 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKubrick: Multimodal Agent Collaborations for Synthetic Video Generation
Aug 19, 2024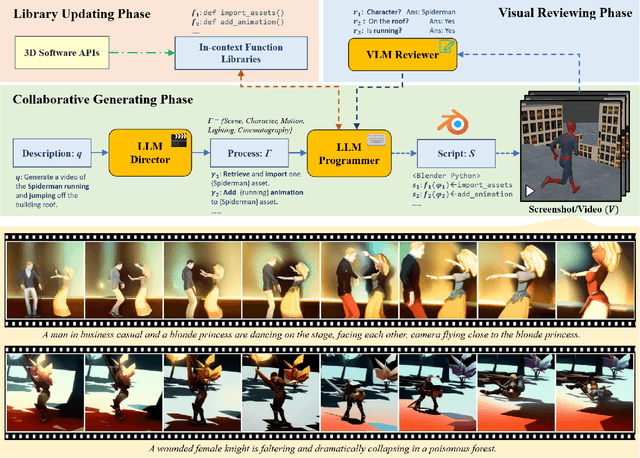
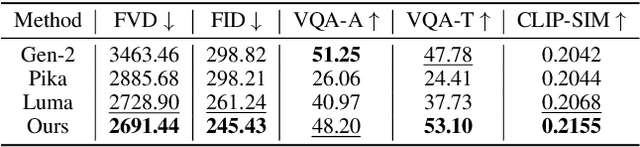

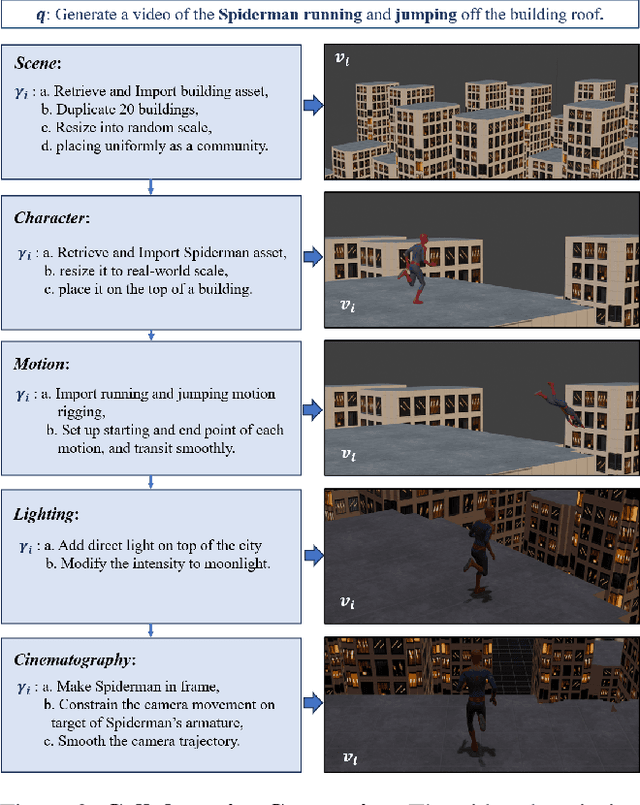
Text-to-video generation has been dominated by end-to-end diffusion-based or autoregressive models. On one hand, those novel models provide plausible versatility, but they are criticized for physical correctness, shading and illumination, camera motion, and temporal consistency. On the other hand, film industry relies on manually-edited Computer-Generated Imagery (CGI) using 3D modeling software. Human-directed 3D synthetic videos and animations address the aforementioned shortcomings, but it is extremely tedious and requires tight collaboration between movie makers and 3D rendering experts. In this paper, we introduce an automatic synthetic video generation pipeline based on Vision Large Language Model (VLM) agent collaborations. Given a natural language description of a video, multiple VLM agents auto-direct various processes of the generation pipeline. They cooperate to create Blender scripts which render a video that best aligns with the given description. Based on film making inspiration and augmented with Blender-based movie making knowledge, the Director agent decomposes the input text-based video description into sub-processes. For each sub-process, the Programmer agent produces Python-based Blender scripts based on customized function composing and API calling. Then, the Reviewer agent, augmented with knowledge of video reviewing, character motion coordinates, and intermediate screenshots uses its compositional reasoning ability to provide feedback to the Programmer agent. The Programmer agent iteratively improves the scripts to yield the best overall video outcome. Our generated videos show better quality than commercial video generation models in 5 metrics on video quality and instruction-following performance. Moreover, our framework outperforms other approaches in a comprehensive user study on quality, consistency, and rationality.
