 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Never Come Up Empty: Adaptive HyDE Retrieval for Improving LLM Developer Support
Jul 22, 2025Large Language Models (LLMs) have shown promise in assisting developers with code-related questions; however, LLMs carry the risk of generating unreliable answers. To address this, Retrieval-Augmented Generation (RAG) has been proposed to reduce the unreliability (i.e., hallucinations) of LLMs. However, designing effective pipelines remains challenging due to numerous design choices. In this paper, we construct a retrieval corpus of over 3 million Java and Python related Stack Overflow posts with accepted answers, and explore various RAG pipeline designs to answer developer questions, evaluating their effectiveness in generating accurate and reliable responses. More specifically, we (1) design and evaluate 7 different RAG pipelines and 63 pipeline variants to answer questions that have historically similar matches, and (2) address new questions without any close prior matches by automatically lowering the similarity threshold during retrieval, thereby increasing the chance of finding partially relevant context and improving coverage for unseen cases. We find that implementing a RAG pipeline combining hypothetical-documentation-embedding (HyDE) with the full-answer context performs best in retrieving and answering similarcontent for Stack Overflow questions. Finally, we apply our optimal RAG pipeline to 4 open-source LLMs and compare the results to their zero-shot performance. Our findings show that RAG with our optimal RAG pipeline consistently outperforms zero-shot baselines across models, achieving higher scores for helpfulness, correctness, and detail with LLM-as-a-judge. These findings demonstrate that our optimal RAG pipelines robustly enhance answer quality for a wide range of developer queries including both previously seen and novel questions across different LLMs
Three-layer deep learning network random trees for fault diagnosis in chemical production process
May 01, 2024With the development of technology, the chemical production process is becoming increasingly complex and large-scale, making fault diagnosis particularly important. However, current diagnostic methods struggle to address the complexities of large-scale production processes. In this paper, we integrate the strengths of deep learning and machine learning technologies, combining the advantages of bidirectional long and short-term memory neural networks, fully connected neural networks, and the extra trees algorithm to propose a novel fault diagnostic model named three-layer deep learning network random trees (TDLN-trees). First, the deep learning component extracts temporal features from industrial data, combining and transforming them into a higher-level data representation. Second, the machine learning component processes and classifies the features extracted in the first step. An experimental analysis based on the Tennessee Eastman process verifies the superiority of the proposed method.
Unraveling Code Clone Dynamics in Deep Learning Frameworks
Apr 25, 2024Deep Learning (DL) frameworks play a critical role in advancing artificial intelligence, and their rapid growth underscores the need for a comprehensive understanding of software quality and maintainability. DL frameworks, like other systems, are prone to code clones. Code clones refer to identical or highly similar source code fragments within the same project or even across different projects. Code cloning can have positive and negative implications for software development, influencing maintenance, readability, and bug propagation. In this paper, we aim to address the knowledge gap concerning the evolutionary dimension of code clones in DL frameworks and the extent of code reuse across these frameworks. We empirically analyze code clones in nine popular DL frameworks, i.e., TensorFlow, Paddle, PyTorch, Aesara, Ray, MXNet, Keras, Jax and BentoML, to investigate (1) the characteristics of the long-term code cloning evolution over releases in each framework, (2) the short-term, i.e., within-release, code cloning patterns and their influence on the long-term trends, and (3) the file-level code clones within the DL frameworks. Our findings reveal that DL frameworks adopt four distinct cloning trends and that these trends present some common and distinct characteristics. For instance, bug-fixing activities persistently happen in clones irrespective of the clone evolutionary trend but occur more in the "Serpentine" trend. Moreover, the within release level investigation demonstrates that short-term code cloning practices impact long-term cloning trends. The cross-framework code clone investigation reveals the presence of functional and architectural adaptation file-level cross-framework code clones across the nine studied frameworks. We provide insights that foster robust clone practices and collaborative maintenance in the development of DL frameworks.
