 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Dense Retrieval's Few-Shot Ability
Paper and Code
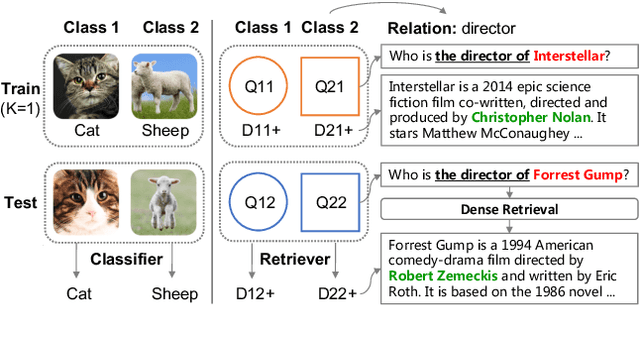
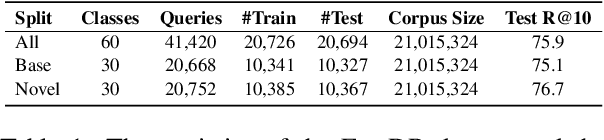

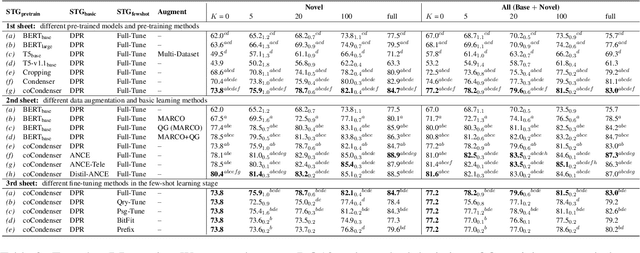
Few-shot dense retrieval (DR) aims to effectively generalize to novel search scenarios by learning a few samples. Despite its importance, there is little study on specialized datasets and standardized evaluation protocols. As a result, current methods often resort to random sampling from supervised datasets to create "few-data" setups and employ inconsistent training strategies during evaluations, which poses a challenge in accurately comparing recent progress. In this paper, we propose a customized FewDR dataset and a unified evaluation benchmark. Specifically, FewDR employs class-wise sampling to establish a standardized "few-shot" setting with finely-defined classes, reducing variability in multiple sampling rounds. Moreover, the dataset is disjointed into base and novel classes, allowing DR models to be continuously trained on ample data from base classes and a few samples in novel classes. This benchmark eliminates the risk of novel class leakage, providing a reliable estimation of the DR model's few-shot ability. Our extensive empirical results reveal that current state-of-the-art DR models still face challenges in the standard few-shot scene. Our code and data will be open-sourced at https://github.com/OpenMatch/ANCE-Tele.