 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPA: Learning GUI Process Automation from Demonstrations
Apr 02, 2026GUI Process Automation (GPA) is a lightweight but general vision-based Robotic Process Automation (RPA), which enables fast and stable process replay with only a single demo. Addressing the fragility of traditional RPA and the non-deterministic risks of current vision language model-based GUI agents, GPA introduces three core benefits: (1) Robustness via Sequential Monte Carlo-based localization to handle rescaling and detection uncertainty; (2) Deterministic and Reliability safeguarded by readiness calibration; and (3) Privacy through fast, fully local execution. This approach delivers the adaptability, robustness, and security required for enterprise workflows. It can also be used as an MCP/CLI tool by other agents with coding capabilities so that the agent only reasons and orchestrates while GPA handles the GUI execution. We conducted a pilot experiment to compare GPA with Gemini 3 Pro (with CUA tools) and found that GPA achieves higher success rate with 10 times faster execution speed in finishing long-horizon GUI tasks.
MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers
Aug 20, 2025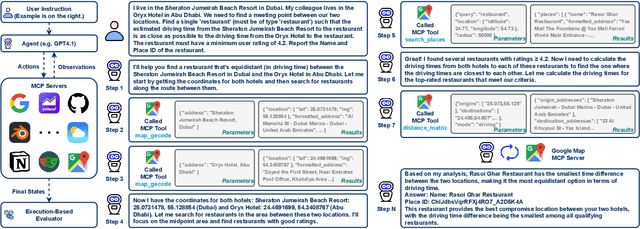
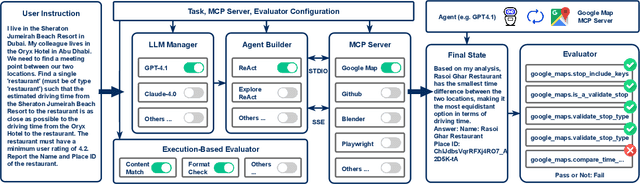
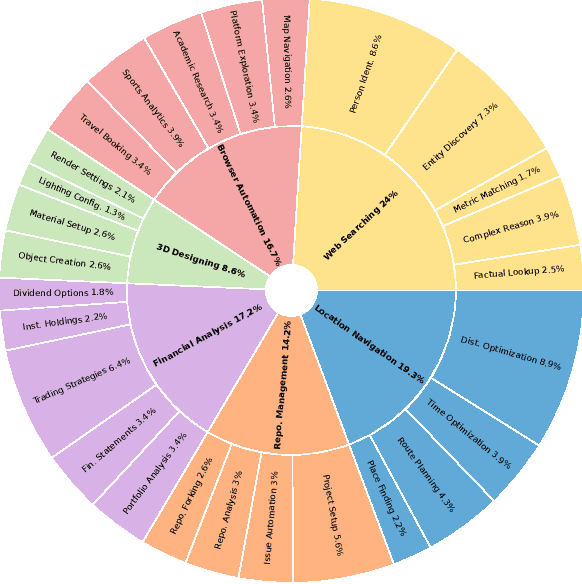
The Model Context Protocol has emerged as a transformative standard for connecting large language models to external data sources and tools, rapidly gaining adoption across major AI providers and development platforms. However, existing benchmarks are overly simplistic and fail to capture real application challenges such as long-horizon reasoning and large, unfamiliar tool spaces. To address this critical gap, we introduce MCP-Universe, the first comprehensive benchmark specifically designed to evaluate LLMs in realistic and hard tasks through interaction with real-world MCP servers. Our benchmark encompasses 6 core domains spanning 11 different MCP servers: Location Navigation, Repository Management, Financial Analysis, 3D Design, Browser Automation, and Web Searching. To ensure rigorous evaluation, we implement execution-based evaluators, including format evaluators for agent format compliance, static evaluators for time-invariant content matching, and dynamic evaluators that automatically retrieve real-time ground truth for temporally sensitive tasks. Through extensive evaluation of leading LLMs, we find that even SOTA models such as GPT-5 (43.72%), Grok-4 (33.33%) and Claude-4.0-Sonnet (29.44%) exhibit significant performance limitations. In addition, our benchmark poses a significant long-context challenge for LLM agents, as the number of input tokens increases rapidly with the number of interaction steps. Moreover, it introduces an unknown-tools challenge, as LLM agents often lack familiarity with the precise usage of the MCP servers. Notably, enterprise-level agents like Cursor cannot achieve better performance than standard ReAct frameworks. Beyond evaluation, we open-source our extensible evaluation framework with UI support, enabling researchers and practitioners to seamlessly integrate new agents and MCP servers while fostering innovation in the rapidly evolving MCP ecosystem.
