 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive $\mathcal{J}$-Invariant Self-supervised Learning for Low-Dose CT Denoising
Jan 28, 2026Self-supervised learning has been increasingly investigated for low-dose computed tomography (LDCT) image denoising, as it alleviates the dependence on paired normal-dose CT (NDCT) data, which are often difficult to collect. However, many existing self-supervised blind-spot denoising methods suffer from training inefficiencies and suboptimal performance due to restricted receptive fields. To mitigate this issue, we propose a novel Progressive $\mathcal{J}$-invariant Learning that maximizes the use of $\mathcal{J}$-invariant to enhance LDCT denoising performance. We introduce a step-wise blind-spot denoising mechanism that enforces conditional independence in a progressive manner, enabling more fine-grained learning for denoising. Furthermore, we explicitly inject a combination of controlled Gaussian and Poisson noise during training to regularize the denoising process and mitigate overfitting. Extensive experiments on the Mayo LDCT dataset demonstrate that the proposed method consistently outperforms existing self-supervised approaches and achieves performance comparable to, or better than, several representative supervised denoising methods.
Systematic Evaluation of Machine-Generated Reasoning and PHQ-9 Labeling for Depression Detection Using Large Language Models
May 21, 2025Recent research leverages large language models (LLMs) for early mental health detection, such as depression, often optimized with machine-generated data. However, their detection may be subject to unknown weaknesses. Meanwhile, quality control has not been applied to these generated corpora besides limited human verifications. Our goal is to systematically evaluate LLM reasoning and reveal potential weaknesses. To this end, we first provide a systematic evaluation of the reasoning over machine-generated detection and interpretation. Then we use the models' reasoning abilities to explore mitigation strategies for enhanced performance. Specifically, we do the following: A. Design an LLM instruction strategy that allows for systematic analysis of the detection by breaking down the task into several subtasks. B. Design contrastive few-shot and chain-of-thought prompts by selecting typical positive and negative examples of detection reasoning. C. Perform human annotation for the subtasks identified in the first step and evaluate the performance. D. Identify human-preferred detection with desired logical reasoning from the few-shot generation and use them to explore different optimization strategies. We conducted extensive comparisons on the DepTweet dataset across the following subtasks: 1. identifying whether the speaker is describing their own depression; 2. accurately detecting the presence of PHQ-9 symptoms, and 3. finally, detecting depression. Human verification of statistical outliers shows that LLMs demonstrate greater accuracy in analyzing and detecting explicit language of depression as opposed to implicit expressions of depression. Two optimization methods are used for performance enhancement and reduction of the statistic bias: supervised fine-tuning (SFT) and direct preference optimization (DPO). Notably, the DPO approach achieves significant performance improvement.
Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
Dec 10, 2021
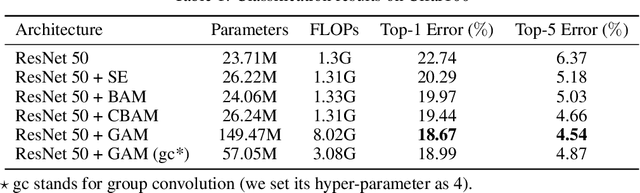
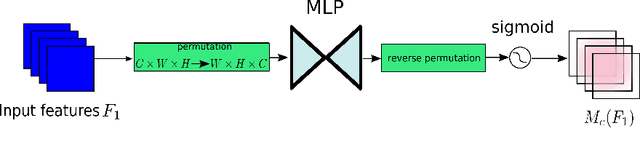
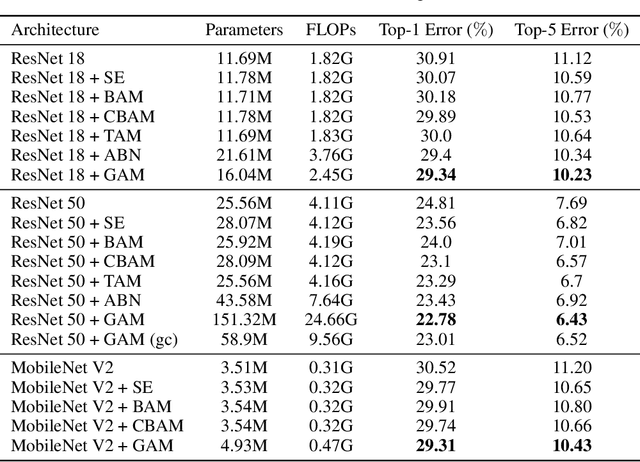
A variety of attention mechanisms have been studied to improve the performance of various computer vision tasks. However, the prior methods overlooked the significance of retaining the information on both channel and spatial aspects to enhance the cross-dimension interactions. Therefore, we propose a global attention mechanism that boosts the performance of deep neural networks by reducing information reduction and magnifying the global interactive representations. We introduce 3D-permutation with multilayer-perceptron for channel attention alongside a convolutional spatial attention submodule. The evaluation of the proposed mechanism for the image classification task on CIFAR-100 and ImageNet-1K indicates that our method stably outperforms several recent attention mechanisms with both ResNet and lightweight MobileNet.
NAM: Normalization-based Attention Module
Nov 24, 2021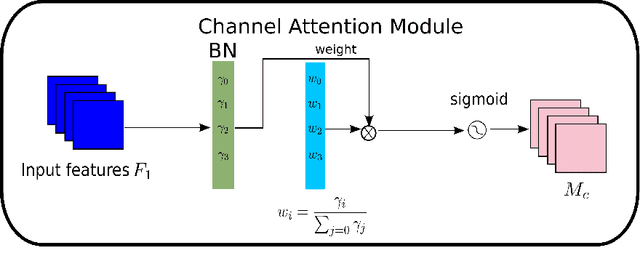
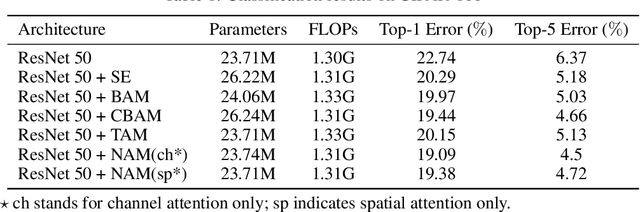
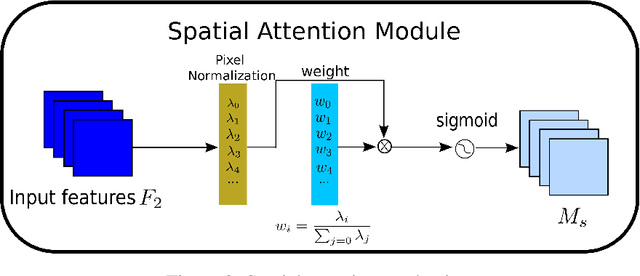
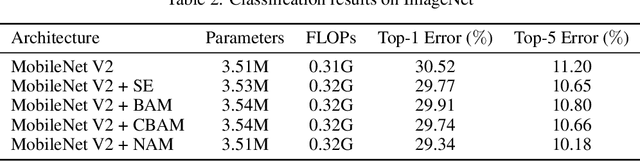
Recognizing less salient features is the key for model compression. However, it has not been investigated in the revolutionary attention mechanisms. In this work, we propose a novel normalization-based attention module (NAM), which suppresses less salient weights. It applies a weight sparsity penalty to the attention modules, thus, making them more computational efficient while retaining similar performance. A comparison with three other attention mechanisms on both Resnet and Mobilenet indicates that our method results in higher accuracy. Code for this paper can be publicly accessed at https://github.com/Christian-lyc/NAM.