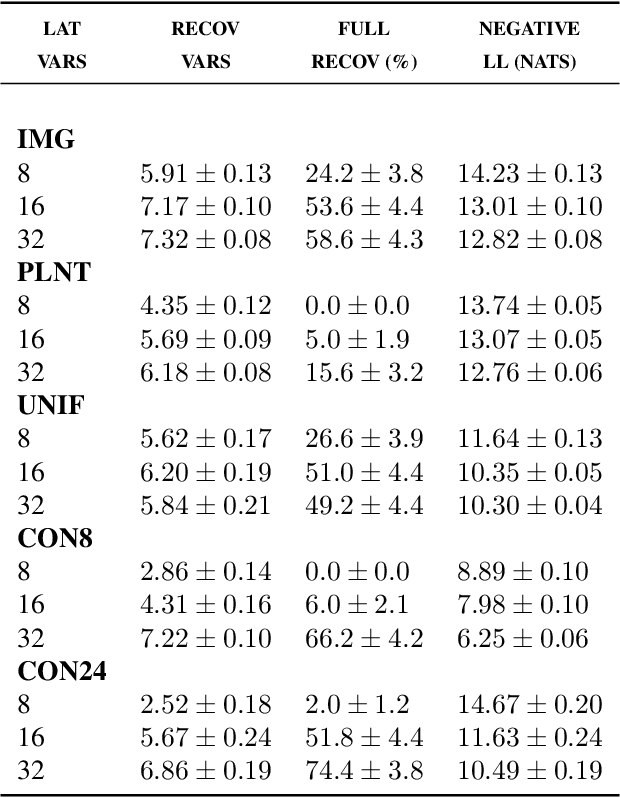
One of the most surprising and exciting discoveries in supervising learning was the benefit of overparametrization (i.e. training a very large model) to improving the optimization landscape of a problem, with minimal effect on statistical performance (i.e. generalization). In contrast, unsupervised settings have been under-explored, despite the fact that it has been observed that overparameterization can be helpful as early as Dasgupta & Schulman (2007). In this paper, we perform an exhaustive study of different aspects of overparameterization in unsupervised learning via synthetic and semi-synthetic experiments. We discuss benefits to different metrics of success (held-out log-likelihood, recovering the parameters of the ground-truth model), sensitivity to variations of the training algorithm, and behavior as the amount of overparameterization increases. We find that, when learning using methods such as variational inference, larger models can significantly increase the number of ground truth latent variables recovered.