 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHRC-Bench: A Multilingual Hardware Repository-Level Code Completion benchmark
Jan 07, 2026Large language models (LLMs) have achieved strong performance on code completion tasks in general-purpose programming languages. However, existing repository-level code completion benchmarks focus almost exclusively on software code and largely overlook hardware description languages. In this work, we present \textbf{MHRC-Bench}, consisting of \textbf{MHRC-Bench-Train} and \textbf{MHRC-Bench-Eval}, the first benchmark designed for multilingual hardware code completion at the repository level. Our benchmark targets completion tasks and covers three major hardware design coding styles. Each completion target is annotated with code-structure-level and hardware-oriented semantic labels derived from concrete syntax tree analysis. We conduct a comprehensive evaluation of models on MHRC-Bench-Eval. Comprehensive evaluation results and analysis demonstrate the effectiveness of MHRC-Bench.
Beyond Brainstorming: What Drives High-Quality Scientific Ideas? Lessons from Multi-Agent Collaboration
Aug 06, 2025While AI agents show potential in scientific ideation, most existing frameworks rely on single-agent refinement, limiting creativity due to bounded knowledge and perspective. Inspired by real-world research dynamics, this paper investigates whether structured multi-agent discussions can surpass solitary ideation. We propose a cooperative multi-agent framework for generating research proposals and systematically compare configurations including group size, leaderled versus leaderless structures, and team compositions varying in interdisciplinarity and seniority. To assess idea quality, we employ a comprehensive protocol with agent-based scoring and human review across dimensions such as novelty, strategic vision, and integration depth. Our results show that multi-agent discussions substantially outperform solitary baselines. A designated leader acts as a catalyst, transforming discussion into more integrated and visionary proposals. Notably, we find that cognitive diversity is a primary driver of quality, yet expertise is a non-negotiable prerequisite, as teams lacking a foundation of senior knowledge fail to surpass even a single competent agent. These findings offer actionable insights for designing collaborative AI ideation systems and shed light on how team structure influences creative outcomes.
JudgeLRM: Large Reasoning Models as a Judge
Mar 31, 2025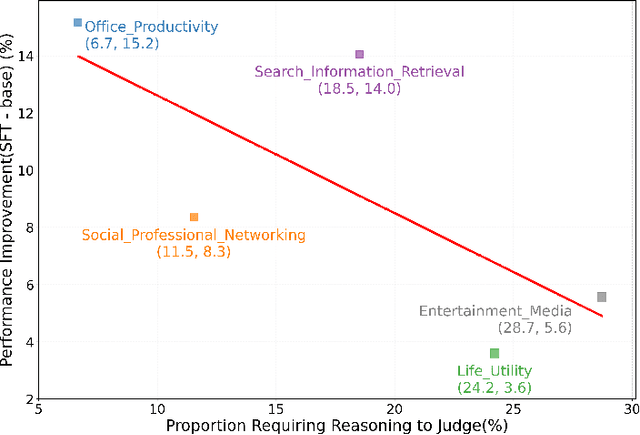
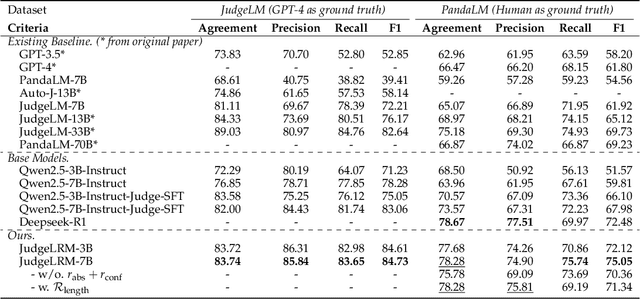


The rise of Large Language Models (LLMs) as evaluators offers a scalable alternative to human annotation, yet existing Supervised Fine-Tuning (SFT) for judges approaches often fall short in domains requiring complex reasoning. In this work, we investigate whether LLM judges truly benefit from enhanced reasoning capabilities. Through a detailed analysis of reasoning requirements across evaluation tasks, we reveal a negative correlation between SFT performance gains and the proportion of reasoning-demanding samples - highlighting the limitations of SFT in such scenarios. To address this, we introduce JudgeLRM, a family of judgment-oriented LLMs trained using reinforcement learning (RL) with judge-wise, outcome-driven rewards. JudgeLRM models consistently outperform both SFT-tuned and state-of-the-art reasoning models. Notably, JudgeLRM-3B surpasses GPT-4, and JudgeLRM-7B outperforms DeepSeek-R1 by 2.79% in F1 score, particularly excelling in judge tasks requiring deep reasoning.