 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond PID Controllers: PPO with Neuralized PID Policy for Proton Beam Intensity Control in Mu2e
Dec 28, 2023
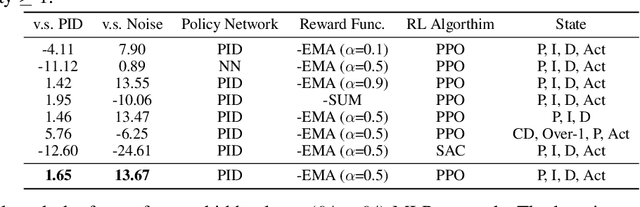
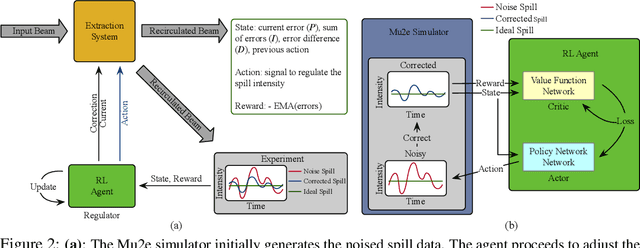

We introduce a novel Proximal Policy Optimization (PPO) algorithm aimed at addressing the challenge of maintaining a uniform proton beam intensity delivery in the Muon to Electron Conversion Experiment (Mu2e) at Fermi National Accelerator Laboratory (Fermilab). Our primary objective is to regulate the spill process to ensure a consistent intensity profile, with the ultimate goal of creating an automated controller capable of providing real-time feedback and calibration of the Spill Regulation System (SRS) parameters on a millisecond timescale. We treat the Mu2e accelerator system as a Markov Decision Process suitable for Reinforcement Learning (RL), utilizing PPO to reduce bias and enhance training stability. A key innovation in our approach is the integration of a neuralized Proportional-Integral-Derivative (PID) controller into the policy function, resulting in a significant improvement in the Spill Duty Factor (SDF) by 13.6%, surpassing the performance of the current PID controller baseline by an additional 1.6%. This paper presents the preliminary offline results based on a differentiable simulator of the Mu2e accelerator. It paves the groundwork for real-time implementations and applications, representing a crucial step towards automated proton beam intensity control for the Mu2e experiment.