 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping An Attention-Based Ensemble Learning Framework for Financial Portfolio Optimisation
Apr 13, 2024In recent years, deep or reinforcement learning approaches have been applied to optimise investment portfolios through learning the spatial and temporal information under the dynamic financial market. Yet in most cases, the existing approaches may produce biased trading signals based on the conventional price data due to a lot of market noises, which possibly fails to balance the investment returns and risks. Accordingly, a multi-agent and self-adaptive portfolio optimisation framework integrated with attention mechanisms and time series, namely the MASAAT, is proposed in this work in which multiple trading agents are created to observe and analyse the price series and directional change data that recognises the significant changes of asset prices at different levels of granularity for enhancing the signal-to-noise ratio of price series. Afterwards, by reconstructing the tokens of financial data in a sequence, the attention-based cross-sectional analysis module and temporal analysis module of each agent can effectively capture the correlations between assets and the dependencies between time points. Besides, a portfolio generator is integrated into the proposed framework to fuse the spatial-temporal information and then summarise the portfolios suggested by all trading agents to produce a newly ensemble portfolio for reducing biased trading actions and balancing the overall returns and risks. The experimental results clearly demonstrate that the MASAAT framework achieves impressive enhancement when compared with many well-known portfolio optimsation approaches on three challenging data sets of DJIA, S&P 500 and CSI 300. More importantly, our proposal has potential strengths in many possible applications for future study.
Developing A Multi-Agent and Self-Adaptive Framework with Deep Reinforcement Learning for Dynamic Portfolio Risk Management
Feb 03, 2024Deep or reinforcement learning (RL) approaches have been adapted as reactive agents to quickly learn and respond with new investment strategies for portfolio management under the highly turbulent financial market environments in recent years. In many cases, due to the very complex correlations among various financial sectors, and the fluctuating trends in different financial markets, a deep or reinforcement learning based agent can be biased in maximising the total returns of the newly formulated investment portfolio while neglecting its potential risks under the turmoil of various market conditions in the global or regional sectors. Accordingly, a multi-agent and self-adaptive framework namely the MASA is proposed in which a sophisticated multi-agent reinforcement learning (RL) approach is adopted through two cooperating and reactive agents to carefully and dynamically balance the trade-off between the overall portfolio returns and their potential risks. Besides, a very flexible and proactive agent as the market observer is integrated into the MASA framework to provide some additional information on the estimated market trends as valuable feedbacks for multi-agent RL approach to quickly adapt to the ever-changing market conditions. The obtained empirical results clearly reveal the potential strengths of our proposed MASA framework based on the multi-agent RL approach against many well-known RL-based approaches on the challenging data sets of the CSI 300, Dow Jones Industrial Average and S&P 500 indexes over the past 10 years. More importantly, our proposed MASA framework shed lights on many possible directions for future investigation.
Barrier Certified Safety Learning Control: When Sum-of-Square Programming Meets Reinforcement Learning
Jun 29, 2022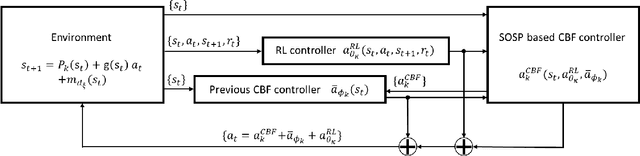

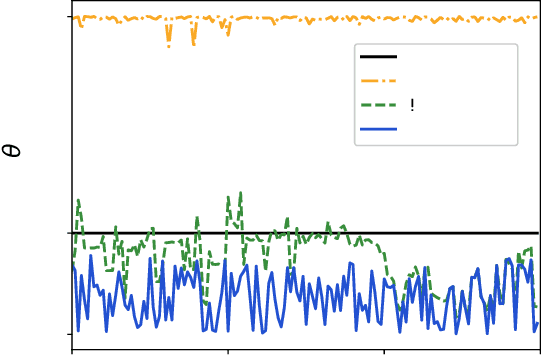

Safety guarantee is essential in many engineering implementations. Reinforcement learning provides a useful way to strengthen safety. However, reinforcement learning algorithms cannot completely guarantee safety over realistic operations. To address this issue, this work adopts control barrier functions over reinforcement learning, and proposes a compensated algorithm to completely maintain safety. Specifically, a sum-of-squares programming has been exploited to search for the optimal controller, and tune the learning hyperparameters simultaneously. Thus, the control actions are pledged to be always within the safe region. The effectiveness of proposed method is demonstrated via an inverted pendulum model. Compared to quadratic programming based reinforcement learning methods, our sum-of-squares programming based reinforcement learning has shown its superiority.