 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboClaw: An Agentic Framework for Scalable Long-Horizon Robotic Tasks
Mar 12, 2026Vision-Language-Action (VLA) systems have shown strong potential for language-driven robotic manipulation. However, scaling them to long-horizon tasks remains challenging. Existing pipelines typically separate data collection, policy learning, and deployment, resulting in heavy reliance on manual environment resets and brittle multi-policy execution. We present RoboClaw, an agentic robotics framework that unifies data collection, policy learning, and task execution under a single VLM-driven controller. At the policy level, RoboClaw introduces Entangled Action Pairs (EAP), which couple forward manipulation behaviors with inverse recovery actions to form self-resetting loops for autonomous data collection. This mechanism enables continuous on-policy data acquisition and iterative policy refinement with minimal human intervention. During deployment, the same agent performs high-level reasoning and dynamically orchestrates learned policy primitives to accomplish long-horizon tasks. By maintaining consistent contextual semantics across collection and execution, RoboClaw reduces mismatch between the two phases and improves multi-policy robustness. Experiments in real-world manipulation tasks demonstrate improved stability and scalability compared to conventional open-loop pipelines, while significantly reducing human effort throughout the robot lifecycle, achieving a 25% improvement in success rate over baseline methods on long-horizon tasks and reducing human time investment by 53.7%.
Unified Embodied VLM Reasoning with Robotic Action via Autoregressive Discretized Pre-training
Dec 30, 2025General-purpose robotic systems operating in open-world environments must achieve both broad generalization and high-precision action execution, a combination that remains challenging for existing Vision-Language-Action (VLA) models. While large Vision-Language Models (VLMs) improve semantic generalization, insufficient embodied reasoning leads to brittle behavior, and conversely, strong reasoning alone is inadequate without precise control. To provide a decoupled and quantitative assessment of this bottleneck, we introduce Embodied Reasoning Intelligence Quotient (ERIQ), a large-scale embodied reasoning benchmark in robotic manipulation, comprising 6K+ question-answer pairs across four reasoning dimensions. By decoupling reasoning from execution, ERIQ enables systematic evaluation and reveals a strong positive correlation between embodied reasoning capability and end-to-end VLA generalization. To bridge the gap from reasoning to precise execution, we propose FACT, a flow-matching-based action tokenizer that converts continuous control into discrete sequences while preserving high-fidelity trajectory reconstruction. The resulting GenieReasoner jointly optimizes reasoning and action in a unified space, outperforming both continuous-action and prior discrete-action baselines in real-world tasks. Together, ERIQ and FACT provide a principled framework for diagnosing and overcoming the reasoning-precision trade-off, advancing robust, general-purpose robotic manipulation.
Point Cloud Compression with Sibling Context and Surface Priors
May 02, 2022
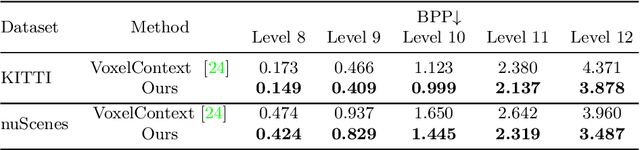
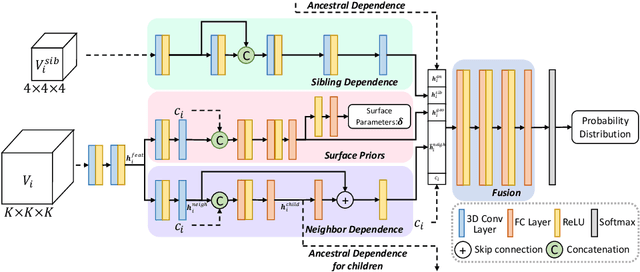
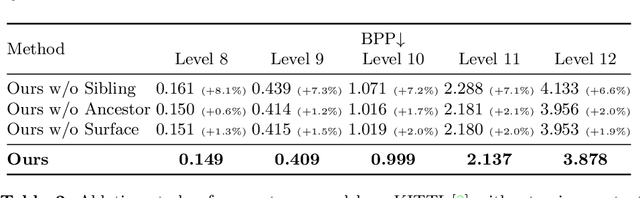
We present a novel octree-based multi-level framework for large-scale point cloud compression, which can organize sparse and unstructured point clouds in a memory-efficient way. In this framework, we propose a new entropy model that explores the hierarchical dependency in an octree using the context of siblings' children, ancestors, and neighbors to encode the occupancy information of each non-leaf octree node into a bitstream. Moreover, we locally fit quadratic surfaces with a voxel-based geometry-aware module to provide geometric priors in entropy encoding. These strong priors empower our entropy framework to encode the octree into a more compact bitstream. In the decoding stage, we apply a two-step heuristic strategy to restore point clouds with better reconstruction quality. The quantitative evaluation shows that our method outperforms state-of-the-art baselines with a bitrate improvement of 11-16% and 12-14% on the KITTI Odometry and nuScenes datasets, respectively.
