 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition Engineering: Boosting Large Language Models through Positional Information Manipulation
Apr 17, 2024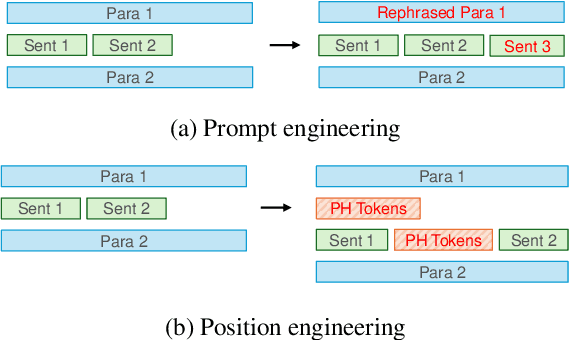
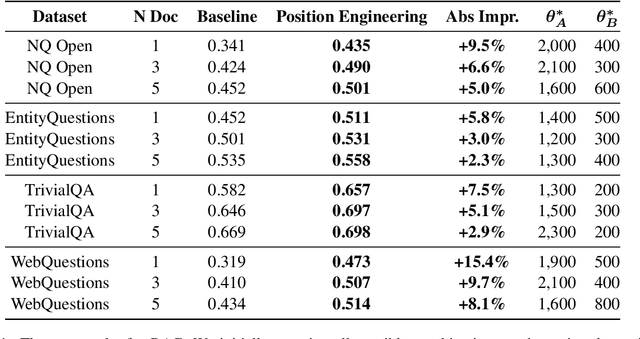
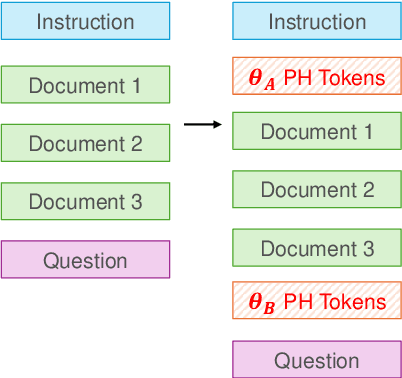
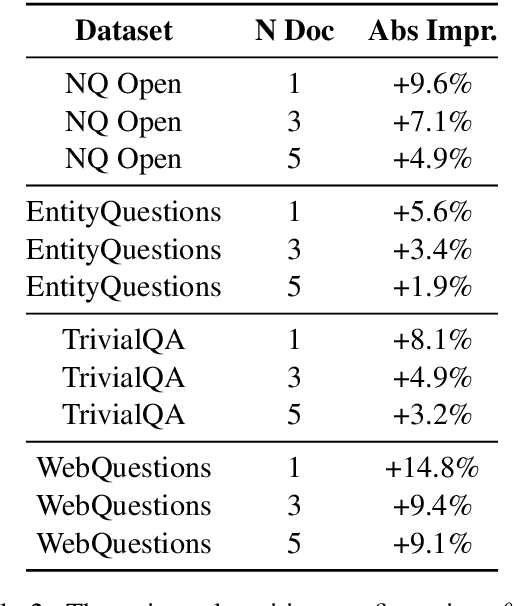
The performance of large language models (LLMs) is significantly influenced by the quality of the prompts provided. In response, researchers have developed enormous prompt engineering strategies aimed at modifying the prompt text to enhance task performance. In this paper, we introduce a novel technique termed position engineering, which offers a more efficient way to guide large language models. Unlike prompt engineering, which requires substantial effort to modify the text provided to LLMs, position engineering merely involves altering the positional information in the prompt without modifying the text itself. We have evaluated position engineering in two widely-used LLM scenarios: retrieval-augmented generation (RAG) and in-context learning (ICL). Our findings show that position engineering substantially improves upon the baseline in both cases. Position engineering thus represents a promising new strategy for exploiting the capabilities of large language models.
