 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskDiffusion: Boosting Text-to-Image Consistency with Conditional Mask
Sep 08, 2023



Recent advancements in diffusion models have showcased their impressive capacity to generate visually striking images. Nevertheless, ensuring a close match between the generated image and the given prompt remains a persistent challenge. In this work, we identify that a crucial factor leading to the text-image mismatch issue is the inadequate cross-modality relation learning between the prompt and the output image. To better align the prompt and image content, we advance the cross-attention with an adaptive mask, which is conditioned on the attention maps and the prompt embeddings, to dynamically adjust the contribution of each text token to the image features. This mechanism explicitly diminishes the ambiguity in semantic information embedding from the text encoder, leading to a boost of text-to-image consistency in the synthesized images. Our method, termed MaskDiffusion, is training-free and hot-pluggable for popular pre-trained diffusion models. When applied to the latent diffusion models, our MaskDiffusion can significantly improve the text-to-image consistency with negligible computation overhead compared to the original diffusion models.
AMT: All-Pairs Multi-Field Transforms for Efficient Frame Interpolation
Apr 19, 2023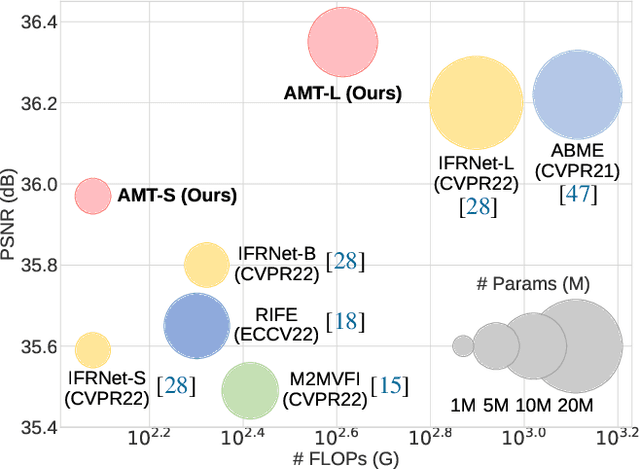
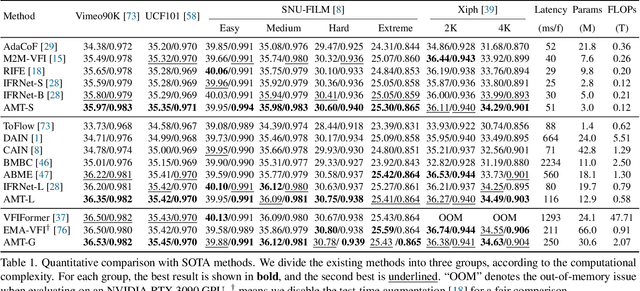

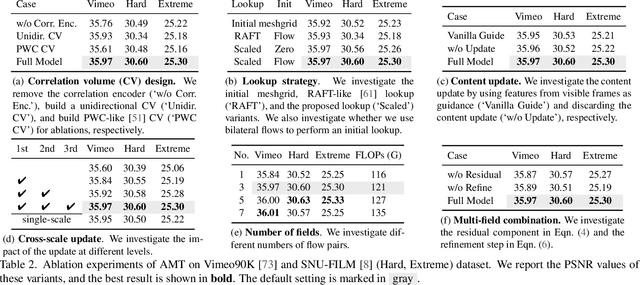
We present All-Pairs Multi-Field Transforms (AMT), a new network architecture for video frame interpolation. It is based on two essential designs. First, we build bidirectional correlation volumes for all pairs of pixels, and use the predicted bilateral flows to retrieve correlations for updating both flows and the interpolated content feature. Second, we derive multiple groups of fine-grained flow fields from one pair of updated coarse flows for performing backward warping on the input frames separately. Combining these two designs enables us to generate promising task-oriented flows and reduce the difficulties in modeling large motions and handling occluded areas during frame interpolation. These qualities promote our model to achieve state-of-the-art performance on various benchmarks with high efficiency. Moreover, our convolution-based model competes favorably compared to Transformer-based models in terms of accuracy and efficiency. Our code is available at https://github.com/MCG-NKU/AMT.
Designing An Illumination-Aware Network for Deep Image Relighting
Jul 21, 2022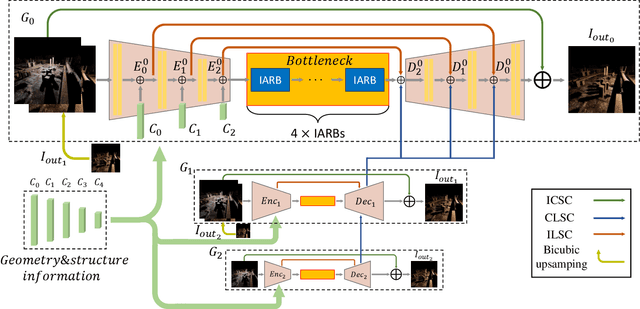



Lighting is a determining factor in photography that affects the style, expression of emotion, and even quality of images. Creating or finding satisfying lighting conditions, in reality, is laborious and time-consuming, so it is of great value to develop a technology to manipulate illumination in an image as post-processing. Although previous works have explored techniques based on the physical viewpoint for relighting images, extensive supervisions and prior knowledge are necessary to generate reasonable images, restricting the generalization ability of these works. In contrast, we take the viewpoint of image-to-image translation and implicitly merge ideas of the conventional physical viewpoint. In this paper, we present an Illumination-Aware Network (IAN) which follows the guidance from hierarchical sampling to progressively relight a scene from a single image with high efficiency. In addition, an Illumination-Aware Residual Block (IARB) is designed to approximate the physical rendering process and to extract precise descriptors of light sources for further manipulations. We also introduce a depth-guided geometry encoder for acquiring valuable geometry- and structure-related representations once the depth information is available. Experimental results show that our proposed method produces better quantitative and qualitative relighting results than previous state-of-the-art methods. The code and models are publicly available on https://github.com/NK-CS-ZZL/IAN.