Carl-Lead: Lidar-based End-to-End Autonomous Driving with Contrastive Deep Reinforcement Learning
Sep 17, 2021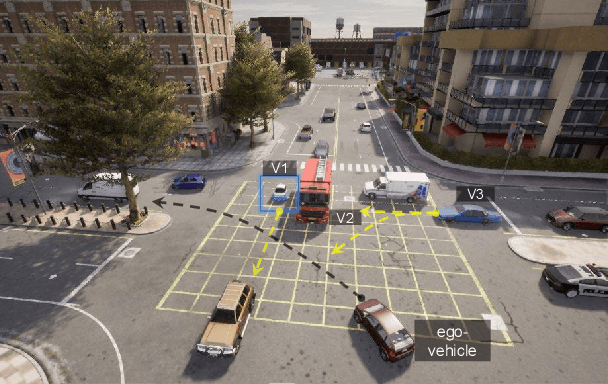
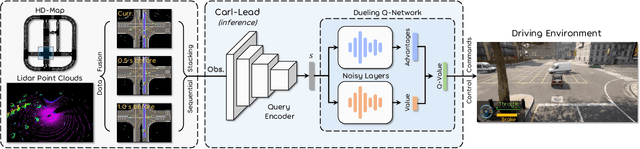
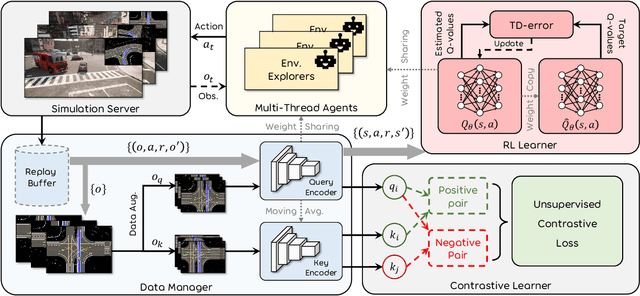
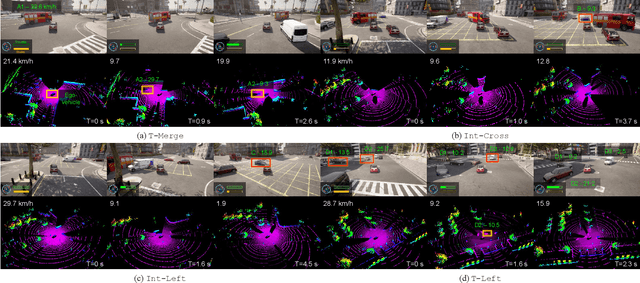
Autonomous driving in urban crowds at unregulated intersections is challenging, where dynamic occlusions and uncertain behaviors of other vehicles should be carefully considered. Traditional methods are heuristic and based on hand-engineered rules and parameters, but scale poorly in new situations. Therefore, they require high labor cost to design and maintain rules in all foreseeable scenarios. Recently, deep reinforcement learning (DRL) has shown promising results in urban driving scenarios. However, DRL is known to be sample inefficient, and most previous works assume perfect observations such as ground-truth locations and motions of vehicles without considering noises and occlusions, which might be a too strong assumption for policy deployment. In this work, we use DRL to train lidar-based end-to-end driving policies that naturally consider imperfect partial observations. We further use unsupervised contrastive representation learning as an auxiliary task to improve the sample efficiency. The comparative evaluation results reveal that our method achieves higher success rates than the state-of-the-art (SOTA) lidar-based end-to-end driving network, better trades off safety and efficiency than the carefully tuned rule-based method, and generalizes better to new scenarios than the baselines. Demo videos are available at https://caipeide.github.io/carl-lead/.