Automatic diagnosis of cardiac magnetic resonance images based on semi-supervised learning
May 23, 2024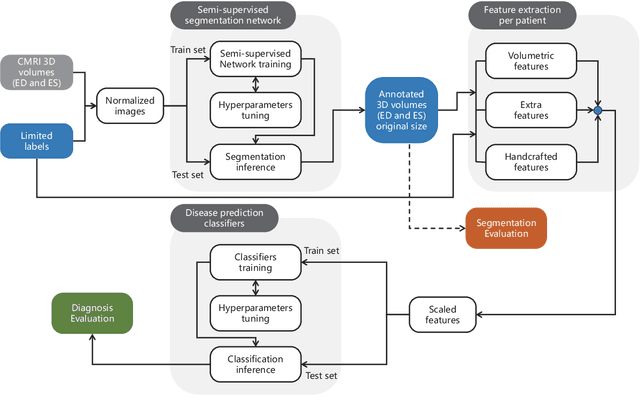

Cardiac magnetic resonance imaging (MRI) is a pivotal tool for assessing cardiac function. Precise segmentation of cardiac structures is imperative for accurate cardiac functional evaluation. This paper introduces a semi-supervised model for automatic segmentation of cardiac images and auxiliary diagnosis. By harnessing cardiac MRI images and necessitating only a small portion of annotated image data, the model achieves fully automated, high-precision segmentation of cardiac images, extraction of features, calculation of clinical indices, and prediction of diseases. The provided segmentation results, clinical indices, and prediction outcomes can aid physicians in diagnosis, thereby serving as auxiliary diagnostic tools. Experimental results showcase that this semi-supervised model for automatic segmentation of cardiac images and auxiliary diagnosis attains high accuracy in segmentation and correctness in prediction, demonstrating substantial practical guidance and application value.
Channel prior convolutional attention for medical image segmentation
Jun 08, 2023Characteristics such as low contrast and significant organ shape variations are often exhibited in medical images. The improvement of segmentation performance in medical imaging is limited by the generally insufficient adaptive capabilities of existing attention mechanisms. An efficient Channel Prior Convolutional Attention (CPCA) method is proposed in this paper, supporting the dynamic distribution of attention weights in both channel and spatial dimensions. Spatial relationships are effectively extracted while preserving the channel prior by employing a multi-scale depth-wise convolutional module. The ability to focus on informative channels and important regions is possessed by CPCA. A segmentation network called CPCANet for medical image segmentation is proposed based on CPCA. CPCANet is validated on two publicly available datasets. Improved segmentation performance is achieved by CPCANet while requiring fewer computational resources through comparisons with state-of-the-art algorithms. Our code is publicly available at \url{https://github.com/Cuthbert-Huang/CPCANet}.
Complementary consistency semi-supervised learning for 3D left atrial image segmentation
Oct 04, 2022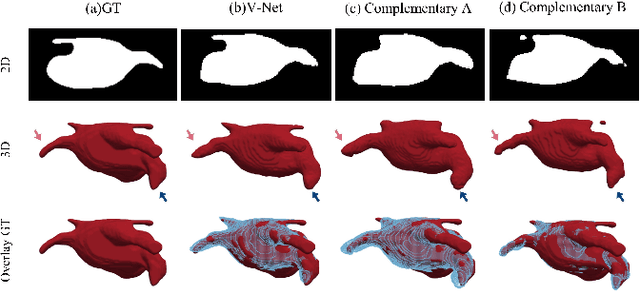
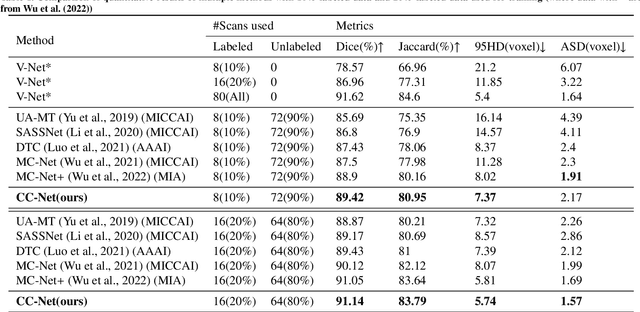
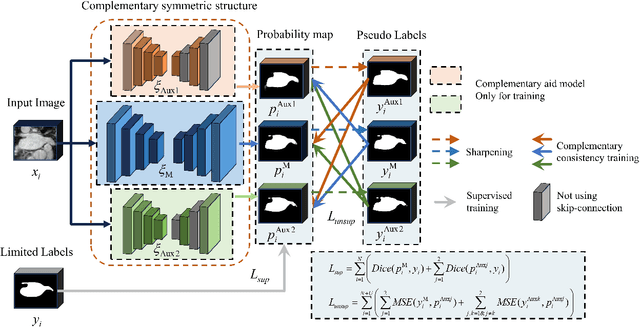
