 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLighting Every Darkness in Two Pairs: A Calibration-Free Pipeline for RAW Denoising
Aug 07, 2023Calibration-based methods have dominated RAW image denoising under extremely low-light environments. However, these methods suffer from several main deficiencies: 1) the calibration procedure is laborious and time-consuming, 2) denoisers for different cameras are difficult to transfer, and 3) the discrepancy between synthetic noise and real noise is enlarged by high digital gain. To overcome the above shortcomings, we propose a calibration-free pipeline for Lighting Every Drakness (LED), regardless of the digital gain or camera sensor. Instead of calibrating the noise parameters and training repeatedly, our method could adapt to a target camera only with few-shot paired data and fine-tuning. In addition, well-designed structural modification during both stages alleviates the domain gap between synthetic and real noise without any extra computational cost. With 2 pairs for each additional digital gain (in total 6 pairs) and 0.5% iterations, our method achieves superior performance over other calibration-based methods. Our code is available at https://github.com/Srameo/LED .
AMT: All-Pairs Multi-Field Transforms for Efficient Frame Interpolation
Apr 19, 2023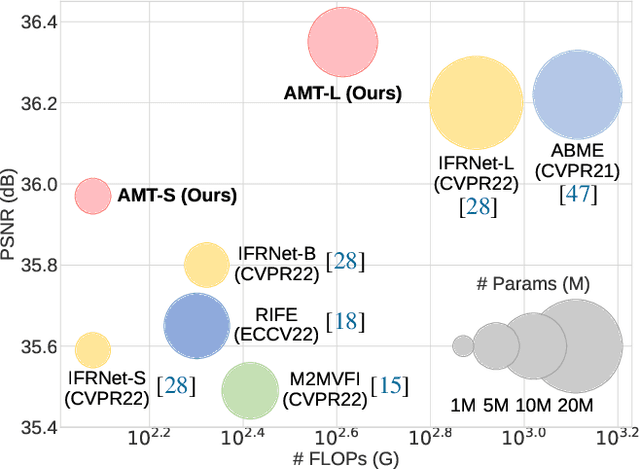
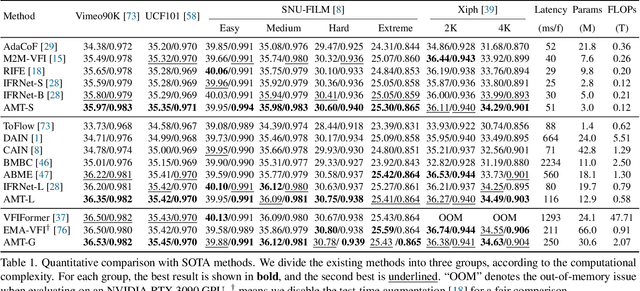

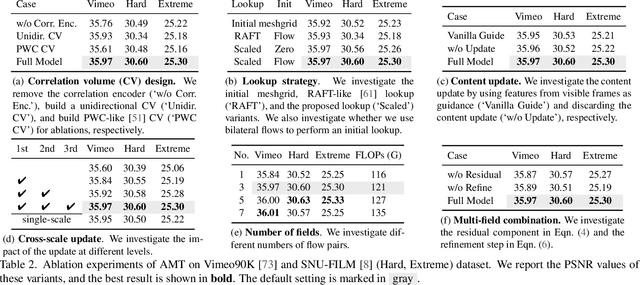
We present All-Pairs Multi-Field Transforms (AMT), a new network architecture for video frame interpolation. It is based on two essential designs. First, we build bidirectional correlation volumes for all pairs of pixels, and use the predicted bilateral flows to retrieve correlations for updating both flows and the interpolated content feature. Second, we derive multiple groups of fine-grained flow fields from one pair of updated coarse flows for performing backward warping on the input frames separately. Combining these two designs enables us to generate promising task-oriented flows and reduce the difficulties in modeling large motions and handling occluded areas during frame interpolation. These qualities promote our model to achieve state-of-the-art performance on various benchmarks with high efficiency. Moreover, our convolution-based model competes favorably compared to Transformer-based models in terms of accuracy and efficiency. Our code is available at https://github.com/MCG-NKU/AMT.