R-PCC: A Baseline for Range Image-based Point Cloud Compression
Sep 16, 2021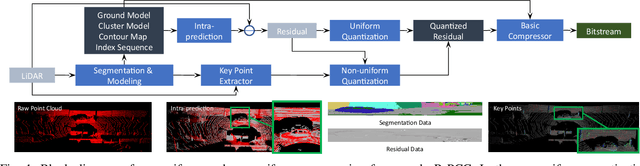
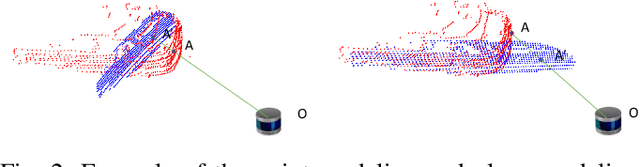

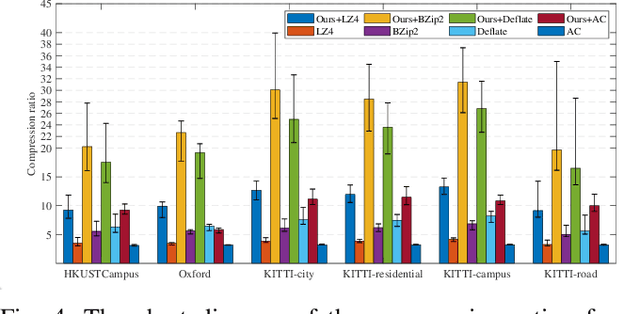
In autonomous vehicles or robots, point clouds from LiDAR can provide accurate depth information of objects compared with 2D images, but they also suffer a large volume of data, which is inconvenient for data storage or transmission. In this paper, we propose a Range image-based Point Cloud Compression method, R-PCC, which can reconstruct the point cloud with uniform or non-uniform accuracy loss. We segment the original large-scale point cloud into small and compact regions for spatial redundancy and salient region classification. Compared with other voxel-based or image-based compression methods, our method can keep and align all points from the original point cloud in the reconstructed point cloud. It can also control the maximum reconstruction error for each point through a quantization module. In the experiments, we prove that our easier FPS-based segmentation method can achieve better performance than instance-based segmentation methods such as DBSCAN. To verify the advantages of our proposed method, we evaluate the reconstruction quality and fidelity for 3D object detection and SLAM, as the downstream tasks. The experimental results show that our elegant framework can achieve 30$\times$ compression ratio without affecting downstream tasks, and our non-uniform compression framework shows a great improvement on the downstream tasks compared with the state-of-the-art large-scale point cloud compression methods. Our real-time method is efficient and effective enough to act as a baseline for range image-based point cloud compression. The code is available on https://github.com/StevenWang30/R-PCC.git.
Probabilistic End-to-End Vehicle Navigation in Complex Dynamic Environments with Multimodal Sensor Fusion
May 05, 2020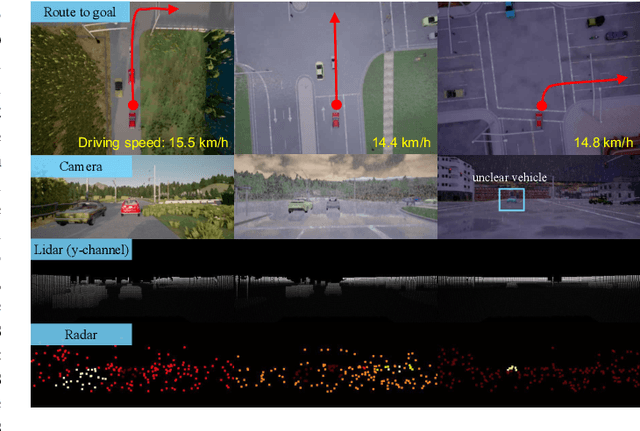


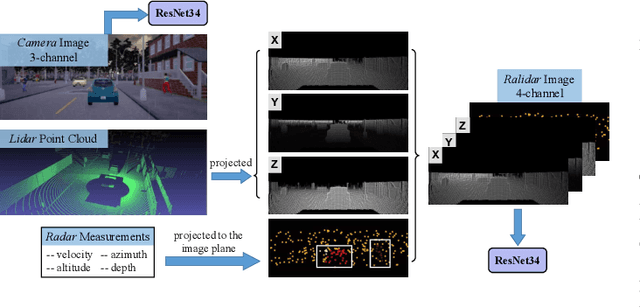
All-day and all-weather navigation is a critical capability for autonomous driving, which requires proper reaction to varied environmental conditions and complex agent behaviors. Recently, with the rise of deep learning, end-to-end control for autonomous vehicles has been well studied. However, most works are solely based on visual information, which can be degraded by challenging illumination conditions such as dim light or total darkness. In addition, they usually generate and apply deterministic control commands without considering the uncertainties in the future. In this paper, based on imitation learning, we propose a probabilistic driving model with ultiperception capability utilizing the information from the camera, lidar and radar. We further evaluate its driving performance online on our new driving benchmark, which includes various environmental conditions (e.g., urban and rural areas, traffic densities, weather and times of the day) and dynamic obstacles (e.g., vehicles, pedestrians, motorcyclists and bicyclists). The results suggest that our proposed model outperforms baselines and achieves excellent generalization performance in unseen environments with heavy traffic and extreme weather.
