 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Video Descriptions to Learn Video Question Answering
Paper and Code

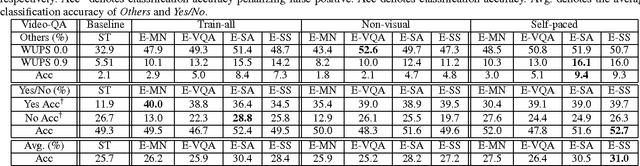

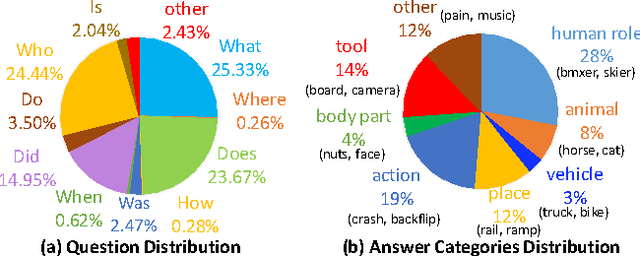
We propose a scalable approach to learn video-based question answering (QA): answer a "free-form natural language question" about a video content. Our approach automatically harvests a large number of videos and descriptions freely available online. Then, a large number of candidate QA pairs are automatically generated from descriptions rather than manually annotated. Next, we use these candidate QA pairs to train a number of video-based QA methods extended fromMN (Sukhbaatar et al. 2015), VQA (Antol et al. 2015), SA (Yao et al. 2015), SS (Venugopalan et al. 2015). In order to handle non-perfect candidate QA pairs, we propose a self-paced learning procedure to iteratively identify them and mitigate their effects in training. Finally, we evaluate performance on manually generated video-based QA pairs. The results show that our self-paced learning procedure is effective, and the extended SS model outperforms various baselines.