 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Adapt and Tell: Adversarial Training of Cross-domain Image Captioner
Aug 14, 2017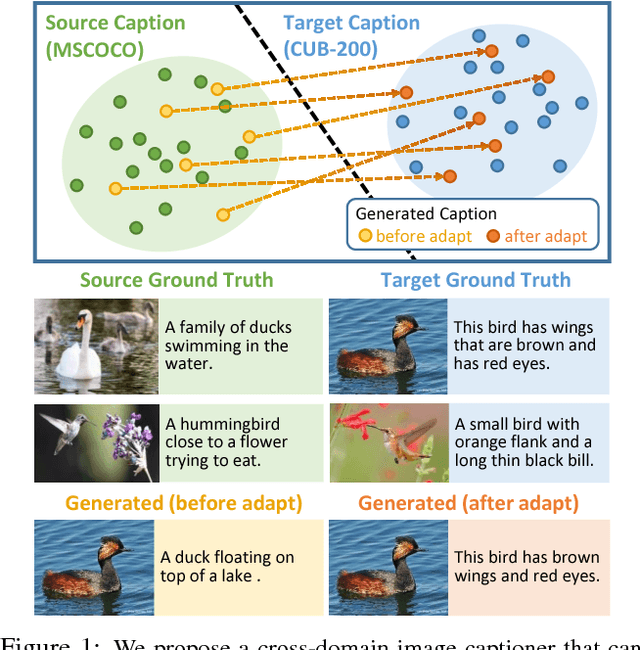
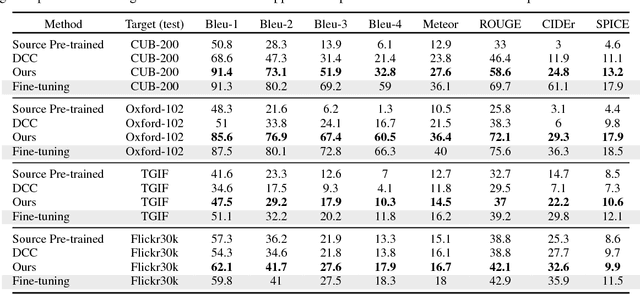
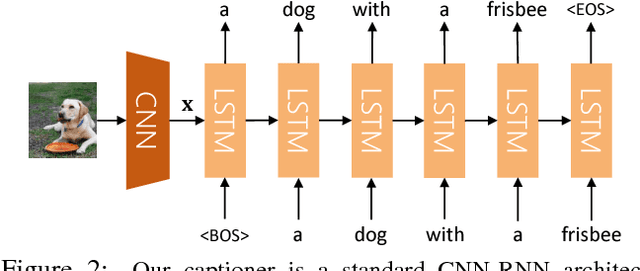
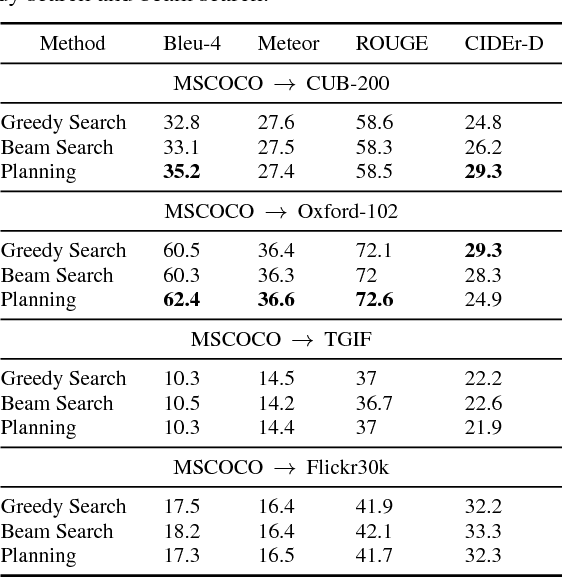
Impressive image captioning results are achieved in domains with plenty of training image and sentence pairs (e.g., MSCOCO). However, transferring to a target domain with significant domain shifts but no paired training data (referred to as cross-domain image captioning) remains largely unexplored. We propose a novel adversarial training procedure to leverage unpaired data in the target domain. Two critic networks are introduced to guide the captioner, namely domain critic and multi-modal critic. The domain critic assesses whether the generated sentences are indistinguishable from sentences in the target domain. The multi-modal critic assesses whether an image and its generated sentence are a valid pair. During training, the critics and captioner act as adversaries -- captioner aims to generate indistinguishable sentences, whereas critics aim at distinguishing them. The assessment improves the captioner through policy gradient updates. During inference, we further propose a novel critic-based planning method to select high-quality sentences without additional supervision (e.g., tags). To evaluate, we use MSCOCO as the source domain and four other datasets (CUB-200-2011, Oxford-102, TGIF, and Flickr30k) as the target domains. Our method consistently performs well on all datasets. In particular, on CUB-200-2011, we achieve 21.8% CIDEr-D improvement after adaptation. Utilizing critics during inference further gives another 4.5% boost.
