 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVORL-EXPLORE: A Hybrid Learning Planning Approach to Multi-Robot Exploration in Dynamic Environments
Mar 09, 2026Hierarchical multi-robot exploration commonly decouples frontier allocation from local navigation, which can make the system brittle in dense and dynamic environments. Because the allocator lacks direct awareness of execution difficulty, robots may cluster at bottlenecks, trigger oscillatory replanning, and generate redundant coverage. We propose VORL-EXPLORE, a hybrid learning and planning framework that addresses this limitation through execution fidelity, a shared estimate of local navigability that couples task allocation with motion execution. This fidelity signal is incorporated into a fidelity-coupled Voronoi objective with inter-robot repulsion to reduce contention before it emerges. It also drives a risk-aware adaptive arbitration mechanism between global A* guidance and a reactive reinforcement learning policy, balancing long-range efficiency with safe interaction in confined spaces. The framework further supports online self-supervised recalibration of the fidelity model using pseudo-labels derived from recent progress and safety outcomes, enabling adaptation to non-stationary obstacles without manual risk tuning. We evaluate this capability separately in a dedicated severe-traffic ablation. Extensive experiments in randomized grids and a Gazebo factory scenario show high success rates, shorter path length, lower overlap, and robust collision avoidance. The source code will be made publicly available upon acceptance.
Automatic Navigation and Voice Cloning Technology Deployment on a Humanoid Robot
Oct 17, 2024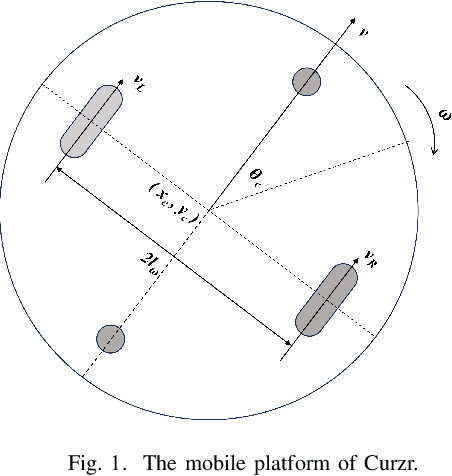

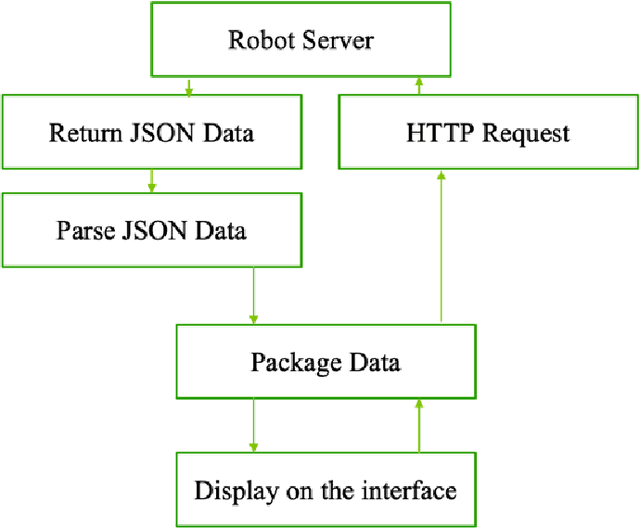
Mobile robots have shown immense potential and are expected to be widely used in the service industry. The importance of automatic navigation and voice cloning cannot be overstated as they enable functional robots to provide high-quality services. The objective of this work is to develop a control algorithm for the automatic navigation of a humanoid mobile robot called Cruzr, which is a service robot manufactured by Ubtech. Initially, a virtual environment is constructed in the simulation software Gazebo using Simultaneous Localization And Mapping (SLAM), and global path planning is carried out by means of local path tracking. The two-wheel differential chassis kinematics model is employed to ensure autonomous dynamic obstacle avoidance for the robot chassis. Furthermore, the mapping and trajectory generation algorithms developed in the simulation environment are successfully implemented on the real robot Cruzr. The performance of automatic navigation is compared between the Dynamic Window Approach (DWA) and Model Predictive Control (MPC) algorithms. Additionally, a mobile application for voice cloning is created based on a Hidden Markov Model, and the proposed Chatbot is also tested and deployed on Cruzr.
Barrier Certified Safety Learning Control: When Sum-of-Square Programming Meets Reinforcement Learning
Jun 29, 2022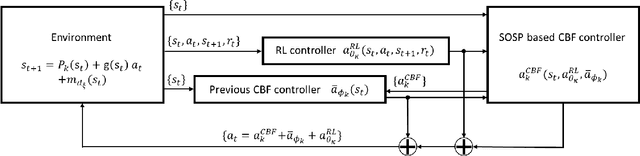

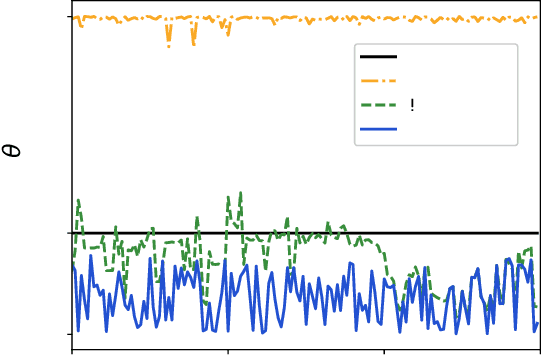

Safety guarantee is essential in many engineering implementations. Reinforcement learning provides a useful way to strengthen safety. However, reinforcement learning algorithms cannot completely guarantee safety over realistic operations. To address this issue, this work adopts control barrier functions over reinforcement learning, and proposes a compensated algorithm to completely maintain safety. Specifically, a sum-of-squares programming has been exploited to search for the optimal controller, and tune the learning hyperparameters simultaneously. Thus, the control actions are pledged to be always within the safe region. The effectiveness of proposed method is demonstrated via an inverted pendulum model. Compared to quadratic programming based reinforcement learning methods, our sum-of-squares programming based reinforcement learning has shown its superiority.