Hercules: An Autonomous Logistic Vehicle for Contact-less Goods Transportation During the COVID-19 Outbreak
Apr 16, 2020
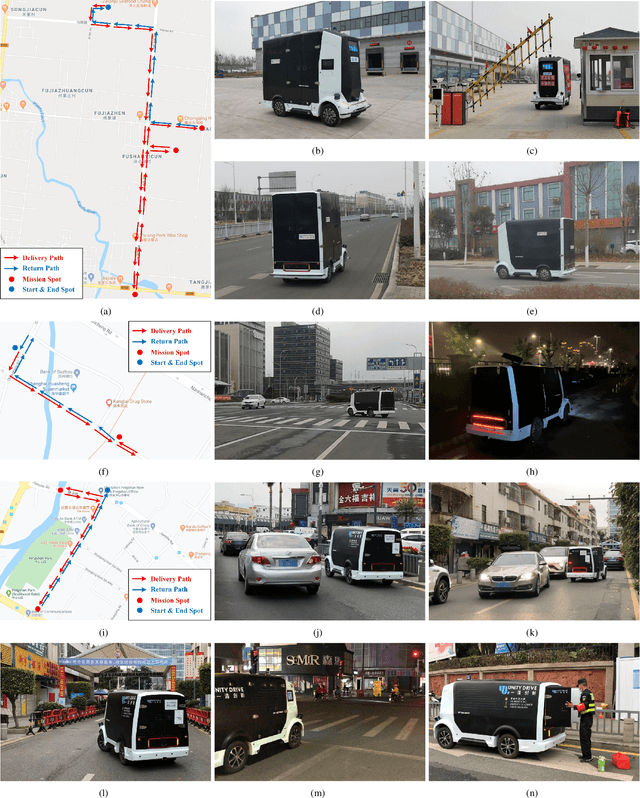
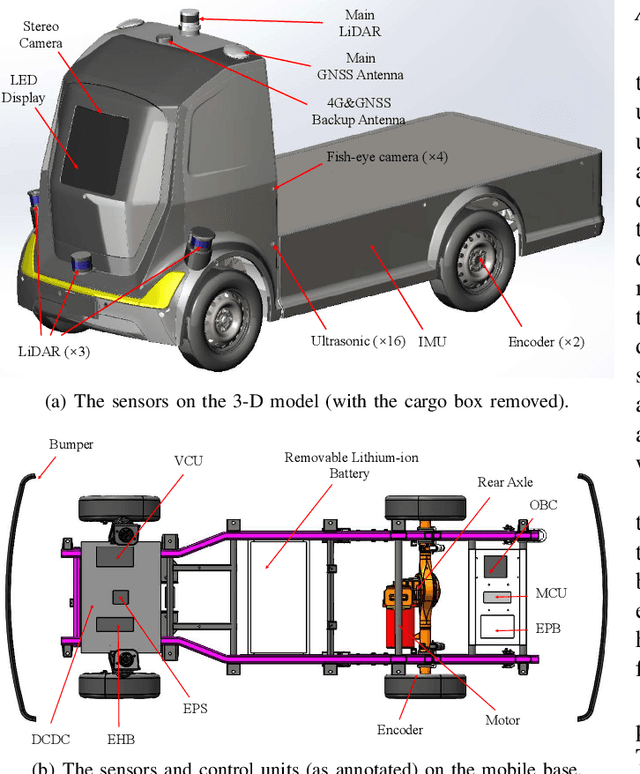
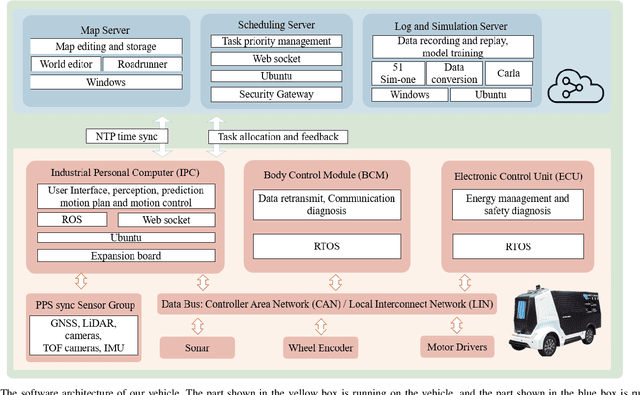
Since December 2019, the coronavirus disease 2019 (COVID-19) has spread rapidly across China. As at the date of writing this article, the disease has been globally reported in 100 countries, infected over 100,000 people and caused over 3,000 deaths. Avoiding person-to-person transmission is an effective approach to control and prevent the epidemic. However, many daily activities, such as logistics transporting goods in our daily life, inevitably involve person-to-person contact. To achieve contact-less goods transportation, using an autonomous logistic vehicle has become the preferred choice. This article presents Hercules, an autonomous logistic vehicle used for contact-less goods transportation during the outbreak of COVID-19. The vehicle is designed with autonomous navigation capability. We provide details on the hardware and software, as well as the algorithms to achieve autonomous navigation including perception, planning and control. This paper is accompanied by a demonstration video and a dataset, which are available here: https://sites.google.com/view/contact-less-transportation.