Deeply Explain CNN via Hierarchical Decomposition
Jan 23, 2022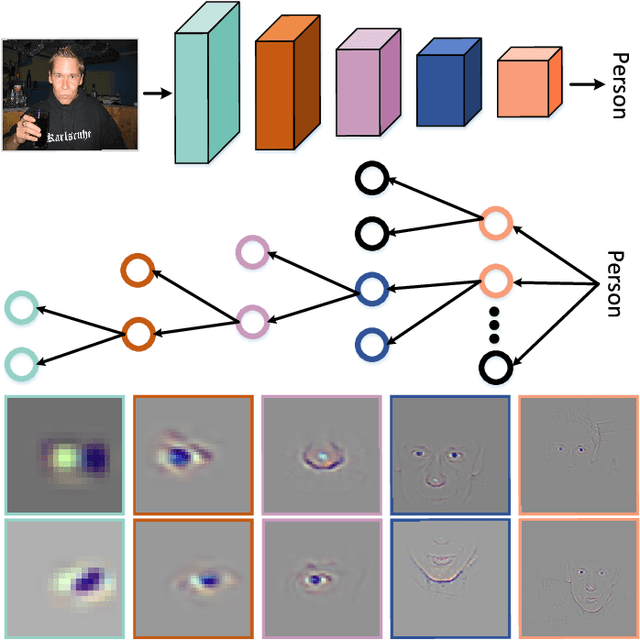
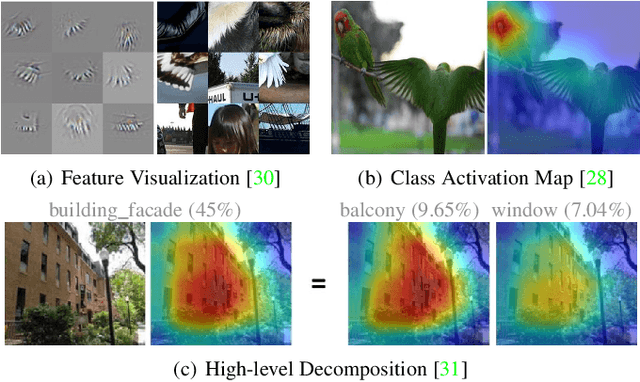
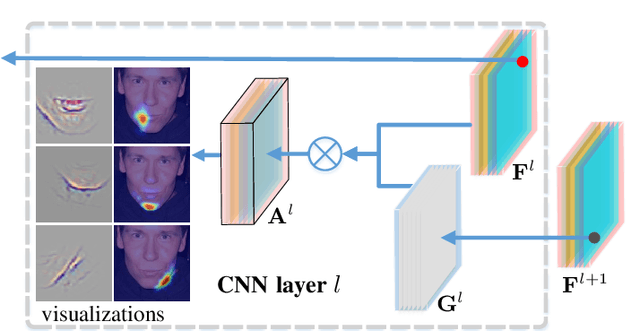
In computer vision, some attribution methods for explaining CNNs attempt to study how the intermediate features affect the network prediction. However, they usually ignore the feature hierarchies among the intermediate features. This paper introduces a hierarchical decomposition framework to explain CNN's decision-making process in a top-down manner. Specifically, we propose a gradient-based activation propagation (gAP) module that can decompose any intermediate CNN decision to its lower layers and find the supporting features. Then we utilize the gAP module to iteratively decompose the network decision to the supporting evidence from different CNN layers. The proposed framework can generate a deep hierarchy of strongly associated supporting evidence for the network decision, which provides insight into the decision-making process. Moreover, gAP is effort-free for understanding CNN-based models without network architecture modification and extra training process. Experiments show the effectiveness of the proposed method. The code and interactive demo website will be made publicly available.