Grounding Emotional Descriptions to Electrovibration Haptic Signals
Nov 04, 2024



Designing and displaying haptic signals with sensory and emotional attributes can improve the user experience in various applications. Free-form user language provides rich sensory and emotional information for haptic design (e.g., ``This signal feels smooth and exciting''), but little work exists on linking user descriptions to haptic signals (i.e., language grounding). To address this gap, we conducted a study where 12 users described the feel of 32 signals perceived on a surface haptics (i.e., electrovibration) display. We developed a computational pipeline using natural language processing (NLP) techniques, such as GPT-3.5 Turbo and word embedding methods, to extract sensory and emotional keywords and group them into semantic clusters (i.e., concepts). We linked the keyword clusters to haptic signal features (e.g., pulse count) using correlation analysis. The proposed pipeline demonstrates the viability of a computational approach to analyzing haptic experiences. We discuss our future plans for creating a predictive model of haptic experience.
Automatic Curriculum Expert Iteration for Reliable LLM Reasoning
Oct 10, 2024



Hallucinations (i.e., generating plausible but inaccurate content) and laziness (i.e. excessive refusals or defaulting to "I don't know") persist as major challenges in LLM reasoning. Current efforts to reduce hallucinations primarily focus on factual errors in knowledge-grounded tasks, often neglecting hallucinations related to faulty reasoning. Meanwhile, some approaches render LLMs overly conservative, limiting their problem-solving capabilities. To mitigate hallucination and laziness in reasoning tasks, we propose Automatic Curriculum Expert Iteration (Auto-CEI) to enhance LLM reasoning and align responses to the model's capabilities--assertively answering within its limits and declining when tasks exceed them. In our method, Expert Iteration explores the reasoning trajectories near the LLM policy, guiding incorrect paths back on track to reduce compounding errors and improve robustness; it also promotes appropriate "I don't know" responses after sufficient reasoning attempts. The curriculum automatically adjusts rewards, incentivizing extended reasoning before acknowledging incapability, thereby pushing the limits of LLM reasoning and aligning its behaviour with these limits. We compare Auto-CEI with various SOTA baselines across logical reasoning, mathematics, and planning tasks, where Auto-CEI achieves superior alignment by effectively balancing assertiveness and conservativeness.
On the Empirical Complexity of Reasoning and Planning in LLMs
Apr 17, 2024Large Language Models (LLMs) work surprisingly well for some complex reasoning problems via chain-of-thought (CoT) or tree-of-thought (ToT), but the underlying reasons remain unclear. We seek to understand the performance of these methods by conducting experimental case studies and linking the outcomes to sample and computational complexity in machine learning. We found that if problems can be decomposed into a sequence of reasoning steps and learning to predict the next step has a low sample and computational complexity, explicitly outlining the reasoning chain with all necessary information for predicting the next step may improve performance. Conversely, for problems where predicting the next step is computationally hard, adopting ToT may yield better reasoning outcomes than attempting to formulate a short reasoning chain.
Seamless Virtual Reality with Integrated Synchronizer and Synthesizer for Autonomous Driving
Mar 06, 2024Virtual reality (VR) is a promising data engine for autonomous driving (AD). However, data fidelity in this paradigm is often degraded by VR inconsistency, for which the existing VR approaches become ineffective, as they ignore the inter-dependency between low-level VR synchronizer designs (i.e., data collector) and high-level VR synthesizer designs (i.e., data processor). This paper presents a seamless virtual reality SVR platform for AD, which mitigates such inconsistency, enabling VR agents to interact with each other in a shared symbiotic world. The crux to SVR is an integrated synchronizer and synthesizer IS2 design, which consists of a drift-aware lidar-inertial synchronizer for VR colocation and a motion-aware deep visual synthesis network for augmented reality image generation. We implement SVR on car-like robots in two sandbox platforms, achieving a cm-level VR colocalization accuracy and 3.2% VR image deviation, thereby avoiding missed collisions or model clippings. Experiments show that the proposed SVR reduces the intervention times, missed turns, and failure rates compared to other benchmarks. The SVR-trained neural network can handle unseen situations in real-world environments, by leveraging its knowledge learnt from the VR space.