PointTrackNet: An End-to-End Network For 3-D Object Detection and Tracking From Point Clouds
Feb 26, 2020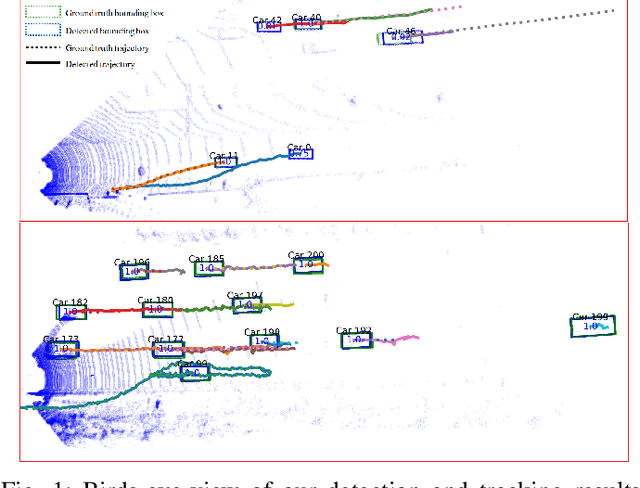
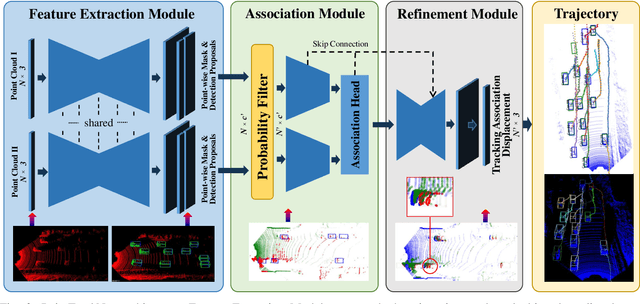
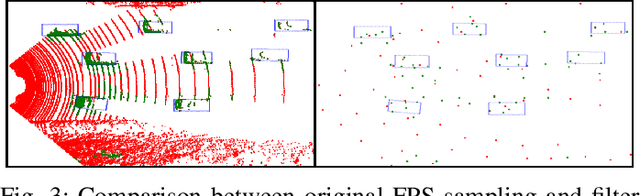
Recent machine learning-based multi-object tracking (MOT) frameworks are becoming popular for 3-D point clouds. Most traditional tracking approaches use filters (e.g., Kalman filter or particle filter) to predict object locations in a time sequence, however, they are vulnerable to extreme motion conditions, such as sudden braking and turning. In this letter, we propose PointTrackNet, an end-to-end 3-D object detection and tracking network, to generate foreground masks, 3-D bounding boxes, and point-wise tracking association displacements for each detected object. The network merely takes as input two adjacent point-cloud frames. Experimental results on the KITTI tracking dataset show competitive results over the state-of-the-arts, especially in the irregularly and rapidly changing scenarios.