 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive $\mathcal{J}$-Invariant Self-supervised Learning for Low-Dose CT Denoising
Jan 28, 2026Self-supervised learning has been increasingly investigated for low-dose computed tomography (LDCT) image denoising, as it alleviates the dependence on paired normal-dose CT (NDCT) data, which are often difficult to collect. However, many existing self-supervised blind-spot denoising methods suffer from training inefficiencies and suboptimal performance due to restricted receptive fields. To mitigate this issue, we propose a novel Progressive $\mathcal{J}$-invariant Learning that maximizes the use of $\mathcal{J}$-invariant to enhance LDCT denoising performance. We introduce a step-wise blind-spot denoising mechanism that enforces conditional independence in a progressive manner, enabling more fine-grained learning for denoising. Furthermore, we explicitly inject a combination of controlled Gaussian and Poisson noise during training to regularize the denoising process and mitigate overfitting. Extensive experiments on the Mayo LDCT dataset demonstrate that the proposed method consistently outperforms existing self-supervised approaches and achieves performance comparable to, or better than, several representative supervised denoising methods.
Progressive self-supervised blind-spot denoising method for LDCT denoising
Jan 20, 2026Self-supervised learning is increasingly investigated for low-dose computed tomography (LDCT) image denoising, as it alleviates the dependence on paired normal-dose CT (NDCT) data, which are often difficult to acquire in clinical practice. In this paper, we propose a novel self-supervised training strategy that relies exclusively on LDCT images. We introduce a step-wise blind-spot denoising mechanism that enforces conditional independence in a progressive manner, enabling more fine-grained denoising learning. In addition, we add Gaussian noise to LDCT images, which acts as a regularization and mitigates overfitting. Extensive experiments on the Mayo LDCT dataset demonstrate that the proposed method consistently outperforms existing self-supervised approaches and achieves performance comparable to, or better than, several representative supervised denoising methods.
Graph Context Transformation Learning for Progressive Correspondence Pruning
Dec 26, 2023
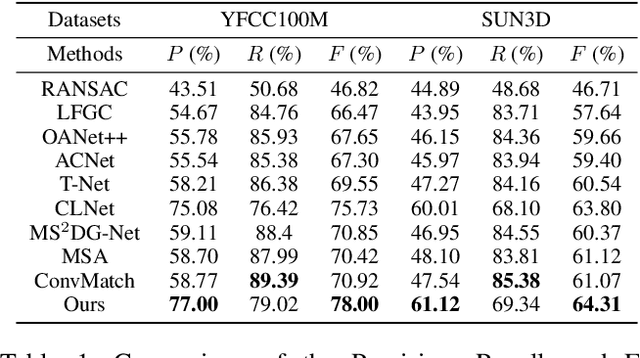
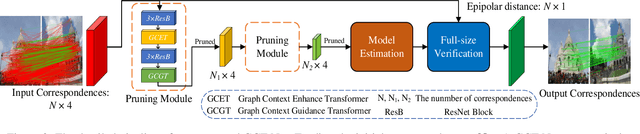
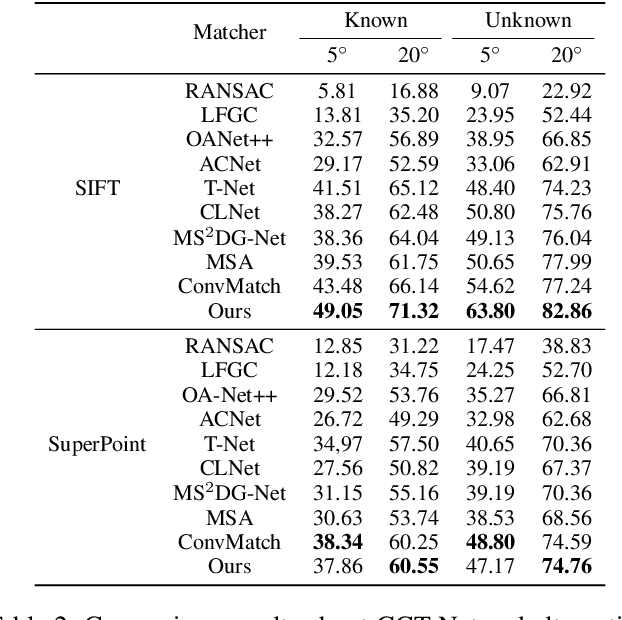
Most of existing correspondence pruning methods only concentrate on gathering the context information as much as possible while neglecting effective ways to utilize such information. In order to tackle this dilemma, in this paper we propose Graph Context Transformation Network (GCT-Net) enhancing context information to conduct consensus guidance for progressive correspondence pruning. Specifically, we design the Graph Context Enhance Transformer which first generates the graph network and then transforms it into multi-branch graph contexts. Moreover, it employs self-attention and cross-attention to magnify characteristics of each graph context for emphasizing the unique as well as shared essential information. To further apply the recalibrated graph contexts to the global domain, we propose the Graph Context Guidance Transformer. This module adopts a confident-based sampling strategy to temporarily screen high-confidence vertices for guiding accurate classification by searching global consensus between screened vertices and remaining ones. The extensive experimental results on outlier removal and relative pose estimation clearly demonstrate the superior performance of GCT-Net compared to state-of-the-art methods across outdoor and indoor datasets. The source code will be available at: https://github.com/guobaoxiao/GCT-Net/.