Channel prior convolutional attention for medical image segmentation
Jun 08, 2023Characteristics such as low contrast and significant organ shape variations are often exhibited in medical images. The improvement of segmentation performance in medical imaging is limited by the generally insufficient adaptive capabilities of existing attention mechanisms. An efficient Channel Prior Convolutional Attention (CPCA) method is proposed in this paper, supporting the dynamic distribution of attention weights in both channel and spatial dimensions. Spatial relationships are effectively extracted while preserving the channel prior by employing a multi-scale depth-wise convolutional module. The ability to focus on informative channels and important regions is possessed by CPCA. A segmentation network called CPCANet for medical image segmentation is proposed based on CPCA. CPCANet is validated on two publicly available datasets. Improved segmentation performance is achieved by CPCANet while requiring fewer computational resources through comparisons with state-of-the-art algorithms. Our code is publicly available at \url{https://github.com/Cuthbert-Huang/CPCANet}.
Complementary consistency semi-supervised learning for 3D left atrial image segmentation
Oct 04, 2022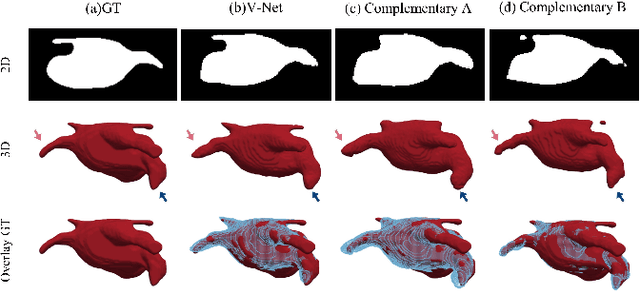
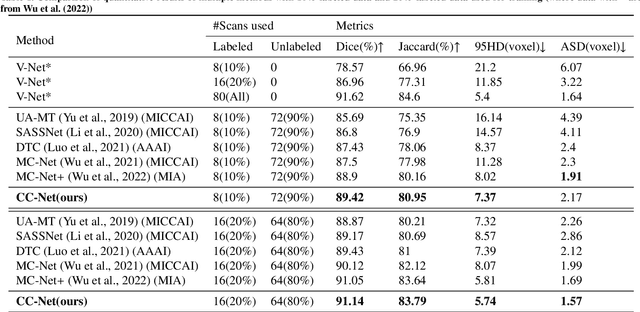
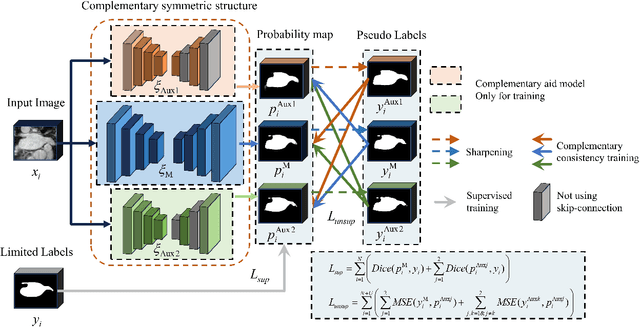
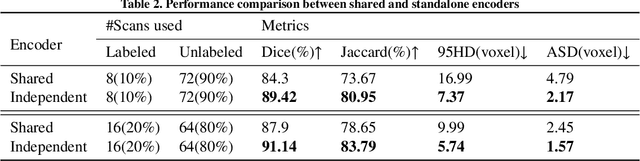
A network based on complementary consistency training (CC-Net) is proposed for semi-supervised left atrial image segmentation in this paper. From the perspective of complementary information, CC-Net effectively utilizes unlabeled data and resolves the problem that semi-supervised segmentation algorithms currently in use have a limited capacity to extract information from unlabeled data. A primary model and two complementary auxiliary models are part of the complementary symmetric structure of the CC-Net. A complementary consistency training is formed by the inter-model perturbation between the primary model and the auxiliary models. The main model is better able to concentrate on the ambiguous region due to the complementary information provided by the two auxiliary models. Additionally, forcing consistency between the primary model and the auxiliary models makes it easier to obtain decision boundaries with little uncertainty. CC-Net was validated in the benchmark dataset of 2018 left atrial segmentation challenge, reaching Dice of 89.42% with 10% labeled data training and 91.14% with 20% labeled data training. By comparing with current state-of-the-art algorithms, CC-Net has the best segmentation performance and robustness. Our code is publicly available at https://github.com/Cuthbert-Huang/CC-Net.