 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Spike Depth Estimation via Cross-modality Cross-domain Knowledge Transfer
Paper and Code
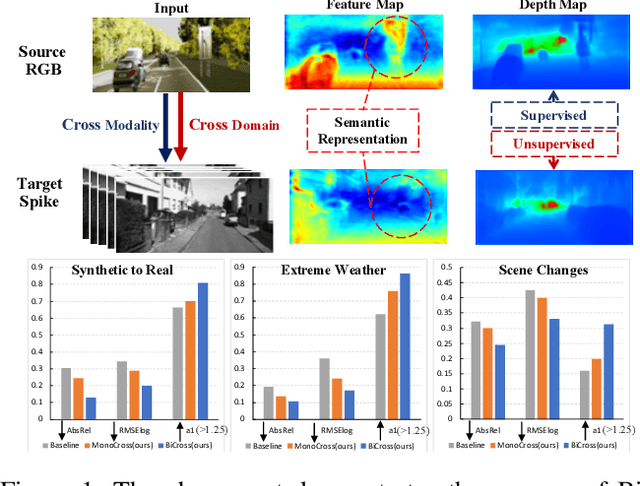

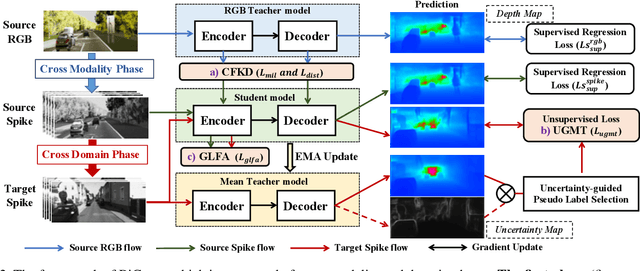
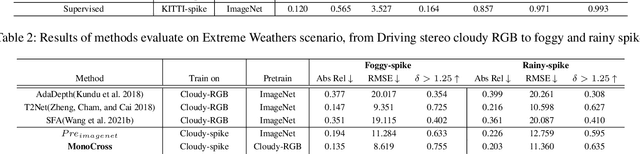
The neuromorphic spike camera generates data streams with high temporal resolution in a bio-inspired way, which has vast potential in the real-world applications such as autonomous driving. In contrast to RGB streams, spike streams have an inherent advantage to overcome motion blur, leading to more accurate depth estimation for high-velocity objects. However, training the spike depth estimation network in a supervised manner is almost impossible since it is extremely laborious and challenging to obtain paired depth labels for temporally intensive spike streams. In this paper, instead of building a spike stream dataset with full depth labels, we transfer knowledge from the open-source RGB datasets (e.g., KITTI) and estimate spike depth in an unsupervised manner. The key challenges for such problem lie in the modality gap between RGB and spike modalities, and the domain gap between labeled source RGB and unlabeled target spike domains. To overcome these challenges, we introduce a cross-modality cross-domain (BiCross) framework for unsupervised spike depth estimation. Our method narrows the enormous gap between source RGB and target spike by introducing the mediate simulated source spike domain. To be specific, for the cross-modality phase, we propose a novel Coarse-to-Fine Knowledge Distillation (CFKD), which transfers the image and pixel level knowledge from source RGB to source spike. Such design leverages the abundant semantic and dense temporal information of RGB and spike modalities respectively. For the cross-domain phase, we introduce the Uncertainty Guided Mean-Teacher (UGMT) to generate reliable pseudo labels with uncertainty estimation, alleviating the shift between the source spike and target spike domains. Besides, we propose a Global-Level Feature Alignment method (GLFA) to align the feature between two domains and generate more reliable pseudo labels.