End-to-End Word-Level Pronunciation Assessment with MASK Pre-training
Jun 05, 2023



Pronunciation assessment is a major challenge in the computer-aided pronunciation training system, especially at the word (phoneme)-level. To obtain word (phoneme)-level scores, current methods usually rely on aligning components to obtain acoustic features of each word (phoneme), which limits the performance of assessment to the accuracy of alignments. Therefore, to address this problem, we propose a simple yet effective method, namely \underline{M}asked pre-training for \underline{P}ronunciation \underline{A}ssessment (MPA). Specifically, by incorporating a mask-predict strategy, our MPA supports end-to-end training without leveraging any aligning components and can solve misalignment issues to a large extent during prediction. Furthermore, we design two evaluation strategies to enable our model to conduct assessments in both unsupervised and supervised settings. Experimental results on SpeechOcean762 dataset demonstrate that MPA could achieve better performance than previous methods, without any explicit alignment. In spite of this, MPA still has some limitations, such as requiring more inference time and reference text. They expect to be addressed in future work.
Improving Hypernasality Estimation with Automatic Speech Recognition in Cleft Palate Speech
Aug 10, 2022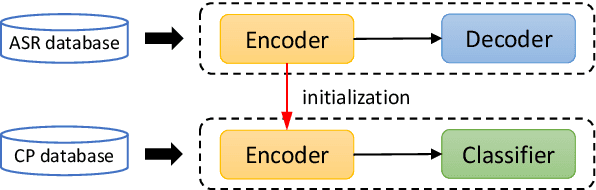
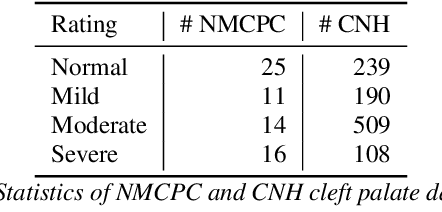
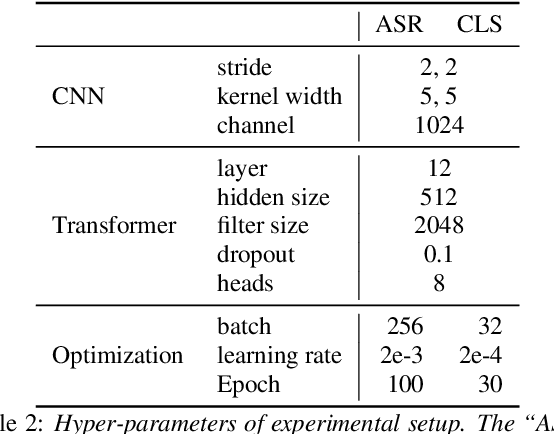
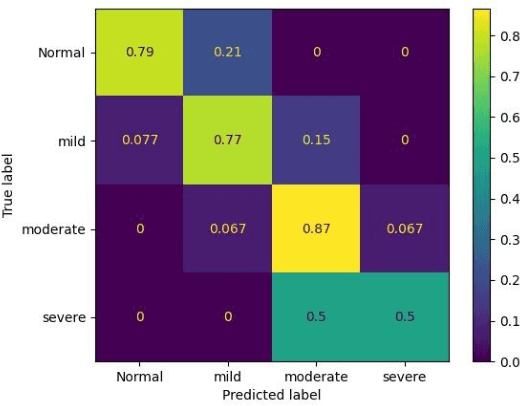
Hypernasality is an abnormal resonance in human speech production, especially in patients with craniofacial anomalies such as cleft palate. In clinical application, hypernasality estimation is crucial in cleft palate diagnosis, as its results determine the subsequent surgery and additional speech therapy. Therefore, designing an automatic hypernasality assessment method will facilitate speech-language pathologists to make precise diagnoses. Existing methods for hypernasality estimation only conduct acoustic analysis based on low-resource cleft palate dataset, by using statistical or neural network-based features. In this paper, we propose a novel approach that uses automatic speech recognition model to improve hypernasality estimation. Specifically, we first pre-train an encoder-decoder framework in an automatic speech recognition (ASR) objective by using speech-to-text dataset, and then fine-tune ASR encoder on the cleft palate dataset for hypernasality estimation. Benefiting from such design, our model for hypernasality estimation can enjoy the advantages of ASR model: 1) compared with low-resource cleft palate dataset, the ASR task usually includes large-scale speech data in the general domain, which enables better model generalization; 2) the text annotations in ASR dataset guide model to extract better acoustic features. Experimental results on two cleft palate datasets demonstrate that our method achieves superior performance compared with previous approaches.