 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogicNets: Co-Designed Neural Networks and Circuits for Extreme-Throughput Applications
Paper and Code
Apr 06, 2020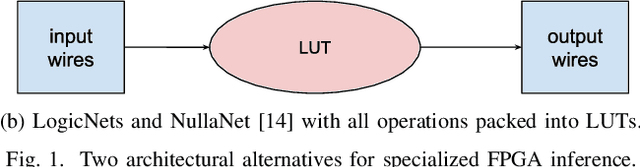

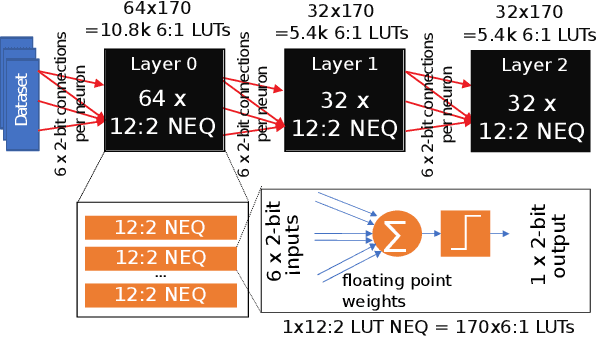
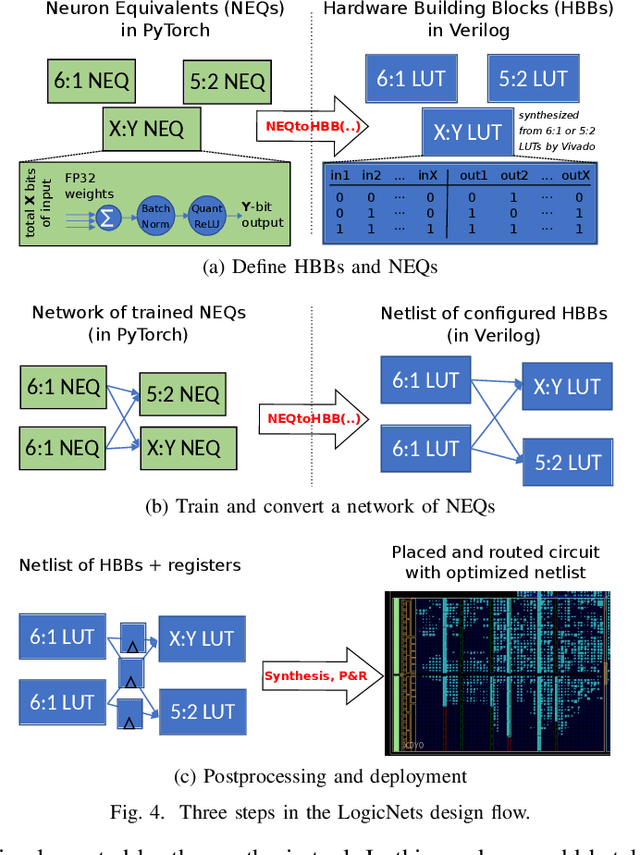
Deployment of deep neural networks for applications that require very high throughput or extremely low latency is a severe computational challenge, further exacerbated by inefficiencies in mapping the computation to hardware. We present a novel method for designing neural network topologies that directly map to a highly efficient FPGA implementation. By exploiting the equivalence of artificial neurons with quantized inputs/outputs and truth tables, we can train quantized neural networks that can be directly converted to a netlist of truth tables, and subsequently deployed as a highly pipelinable, massively parallel FPGA circuit. However, the neural network topology requires careful consideration since the hardware cost of truth tables grows exponentially with neuron fan-in. To obtain smaller networks where the whole netlist can be placed-and-routed onto a single FPGA, we derive a fan-in driven hardware cost model to guide topology design, and combine high sparsity with low-bit activation quantization to limit the neuron fan-in. We evaluate our approach on two tasks with very high intrinsic throughput requirements in high-energy physics and network intrusion detection. We show that the combination of sparsity and low-bit activation quantization results in high-speed circuits with small logic depth and low LUT cost, demonstrating competitive accuracy with less than 15 ns of inference latency and throughput in the hundreds of millions of inferences per second.