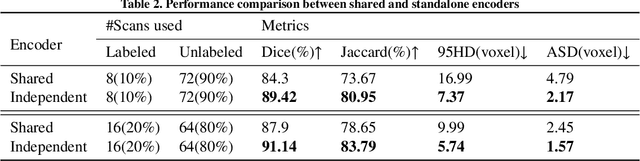
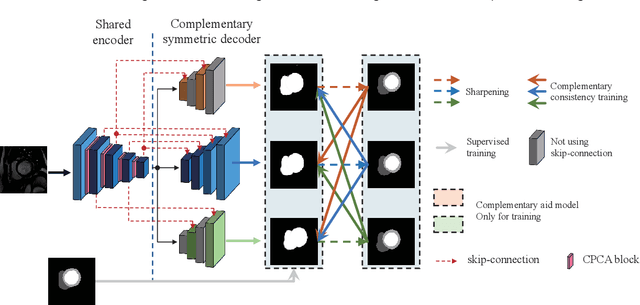
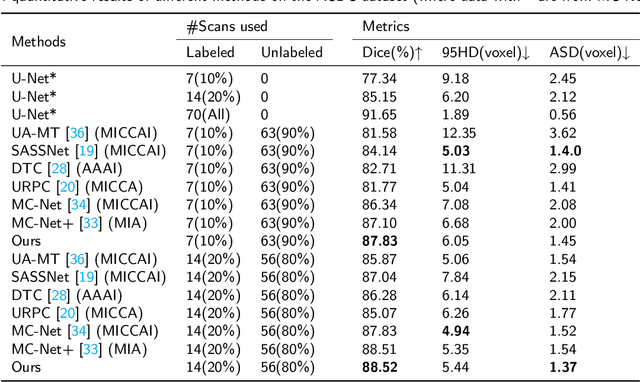
A network based on complementary consistency training (CC-Net) is proposed for semi-supervised left atrial image segmentation in this paper. From the perspective of complementary information, CC-Net effectively utilizes unlabeled data and resolves the problem that semi-supervised segmentation algorithms currently in use have a limited capacity to extract information from unlabeled data. A primary model and two complementary auxiliary models are part of the complementary symmetric structure of the CC-Net. A complementary consistency training is formed by the inter-model perturbation between the primary model and the auxiliary models. The main model is better able to concentrate on the ambiguous region due to the complementary information provided by the two auxiliary models. Additionally, forcing consistency between the primary model and the auxiliary models makes it easier to obtain decision boundaries with little uncertainty. CC-Net was validated in the benchmark dataset of 2018 left atrial segmentation challenge, reaching Dice of 89.42% with 10% labeled data training and 91.14% with 20% labeled data training. By comparing with current state-of-the-art algorithms, CC-Net has the best segmentation performance and robustness. Our code is publicly available at https://github.com/Cuthbert-Huang/CC-Net.
Barrier Certified Safety Learning Control: When Sum-of-Square Programming Meets Reinforcement Learning
Jun 29, 2022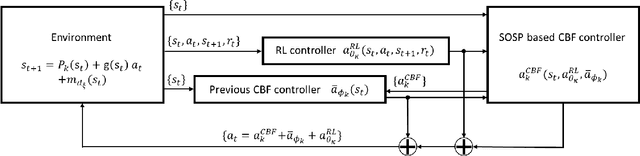

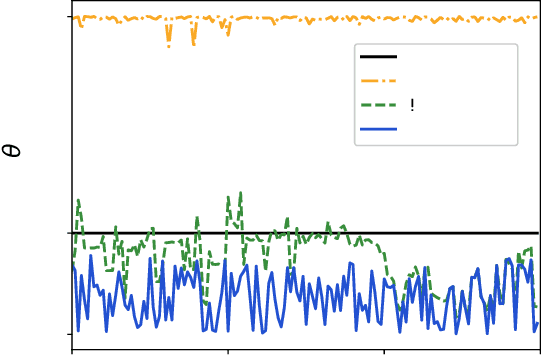

Safety guarantee is essential in many engineering implementations. Reinforcement learning provides a useful way to strengthen safety. However, reinforcement learning algorithms cannot completely guarantee safety over realistic operations. To address this issue, this work adopts control barrier functions over reinforcement learning, and proposes a compensated algorithm to completely maintain safety. Specifically, a sum-of-squares programming has been exploited to search for the optimal controller, and tune the learning hyperparameters simultaneously. Thus, the control actions are pledged to be always within the safe region. The effectiveness of proposed method is demonstrated via an inverted pendulum model. Compared to quadratic programming based reinforcement learning methods, our sum-of-squares programming based reinforcement learning has shown its superiority.