Leveraging Video Descriptions to Learn Video Question Answering
Dec 19, 2016
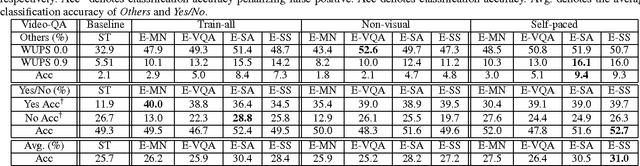

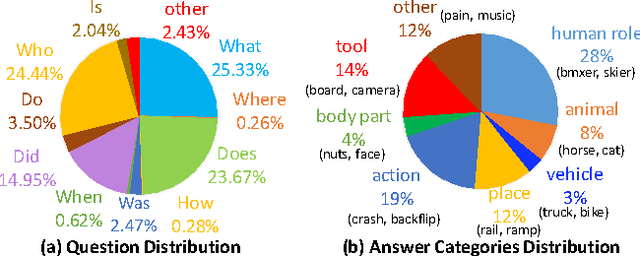
We propose a scalable approach to learn video-based question answering (QA): answer a "free-form natural language question" about a video content. Our approach automatically harvests a large number of videos and descriptions freely available online. Then, a large number of candidate QA pairs are automatically generated from descriptions rather than manually annotated. Next, we use these candidate QA pairs to train a number of video-based QA methods extended fromMN (Sukhbaatar et al. 2015), VQA (Antol et al. 2015), SA (Yao et al. 2015), SS (Venugopalan et al. 2015). In order to handle non-perfect candidate QA pairs, we propose a self-paced learning procedure to iteratively identify them and mitigate their effects in training. Finally, we evaluate performance on manually generated video-based QA pairs. The results show that our self-paced learning procedure is effective, and the extended SS model outperforms various baselines.
Title Generation for User Generated Videos
Sep 08, 2016
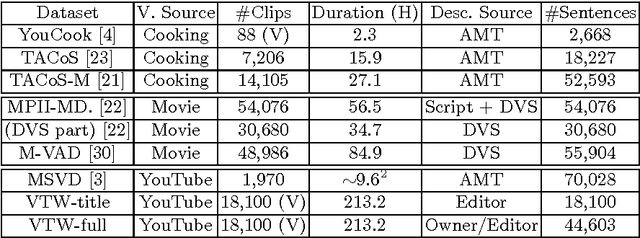


A great video title describes the most salient event compactly and captures the viewer's attention. In contrast, video captioning tends to generate sentences that describe the video as a whole. Although generating a video title automatically is a very useful task, it is much less addressed than video captioning. We address video title generation for the first time by proposing two methods that extend state-of-the-art video captioners to this new task. First, we make video captioners highlight sensitive by priming them with a highlight detector. Our framework allows for jointly training a model for title generation and video highlight localization. Second, we induce high sentence diversity in video captioners, so that the generated titles are also diverse and catchy. This means that a large number of sentences might be required to learn the sentence structure of titles. Hence, we propose a novel sentence augmentation method to train a captioner with additional sentence-only examples that come without corresponding videos. We collected a large-scale Video Titles in the Wild (VTW) dataset of 18100 automatically crawled user-generated videos and titles. On VTW, our methods consistently improve title prediction accuracy, and achieve the best performance in both automatic and human evaluation. Finally, our sentence augmentation method also outperforms the baselines on the M-VAD dataset.