 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLED: One-Class Learned Encoder-Decoder Network with Adversarial Context Masking for Novelty Detection
Paper and Code
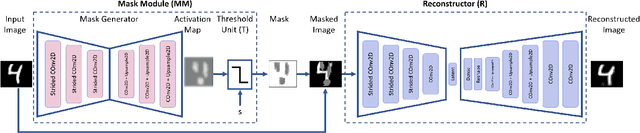
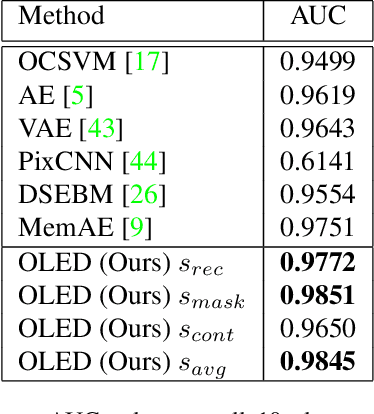

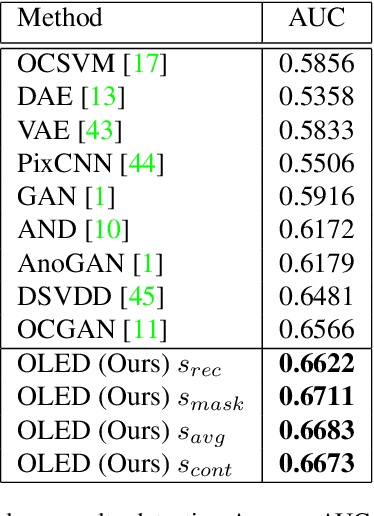
Novelty detection is the task of recognizing samples that do not belong to the distribution of the target class. During training, the novelty class is absent, preventing the use of traditional classification approaches. Deep autoencoders have been widely used as a base of many unsupervised novelty detection methods. In particular, context autoencoders have been successful in the novelty detection task because of the more effective representations they learn by reconstructing original images from randomly masked images. However, a significant drawback of context autoencoders is that random masking fails to consistently cover important structures of the input image, leading to suboptimal representations - especially for the novelty detection task. In this paper, to optimize input masking, we have designed a framework consisting of two competing networks, a Mask Module and a Reconstructor. The Mask Module is a convolutional autoencoder that learns to generate optimal masks that cover the most important parts of images. Alternatively, the Reconstructor is a convolutional encoder-decoder that aims to reconstruct unperturbed images from masked images. The networks are trained in an adversarial manner in which the Mask Module generates masks that are applied to images given to the Reconstructor. In this way, the Mask Module seeks to maximize the reconstruction error that the Reconstructor is minimizing. When applied to novelty detection, the proposed approach learns semantically richer representations compared to context autoencoders and enhances novelty detection at test time through more optimal masking. Novelty detection experiments on the MNIST and CIFAR-10 image datasets demonstrate the proposed approach's superiority over cutting-edge methods. In a further experiment on the UCSD video dataset for novelty detection, the proposed approach achieves state-of-the-art results.