A Virtual Reality Training System for Automotive Engines Assembly and Disassembly
Nov 02, 2023



Automotive engine assembly and disassembly are common and crucial programs in the automotive industry. Traditional education trains students to learn automotive engine assembly and disassembly in lecture courses and then to operate with physical engines, which are generally low effectiveness and high cost. In this work, we developed a multi-layer structured Virtual Reality (VR) system to provide students with training in automotive engine (Buick Verano) assembly and disassembly. We designed the VR training system with The VR training system is designed to have several major features, including replaceable engine parts and reusable tools, friendly user interfaces and guidance, and bottom-up designed multi-layer architecture, which can be extended to various engine models. The VR system is evaluated with controlled experiments of two groups of students. The results demonstrate that our VR training system provides remarkable usability in terms of effectiveness and efficiency. Currently, our VR system has been demonstrated and employed in the courses of Chinese colleges to train students in automotive engine assembly and disassembly. A free-to-use executable file (Microsoft Windows) and open-source code are available at https://github.com/LadissonLai/SUSTech_VREngine for facilitating the development of VR systems in the automotive industry. Finally, a video describing the operations in our VR training system is available at https://www.youtube.com/watch?v=yZe4YTwwAC4
Large Language Models as Commonsense Knowledge for Large-Scale Task Planning
May 23, 2023Natural language provides a natural interface for human communication, yet it is challenging for robots to comprehend due to its abstract nature and inherent ambiguity. Large language models (LLMs) contain commonsense knowledge that can help resolve language ambiguity and generate possible solutions to abstract specifications. While LLMs have shown promise as few-shot planning policies, their potential for planning complex tasks is not fully tapped. This paper shows that LLMs can be used as both the commonsense model of the world and the heuristic policy in search algorithms such as Monte Carlo Tree Search (MCTS). MCTS explores likely world states sampled from LLMs to facilitate better-reasoned decision-making. The commonsense policy from LLMs guides the search to relevant parts of the tree, substantially reducing the search complexity. We demonstrate the effectiveness of our method in daily task-planning experiments and highlight its advantages over using LLMs solely as policies.
Differentiable Parsing and Visual Grounding of Verbal Instructions for Object Placement
Oct 01, 2022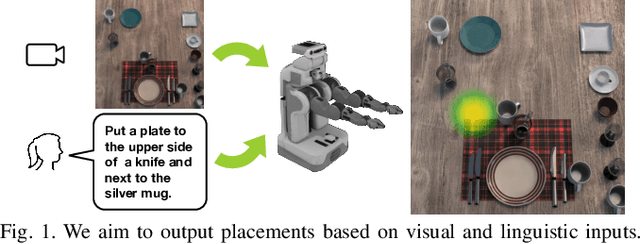
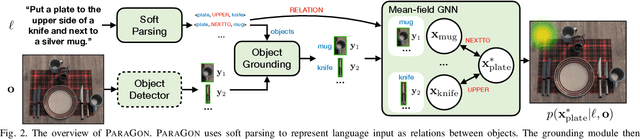
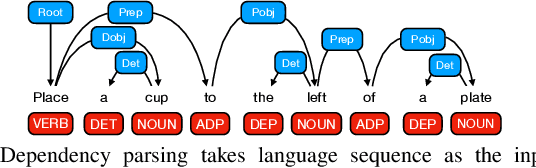
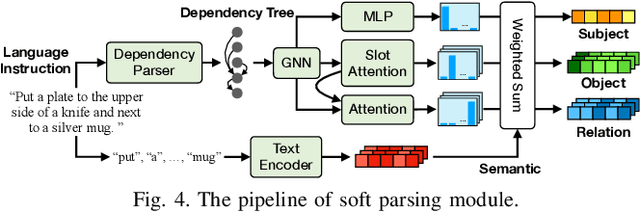
Grounding spatial relations in natural language for object placing could have ambiguity and compositionality issues. To address the issues, we introduce ParaGon, a PARsing And visual GrOuNding framework for language-conditioned object placement. It parses language instructions into relations between objects and grounds those objects in visual scenes. A particle-based GNN then conducts relational reasoning between grounded objects for placement generation. ParaGon encodes all of those procedures into neural networks for end-to-end training, which avoids annotating parsing and object reference grounding labels. Our approach inherently integrates parsing-based methods into a probabilistic, data-driven framework. It is data-efficient and generalizable for learning compositional instructions, robust to noisy language inputs, and adapts to the uncertainty of ambiguous instructions.
Visual Semantic SLAM with Landmarks for Large-Scale Outdoor Environment
Jan 04, 2020



Semantic SLAM is an important field in autonomous driving and intelligent agents, which can enable robots to achieve high-level navigation tasks, obtain simple cognition or reasoning ability and achieve language-based human-robot-interaction. In this paper, we built a system to creat a semantic 3D map by combining 3D point cloud from ORB SLAM with semantic segmentation information from Convolutional Neural Network model PSPNet-101 for large-scale environments. Besides, a new dataset for KITTI sequences has been built, which contains the GPS information and labels of landmarks from Google Map in related streets of the sequences. Moreover, we find a way to associate the real-world landmark with point cloud map and built a topological map based on semantic map.